简单易学的机器学习算法——基于密度的聚类算法DBSCAN
一、基于密度的聚类算法的概述
二、DBSCAN算法的原理
1、基本概念
- 核心点。在半径Eps内含有超过MinPts数目的点
- 边界点。在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内
- 噪音点。既不是核心点也不是边界点的点
在这里有两个量,一个是半径Eps,另一个是指定的数目MinPts。
- Eps邻域。简单来讲就是与点
的距离小于等于Eps的所有的点的集合,可以表示为
。
- 直接密度可达。如果
的Eps邻域内,则称对象
- 密度可达。对于对象链:
,
是从
关于Eps和MinPts直接密度可达的,则对象
是从对象
关于Eps和MinPts密度可达的。
2、算法流程

三、实验仿真


- %% DBSCAN
- clear all;
- clc;
- %% 导入数据集
- % data = load('testData.txt');
- data = load('testData_2.txt');
- % 定义参数Eps和MinPts
- MinPts = 5;
- Eps = epsilon(data, MinPts);
- [m,n] = size(data);%得到数据的大小
- x = [(1:m)' data];
- [m,n] = size(x);%重新计算数据集的大小
- types = zeros(1,m);%用于区分核心点1,边界点0和噪音点-1
- dealed = zeros(m,1);%用于判断该点是否处理过,0表示未处理过
- dis = calDistance(x(:,2:n));
- number = 1;%用于标记类
- %% 对每一个点进行处理
- for i = 1:m
- %找到未处理的点
- if dealed(i) == 0
- xTemp = x(i,:);
- D = dis(i,:);%取得第i个点到其他所有点的距离
- ind = find(D<=Eps);%找到半径Eps内的所有点
- %% 区分点的类型
- %边界点
- if length(ind) > 1 && length(ind) < MinPts+1
- types(i) = 0;
- class(i) = 0;
- end
- %噪音点
- if length(ind) == 1
- types(i) = -1;
- class(i) = -1;
- dealed(i) = 1;
- end
- %核心点(此处是关键步骤)
- if length(ind) >= MinPts+1
- types(xTemp(1,1)) = 1;
- class(ind) = number;
- % 判断核心点是否密度可达
- while ~isempty(ind)
- yTemp = x(ind(1),:);
- dealed(ind(1)) = 1;
- ind(1) = [];
- D = dis(yTemp(1,1),:);%找到与ind(1)之间的距离
- ind_1 = find(D<=Eps);
- if length(ind_1)>1%处理非噪音点
- class(ind_1) = number;
- if length(ind_1) >= MinPts+1
- types(yTemp(1,1)) = 1;
- else
- types(yTemp(1,1)) = 0;
- end
- for j=1:length(ind_1)
- if dealed(ind_1(j)) == 0
- dealed(ind_1(j)) = 1;
- ind=[ind ind_1(j)];
- class(ind_1(j))=number;
- end
- end
- end
- end
- number = number + 1;
- end
- end
- end
- % 最后处理所有未分类的点为噪音点
- ind_2 = find(class==0);
- class(ind_2) = -1;
- types(ind_2) = -1;
- %% 画出最终的聚类图
- hold on
- for i = 1:m
- if class(i) == -1
- plot(data(i,1),data(i,2),'.r');
- elseif class(i) == 1
