海胜专访--MaxCompute 与大数据查询引擎的技术和故事
摘要:在2019大数据技术公开课第一季《技术人生专访》中,阿里巴巴云计算平台高级技术专家苑海胜为大家分享了《MaxCompute 与大数据查询引擎的技术和故事》,主要介绍了MaxCompute与MPP Database的异同点,分布式系统上Join的实现,且详细讲解了MaxCompute针对Join和聚合引入的Hash Clustering Table和Range Clustering Table的优化。
以下内容根据演讲视频以及PPT整理而成。
一、MaxCompute VS MPP Database
MaxCompute 与 MPP Database有非常大的不同,主要体现在性能(Performance)、成本(Cost)、可扩展性(Scalability)及灵活性(Flexibility)等度量纬度。
- 性能(Performance):作为一个数据仓库,大家首先关心的指标是性能。MPP Database典型的产品有Greenplum,Vertica和Redshift等,它们主要针对的在线实时数据的分析,性能要求一般是毫秒级别。而MaxCompute多数场景应用在离线数据下,MaxCompute需要动态的拉起进程和数据封装,如果进行MapReduce还涉及数据落地,所以离线数据的分析会比较慢,这也导致MaxCompute无法适用于实时场景。但在大量数据场景下,MaxCompute会展示出优势,它可以动态调整Instance数量,保证有足够多的Instance处理数据。 而MPP Database一旦开启了固定的Cluster和Node之后,数据量较大时会受到集群计算资源的限制。
- 成本(Cost):MaxCompute在cost层面占较大优势。首先,数据存储在阿里云上,计算部分也只需要为所付出的计算资源付费,不计算时只需为存储资源付费。而MPP Database一旦开启一定的资源,即使不使用也需要付费。
- 可扩展性(Scalability):阿里云在起初也使用过MPP Database,MPP Database刚开始就设定了固定的cluster,但是由于阿里云内部的业务数据在不断的增加,导致计算资源严重不足。MaxCompute可以动态分配资源,根据计算的复杂度实时调整Instance数量,保证较高的可扩展性。
- 灵活性(Flexibility):MaxCompute不仅可以处理SQL的查询,还可以处理MapReduce,以及能够查询Machine Learning节点。由于MaxCompute的高扩展性和灵活性,它可以支持阿里云内部95%的数据计算,承载的任务也非常多。
二、分布式系统上Join的实现
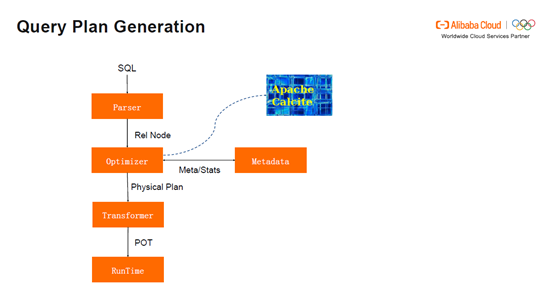
Query Plan Generation流程:首先用户会提交SQL给Parser,Parser将其编译成Relation节点,然后将Relation的节点交给优化器Optimizer,经过一系列的优化,其中包括根据物理转化和逻辑转化。Cost model从中选择代价最低的物理的执行计划。Transformer将最优的计划转成Physical Operator tree,并且将Physical Operator tree交给Manager。Manager启动实例,并交给RunTime执行此次query。这过程中,Cost model从Metadata中获取统计信息(如表的宽度和行数),来选择最优的计划,Apache Calcite被用来作用于Optimizer的框架。
