Python多线程在爬虫中的应用
题记:作为测试工程师经常需要解决测试数据来源的问题,解决思路无非是三种:(1)直接从生产环境拷贝真实数据 (2)从互联网上爬取数据 (3)自己用脚本或者工具造数据。前段时间,为了获取更多的测试数据,笔者就做了一个从互联网上爬取数据的爬虫程序,虽然功能上基本满足项目的需求,但是爬取的效率还是不太高。作为一个精益求精的测试工程师,决定研究一下多线程在爬虫领域的应用,以提高爬虫的效率。
一、为什么需要多线程
凡事知其然也要知其所以然。在了解多线程的相关知识之前,我们先来看看为什么需要多线程。打个比方吧,你要搬家了,单线程就类似于请了一个搬家工人,他一个人负责打包、搬运、开车、卸货等一系列操作流程,这个工作效率可想而知是很慢的;而多线程就相当于请了四个搬家工人,甲打包完交给已搬运到车上,然后丙开车送往目的地,最后由丁来卸货。
由此可见多线程的好处就是高效、可以充分利用资源,坏处就是各个线程之间要相互协调,否则容易乱套(类似于一个和尚挑水喝、两个和尚抬水喝、三个和尚没水喝的窘境)。所以为了提高爬虫效率,我们在使用多线程时要格外注意多线程的管理问题。
二、多线程的基本知识
进程:由程序,数据集,进程控制块三部分组成,它是程序在数据集上的一次运行过程。如果同一段程序在某个数据集上运行了两次,那就是开启了两个进程。进程是资源管理的基本单位。在操作系统中,每个进程有一个地址空间,而且默认就有一个控制进程。
线程:是进程的一个实体,是CPU调度和分派的基本单位,也是最小的执行单位。它的出现降低了上下文切换的消耗,提高了系统的并发性,并克服了一个进程只能干一件事的缺陷。线程由进程来管理,多个线程共享父进程的资源空间。
进程和线程的关系:
一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
资源分配给进程,同一进程的所有线程共享该进程的所有资源。
CPU分给线程,即真正在CPU上运行的是线程。
线程的工作方式:
如下图所示,串行指线程一个个地在CPU上执行;并行是在多个CPU上运行多个线程;而并发是一种“伪并行”,一个CPU同一时刻只能执行一个任务,把CPU的时间分片,一个线程只占用一个很短的时间片,然后各个线程轮流,由于时间片很短所以在用户看来所有线程都是“同时”的。并发也是大多数单CPU多线程的实际运行方式。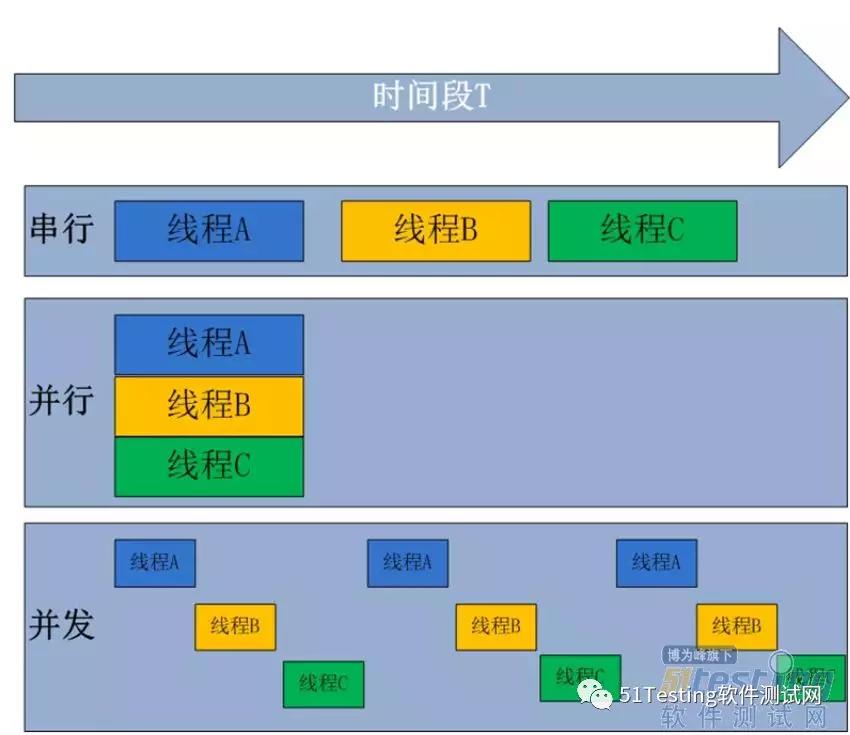
进程的工作状态:
一个进程有三种状态:运行、阻塞、就绪。三种状态之间的转换关系如下图所示:运行态的进程可能由于等待输入而主动进入阻塞状态,也可能由于调度程序选择其他进程而被动进入就绪状态(一般是分给它的CPU时间到了);阻塞状态的进程由于等到了有效的输入而进入就绪状态;就绪状态的进程因为调度程序再次选择了它而再次进入运行状态。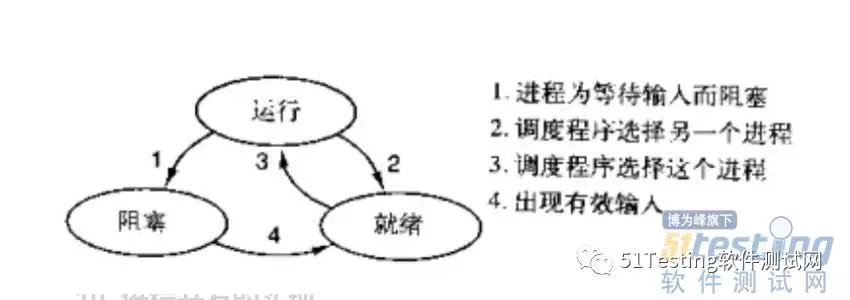
三、多线程通信实例
还是回到爬虫的问题上来,我们知道爬取博客文章的时候都是先爬取列表页,然后根据列表页的爬取结果再来爬取文章详情内容。而且列表页的爬取速度肯定要比详情页的爬取速度快。
这样的话,我们可以设计线程A负责爬取文章列表页,线程B、线程C、线程D负责爬取文章详情。A将列表URL结果放到一个类似全局变量的结构里,线程B、C、D从这个结构里取结果。