- if types(i) == 1
- plot(data(i,1),data(i,2),'+b');
- else
- plot(data(i,1),data(i,2),'.b');
- end
- elseif class(i) == 2
- if types(i) == 1
- plot(data(i,1),data(i,2),'+g');
- else
- plot(data(i,1),data(i,2),'.g');
- end
- elseif class(i) == 3
- if types(i) == 1
- plot(data(i,1),data(i,2),'+c');
- else
- plot(data(i,1),data(i,2),'.c');
- end
- else
- if types(i) == 1
- plot(data(i,1),data(i,2),'+k');
- else
- plot(data(i,1),data(i,2),'.k');
- end
- end
- end
- hold off
- %% 计算矩阵中点与点之间的距离
- function [ dis ] = calDistance( x )
- [m,n] = size(x);
- dis = zeros(m,m);
- for i = 1:m
- for j = i:m
- %计算点i和点j之间的欧式距离
- tmp =0;
- for k = 1:n
- tmp = tmp+(x(i,k)-x(j,k)).^2;
- end
- dis(i,j) = sqrt(tmp);
- dis(j,i) = dis(i,j);
- end
- end
- end
epsilon函数
- function [Eps]=epsilon(x,k)
- % Function: [Eps]=epsilon(x,k)
- %
- % Aim:
- % Analytical way of estimating neighborhood radius for DBSCAN
- %
- % Input:
- % x - data matrix (m,n); m-objects, n-variables
- % k - number of objects in a neighborhood of an object
- % (minimal number of objects considered as a cluster)
- [m,n]=size(x);
- Eps=((prod(max(x)-min(x))*k*gamma(.5*n+1))/(m*sqrt(pi.^n))).^(1/n);
最终的结果
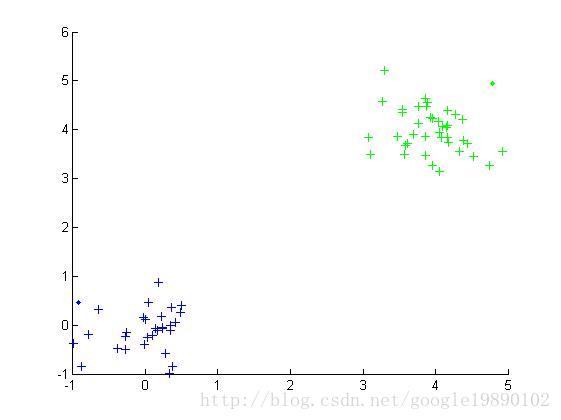
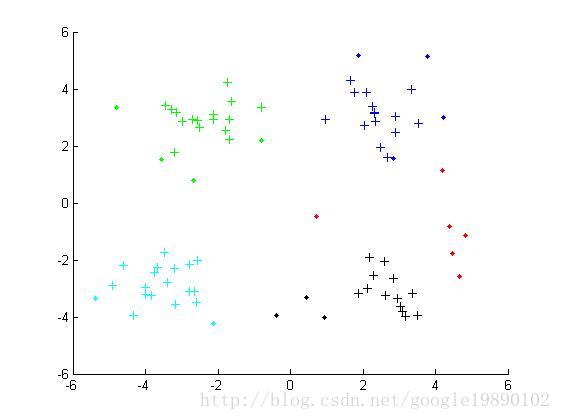
参考文献
[2] M. Daszykowski, B. Walczak, D. L. Massart, Looking for Natural Patterns in Data. Part 1: Density Based Approach
简单易学的机器学习算法——基于密度的聚类算法DBSCAN的更多相关文章
- 简单易学的机器学习算法—基于密度的聚类算法DBSCAN
简单易学的机器学习算法-基于密度的聚类算法DBSCAN 一.基于密度的聚类算法的概述 我想了解下基于密度的聚类算法,熟悉下基于密度的聚类算法与基于距离的聚类算法,如K-Means算法之间的区别. ...
- 【机器学习】DBSCAN Algorithms基于密度的聚类算法
一.算法思想: DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法.与划分和层 ...
- 基于密度的聚类之Dbscan算法
一.算法概述 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法.与划分和层次 ...
- DBSCAN聚类︱scikit-learn中一种基于密度的聚类方式
一.DBSCAN聚类概述 基于密度的方法的特点是不依赖于距离,而是依赖于密度,从而克服基于距离的算法只能发现"球形"聚簇的缺点. DBSCAN的核心思想是从某个核心点出发,不断向密 ...