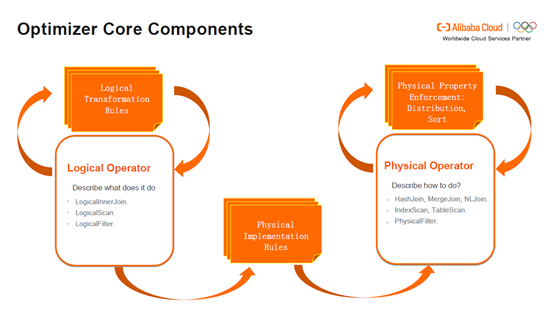
Optimizer Core Components:逻辑运算符(Logical Operator)主要描述要做哪些事情,如LogicalInnerJoin做InnerJoin, LogicalScan做扫描,LogicalFilter做过滤。物理运算符(Physical Operator)主要描述怎么做,如HashJoin,MergeJoin及NLJoin代表不同的算法,IndexScan表示索引扫描,TableScan是全标扫描,PhysicalFilter是物理过滤器。逻辑运算符(Logical Operator)可以通过Logical Transformation Rules转化为新的逻辑运算符,还可以通过Logical Implementation Rules转化成物理运算符,如从InnerJoin转化成HashJoin。另外,物理运算符(Physical Operator)可以通过属性的强化(Physical Property Enforcement)产生新的物理运算符(Physical Operator),如通过Distribution满足分布的属性,通过Sort满足排序的属性。
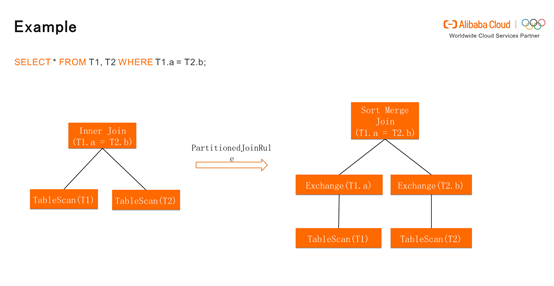
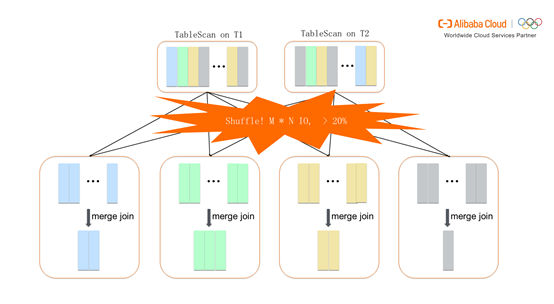
下图展示了MaxCompute如何生成一个Join Plan。首先,Inner Join通过PartitionedJoinRule产生物理的plan,既Sort Merge Join,它存在盘古系统中,不满足分布的属性,所以MaxCompute需要进行Exchange。
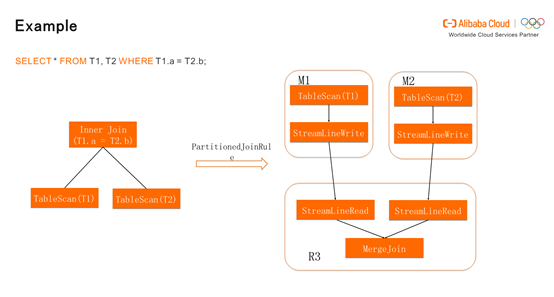
也就是按照T1.a和T2.b进行Shuffle,Shuffle之后进行Sort Merge。有相同T1.a的值和T2.b的值会分在同一个bucket中。不同的bucket启动多个Instance,每个Instance处理每个bucket,从而进行分布式计算。其中在Shuffle时占用了较多的资源,它不仅有数据的读写,还包括排序。如何尽量减少排序从而加快数据处理速度是优化的关键。
假设T1或T2较小,那么可以将T2的全表广播到T1进行Hash Join,好处是T1不需要多次Shuffle,T2也不需要进行Hash计算和排序。这时Join Plan只包含两个stage,M2 stage对T2进行扫描,之后广播到T1。T1不需要进行Shuffle,使用T2全表的数据建Hash表,再通过T1部分数据进行Hash Build,最后得到Hash Join的结果。
三、MaxCompute针对Join和聚合引入的Hash Clustering Table和Range Clustering的优化
1.Hash Clustering Table
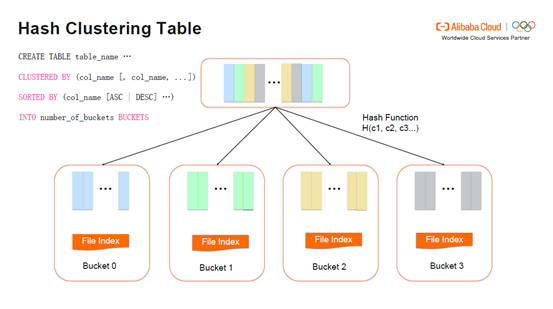