在PYTHON中,有两个支持多线程的模块:threading模块--负责线程的创建、开启等操作;queque模块--负责维护那个类似于全局变量的结构。这里还要补充一点:也许有同学会问直接用一个全局变量不就可以了么?干嘛非要用queue?因为全局变量并不是线程安全的,比如说全局变量里(列表类型)只有一个url了,线程B判断了一下全局变量非空,在还没有取出该url之前,cpu把时间片给了线程C,线程C将最后一个url取走了,这时cpu时间片又轮到了B,B就会因为在一个空的列表里取数据而报错。而queue模块实现了多生产者、多消费者队列,在放值取值时是线程安全的。
废话不多说了,直接上代码给大伙看看:
import threading # 导入threading模块
from queue import Queue #导入queue模块
import time #导入time模块 # 爬取文章详情页
def get_detail_html(detail_url_list, id):
while True:
url = detail_url_list.get() #Queue队列的get方法用于从队列中提取元素
time.sleep(2) # 延时2s,模拟网络请求和爬取文章详情的过程
print("thread {id}: get {url} detail finished".format(id=id,url=url)) #打印线程id和被爬取了文章内容的url # 爬取文章列表页
def get_detail_url(queue):
for i in range(10000):
time.sleep(1) # 延时1s,模拟比爬取文章详情要快
queue.put("http://testedu.com/{id}".format(id=i))#Queue队列的put方法用于向Queue队列中放置元素,由于Queue是先进先出队列,所以先被Put的URL也就会被先get出来。
print("get detail url {id} end".format(id=i))#打印出得到了哪些文章的url #主函数
if __name__ == "__main__":
detail_url_queue = Queue(maxsize=1000) #用Queue构造一个大小为1000的线程安全的先进先出队列
# 先创造四个线程
thread = threading.Thread(target=get_detail_url, args=(detail_url_queue,)) #A线程负责抓取列表url
html_thread= []
for i in range(3):
thread2 = threading.Thread(target=get_detail_html, args=(detail_url_queue,i))
html_thread.append(thread2)#B C D 线程抓取文章详情
start_time = time.time()
# 启动四个线程
thread.start()
for i in range(3):
html_thread[i].start()
# 等待所有线程结束,thread.join()函数代表子线程完成之前,其父进程一直处于阻塞状态。
thread.join()
for i in range(3):
html_thread[i].join() print("last time: {} s".format(time.time()-start_time))#等ABCD四个线程都结束后,在主进程中计算总爬取时间。