- 简单易学的机器学习算法——EM算法
简单易学的机器学习算法——EM算法 一.机器学习中的参数估计问题 在前面的博文中,如“简单易学的机器学习算法——Logistic回归”中,采用了极大似然函数对其模型中的参数进行估计,简单来讲即对于一系 ...
- 简单易学的机器学习算法—SVD奇异值分解
简单易学的机器学习算法-SVD奇异值分解 一.SVD奇异值分解的定义 假设M是一个的矩阵,如果存在一个分解: 其中的酉矩阵,的半正定对角矩阵,的共轭转置矩阵,且为的酉矩阵.这样的分解称为M的奇 ...
- 聚类:层次聚类、基于划分的聚类(k-means)、基于密度的聚类、基于模型的聚类
一.层次聚类 1.层次聚类的原理及分类 1)层次法(Hierarchicalmethods)先计算样本之间的距离.每次将距离最近的点合并到同一个类.然后,再计算类与类之间的距离,将距离最近的类合并为一 ...
- SIGAI机器学习第二十四集 聚类算法1
讲授聚类算法的基本概念,算法的分类,层次聚类,K均值算法,EM算法,DBSCAN算法,OPTICS算法,mean shift算法,谱聚类算法,实际应用. 大纲: 聚类问题简介聚类算法的分类层次聚类算法 ...
- 密度峰值聚类算法(DPC)
密度峰值聚类算法(DPC) 凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 1. 简介 基于密度峰值的聚类算法全称为基于快速搜索和发现密度峰值的聚类算法(cl ...
随机推荐
- PHP 统计数组中所有的值出现的次数 array_count_values 函数
array_count_values() 函数用于统计数组中所有的值出现的次数. array_count_values() PHP array_count_values() 函数用于统计数组中所有的值 ...
- 初识OpenCV-Python - 009: 图像梯度
本节学习找到图像的梯度和边界.只要用到的函数为: cv2.Sobel(), cv2.Scharr(), cv2.Laplacian() 1. Laplacian 和 Sobel的对比 import c ...
- JS完美运动框架【利用了Json】
<!doctype html> <html> <head> <meta charset="utf-8"> <title> ...
- Qt---坐标系统
Qt中经常会访问鼠标的位置,qt中将坐标分为局部坐标,与全局坐标.局部坐标用pos表示,全局坐标用globalPos表示. pos与globalPos区别: globalPos:widget鼠标所在位 ...
- loj2513 治疗之雨
题意:你的英雄一开始血量为p,你还有m个队友,血量无穷.血量上限为n,下限为0.如果血量满了就不能加血.每次启动操作,随机给m+1个英雄加1点血,然后等概率随机k次每次对于英雄扣1点血.求期望操作几次 ...
- 2-sat——hdu3062
对于怎么建边还是不太清楚 选了a,那么b c不选,所以连边 选了b或c,那么a必定不选 /* 每个点拆成i*2,i*2+1 队长选,那么队友不选 队长不选,那么队友必定要选 */ #include&l ...
- LUOGU P1514 引水入城 (bfs)
传送门 解题思路 拉了很长的战线,换了好几种写法终于过了..首先每个蓄水场一定是对沙漠造成连续一段的贡献,所以可以$bfs$出每种状态,然后做一次最小区间覆盖,但这样的复杂度有点高.就每次只搜那些比左 ...
- windows环境下,svn未备份情况下重新恢复
公司有个同事在未打招呼的情况下把公司服务器进行重新装系统,崩溃啊.SVN之前未备份,还好SVN的库(Repositories)还在,如下图: 恢复办法如下: 由于之前安装的就是VisualSVN-Se ...
- android 头像选择以及裁剪
一.布局申明 <ImageView android:id="@+id/head_image" android:layout_width="80dp" an ...
- nginx 遇见问题与解决问题
如果你的安装目录为/usr/local/nginx,那么nginx的错误日志目录就是/usr/local/nginx/logs/error.log. 2.如果error.log不存在 就进入 # vi ...