分布式系统上Join的实现会涉及非常多次的Shuffle,为此MaxCompute创建了Hash Clustering Table来实现优化。Hash Clustering Table对选择的column进行Hash,将不同的数据分配到不同的bucket里面,这也就说明在创建Hash Clustering Table时,已经进行了Shuffle和排序。基本语法如下图,clustered by 表明按照column进行Shuffle,sorted by 是按照column进行排序,number of buckets 推荐设置成2的n次方,方便与其它表进行Join。同时也推荐将clustered by和sorted by中的column设置为一样或者clustered by中的column包含sorted by中的column。因为Hash Clustering Table通常被用来做Join和Shuffle Remove,可以利用它已有的属性从而去除掉多余的Shuffle和排序,实现优化的目的。
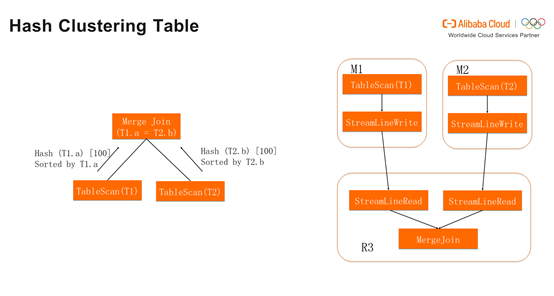
详细步骤如下图,Merge Join对T1发送请求,拉取T1的属性。假设T1为Hash Clustering Table,T1反馈是按照T1.a进行Hash,Hash到100个bucket,同时按照T1.a进行排序。T2同理。这时产生的Join Plan就满足了M1,M2和R3的排序,最后所有的operator只需一个stage(M1),不需要多余的Shuffle。
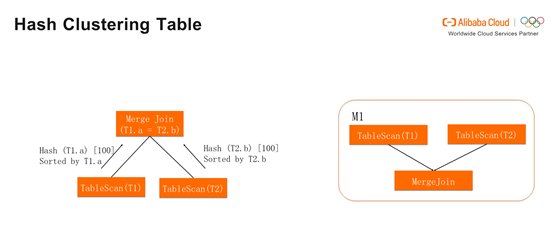
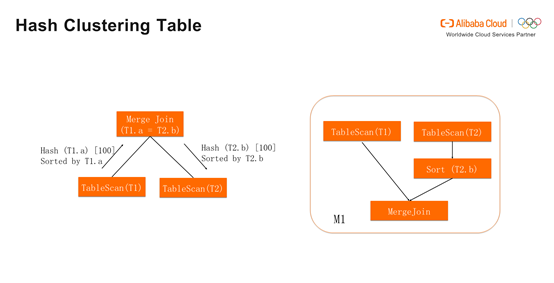
与之相反,T2的反馈如果是None,Merge Join会发送请求,使T2按照T2.b进行Hash和排序,设置100个bucket。这时产生的Join Plan包含M1和M2两个stage,T2需要Shuffle,T1则不需要Shuffle,消除了一个stage的Shuffle。
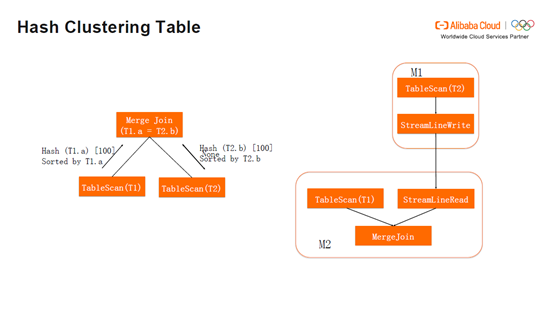
假如T2的反馈是按照T2.b进行Hash,Hash到100个bucket,但排序不是T2.b。那么Merge Join 依然请求T2按照T2.b排序。这时Join Plan还是仅仅会有M1一个stage,其中只是多了Sort Operator,但没有多余的Shuffle。
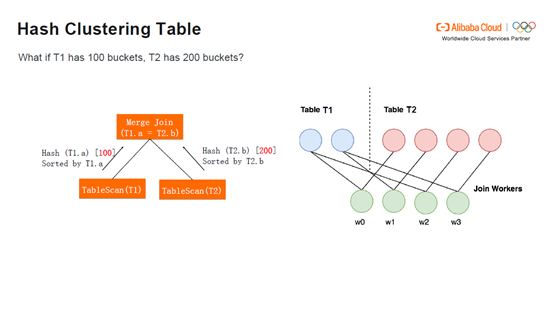
如果T2设置了200个bucket,T1的100个bucket会被读两遍,进行过滤,T1的1个bucket会对应T2的2个bucket。这时依然没有Shuffle。
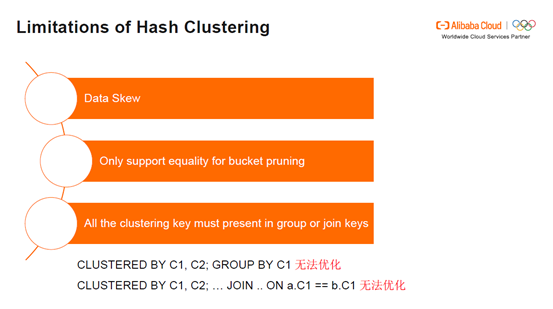
Hash Clustering Table的限制:Hash Clustering Table在Data Skew方面有明显的限制。当数据量非常大,将这些数据Hash到一个bucket中导致的后果便是拖慢整个cluster的计算速度。Hash Clustering Table只支持等值的bucket pruning,如果按照a分配bucket,a=5,对5获取Hash值,同时对Hash桶进行取模,那么Hash Clustering Table可以定位出a=5具体在哪个bucket中。但如果不等值,Hash Clustering Table便无法支持。Hash Clustering Table 要求所有的clustering key出现聚合key或者Join key中。在CLUSTERED BY C1, C2; GROUP BY C1情况下,Hash Clustering Table无法实现优化。同样,CLUSTERED BY C1, C2; … Join .. ON a.C1 == b.C1 也无法实现优化,Hash Clustering Table 要求Join key 包含C1和C2。
2.Range Clustering Table
Range Clustering Table 顾名思义,按照Range进行排序。MaxCompute自动的决定每个bucket的范围。
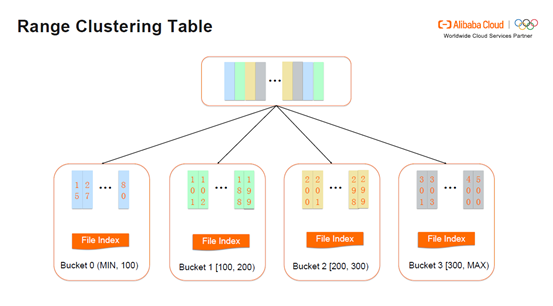
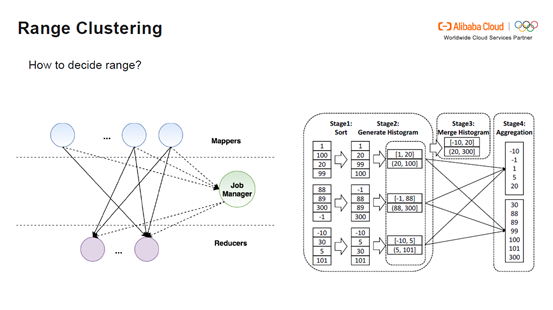
Range Clustering Table怎样确定bucket的范围?如下图,第一层是Mappers,中间是Job Manager,下一层是Reducers。首先在Stage1进行排序,之后从中抽取直方图,每个Worker将直方图发送给Job Manager。Job Manager合并直方图,根据数据量的大小决定合并成多少个bucket。Job Manager在将Bucket的范围再发送给Mappers,由Mappers决定每一条数据发送到具体哪个bucket。最后Reducers会得到具体的Aggregation Stage。
Range Clustering Table的优势非常明显,首先Range Clustering Table支持范围比较(Range Comparison)。 同时它可以支持在prefix keys上的聚合和Join,既在CLUSTERED BY C1, C2; GROUP BY C1 情况下,Range Clustering Table也可以支持优化。
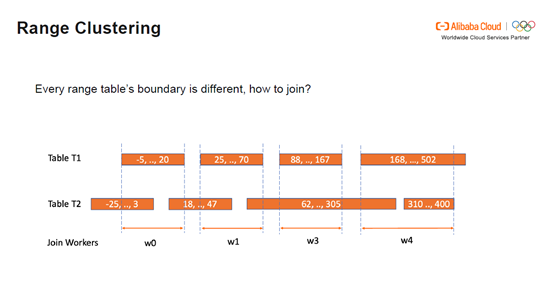
Range Clustering Table如何实现Join:假设T1和T2的Range如下图,因为范围不同无法直接Join。这时需要进行范围的切分,将切分后的范围交给Join Workers,由它读取新的范围。如下图,w0读取T1的切分范围,将T2表的不必要范围剔除。
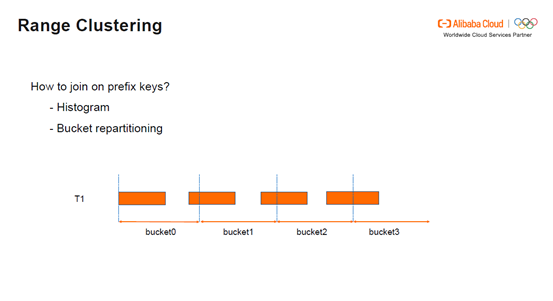
Range Clustering如何按照prefix keys进行Join:Join on prefix keys需要直方图和bucket的重新分配。假设按照a和b进行clustering,从直方图中可以知道a是从哪个地方切分的。对bucket重新分配之后可以更新bucket的范围,最后将新的bucket的范围发送给Join Worker
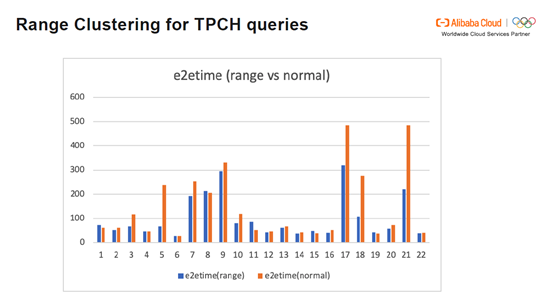
下图展示了在range表和normal表中TPCH的查询时间的对比。可以发现,速度总体上提升了60-70%,其中query 5, 17和21达到了数倍的速度的提升。
3.Tips for Clustering Table
如何选择正确的clustering keys,从而达到节省资源和降低速度的目的?下面有几点提示可以提供给大家。首先,如果有Join condition keys,Distinct values,Where condition keys(EQUAL/IN, GT/GE/LT/BETWEEN),那么可以针对这些已有的keys创建 Clustering Table。如果是Aggregate keys ,可以选择创建Range Clustering Table。对于 Window keys, 可以根据Partition keys和Order keys 创建clustering keys和sort keys。举例如下,SELECT row_number() OVER (PARTITION BY a ORDER BY b) FROM foo; 那么Optimizer执行Window时产生的plan是CLUSTERED BY a SORTED BY a,b INTO x BUCKETS,既按照a Shuffle,按照a和b进行排序。在一个bucket中a的值不可能都相同,与a不同的值可以认为是一个frame,在frame中还需要进行b排序,所以每个Instance是按照a和b进行排序。如此便省去了预先的计算,既不需要Shuffle也无需排序。

此外,需要注意即使两个Hash表是同样的分布,排序和bucket数量,但如果类型不同依然需要进行Shuffle,因为它们的binary表达方式不同,所以Hash的结果也会不同。另外,Clustering Table创建时耗费时间较长,假如创建Clustering Table之后并没有频繁查询,也会造成浪费。还需要注意Clustering Table尽量避免Data Skew。再一个,使用FULL OUTER Join增量更新时需要进行改写。

使用FULL OUTER Join进行增量更新: 如下图,分别是snapshot表和delta表,Join keys 是s.key和d.key,但在向新的partition插入表达式时无法判断新的SQL表达式是否满足数据的排序,所以还需要对数据进行再一次的Shuffle。下图中对SQL表达式进行了ANTI JOIN和 UNION ALL的改写,ANTI JOIN可以利用排序的属性,同时UNION ALL也是按照原来的key的分布和排序,如此就可以完全做到Shuffle Remove。

Clustering Table分区建议:创建Clustering Table时需要考虑分区的大小,太小的分区本身优化空间就不大反而可能引入小文件问题。假设设置1000个bucket就会生成1000个小文件,而这些小文件会对Mappers造成很大的压力。另外,分区读写比越高的表 cluster后可能得到的收益越大。由于创建Clustering Table耗时较多,那么读的频率较多就会有较大的优势。最后,字段利用率越高(列裁剪较少)的表,cluster后可能得到的收益越大。如果列裁剪之后使用到数据利用率较低,这表明浪费了较多的时间,所以cluster后的收益也不会很大。
本文作者:晋恒
本文为云栖社区原创内容,未经允许不得转载。
海胜专访--MaxCompute 与大数据查询引擎的技术和故事的更多相关文章
- Facebook 正式开源其大数据查询引擎 Presto
Facebook 正式宣布开源 Presto —— 数据查询引擎,可对250PB以上的数据进行快速地交互式分析.该项目始于 2012 年秋季开始开发,目前该项目已经在超过 1000 名 Faceboo ...
- 大数据系列之分布式大数据查询引擎Presto
关于presto部署及详细介绍请参考官方链接 http://prestodb-china.com PRESTO是什么? Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持G ...
- 比hive快10倍的大数据查询利器presto部署
目前最流行的大数据查询引擎非hive莫属,它是基于MR的类SQL查询工具,会把输入的查询SQL解释为MapReduce,能极大的降低使用大数据查询的门槛, 让一般的业务人员也可以直接对大数据进行查询. ...
- 揭秘阿里云EB级大数据计算引擎MaxCompute
日前,全球权威咨询与服务机构Forrester发布了<The Forrester WaveTM: Cloud Data Warehouse, Q4 2018>报告.这是Forrester ...
- SQL命令语句进行大数据查询如何进行优化
SQL 大数据查询如何进行优化? 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索 2.应尽量避免在 where 子句中对字段进行 null 值 ...
- mysql 5.7 innodb count count(*) count(1) 大数据 查询慢 耗时多 优化
原文:mysql 5.7 innodb count count(*) count(1) 大数据 查询慢 耗时多 优化 问题描述 mysql 5.7 innodb 引擎 使用以下几种方法进行统计效率差不 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- Apache Flink 为什么能够成为新一代大数据计算引擎?
众所周知,Apache Flink(以下简称 Flink)最早诞生于欧洲,2014 年由其创始团队捐赠给 Apache 基金会.如同其他诞生之初的项目,它新鲜,它开源,它适应了快速转的世界中更重视的速 ...
- 网易大数据平台的Spark技术实践
网易大数据平台的Spark技术实践 作者 王健宗 网易的实时计算需求 对于大多数的大数据而言,实时性是其所应具备的重要属性,信息的到达和获取应满足实时性的要求,而信息的价值需在其到达那刻展现才能利益最 ...
随机推荐
- 实现一个koa-logger中间件
//koa-logger.js module.exports = async(ctx,next)=>{ const start = new Date().getTime() // 中间件异步处理 ...
- 常见的5个runtime exception
NullPointException(空指针异常),ArrIndexOutOfBoundsException(数组越界异常),ClassCastException(类型转换异常),ClassNotFo ...
- JS实现数据双向绑定
本文参考https://www.cnblogs.com/tianhaining/p/8425345.html 首先先说个面试题哈,就是vue中的v-model是如何实现双向数据绑定的咳咳,下面开始背诵 ...
- 软件-MQ-RabbitMQ:RabbitMQ
ylbtech-软件-MQ-RabbitMQ:RabbitMQ RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件).RabbitMQ服务器是用Erlang语 ...
- 【Redis安装】部署与基本配置 --基于Mac和Linux
Redis安装与部署[基于Mac和Linux] 一.Redis简介 基于内存的Key-Value高性能NoSQL数据库 二.Redis下载和解压 进入官网下载最新版的Redis,目前是5.0.0,这个 ...
- Django--Cookie和Session组件
什么是Cookie: cookie的工作原理是:由服务端产生内容,浏览器收到请求之后保存在本地:当浏览器再次访问的时候,浏览器会自动带上这个cookie,这样服务端就能去通过这个cookie来判断你是 ...
- Web Service和WCF的区别
[1]Web Service:严格来说是行业标准,也就是Web Service 规范,也称作WS-*规范,既不是框架,也不是技术. 它有一套完成的规范体系标准,而且在持续不断的更新完善中. 它使用XM ...
- UVAL3700
Interesting Yang Hui Triangle 题目大意:杨辉三角第n + 1行不能整除p(p是质数)的数的个数 题解: lucas定理C(n,m) = πC(ni,mi) (mod p) ...
- Javascript-简单的倒计时跳转页面
<!DOCTYPE html> <html lang="en" xmlns="http://www.w3.org/1999/xhtml"> ...
- div 无缝滚动
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3c.org ...