运行结果: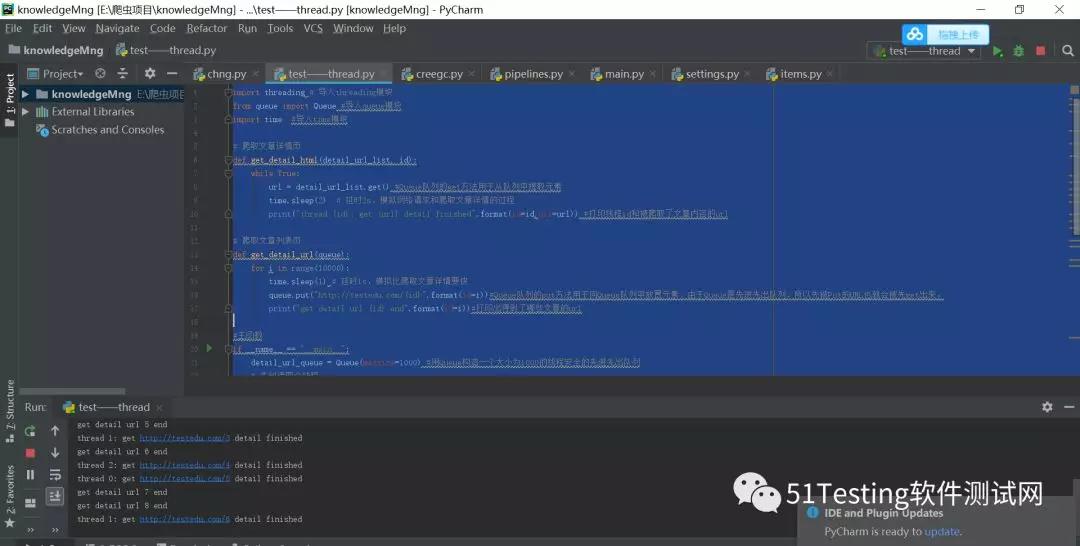
后记:从运行结果可以看出各个线程之间井然有序地工作着,没有出现任何报错和告警的情况。可见使用Queue队列实现多线程间的通信比直接使用全局变量要安全很多。而且使用多线程比不使用多线程的话,爬取时间上也要少很多,在提高了爬虫效率的同时也兼顾了线程的安全,可以说在爬取测试数据的过程中是非常实用的一种方式。希望小伙伴们能够GET到哦!
转自:https://mp.weixin.qq.com/s/LsRNxAVJywKwEXxo8WuwLw
---------------------------------------------------------------------------------
关注微信公众号即可在手机上查阅,并可接收更多测试分享~

Python多线程在爬虫中的应用的更多相关文章
- python学习笔记——爬虫中提取网页中的信息
1 数据类型 网页中的数据类型可分为结构化数据.半结构化数据.非结构化数据三种 1.1 结构化数据 常见的是MySQL,表现为二维形式的数据 1.2 半结构化数据 是结构化数据的一种形式,并不符合关系 ...
- python多线程简单爬虫
爬虫本质就是将网站或者接口的数据经过筛选后按需求保存 这里实现一个简单爬虫仅供参考 import requests import bs4 import threading import queue i ...
- [转]Python多线程与多线程中join()的用法
https://www.cnblogs.com/cnkai/p/7504980.html Python多线程与多进程中join()方法的效果是相同的. 下面仅以多线程为例: 首先需要明确几个概念: 知 ...
- Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. ...
- python多线程爬虫设计及实现示例
爬虫的基本步骤分为:获取,解析,存储.假设这里获取和存储为io密集型(访问网络和数据存储),解析为cpu密集型.那么在设计多线程爬虫时主要有两种方案:第一种方案是一个线程完成三个步骤,然后运行多个线程 ...
- python多线程爬虫+批量下载斗图啦图片项目(关注、持续更新)
python多线程爬虫项目() 爬取目标:斗图啦(起始url:http://www.doutula.com/photo/list/?page=1) 爬取内容:斗图啦全网图片 使用工具:requests ...
- 关于python多线程编程中join()和setDaemon()的一点儿探究
关于python多线程编程中join()和setDaemon()的用法,这两天我看网上的资料看得头晕脑涨也没看懂,干脆就做一个实验来看看吧. 首先是编写实验的基础代码,创建一个名为MyThread的 ...
- python多线程在渗透测试中的应用
难易程度:★★★ 阅读点:python;web安全; 文章作者:xiaoye 文章来源:i春秋 关键字:网络渗透技术 前言 python是门简单易学的语言,强大的第三方库让我们在编程中事半功倍,今天, ...
- python 多线程中的同步锁 Lock Rlock Semaphore Event Conditio
摘要:在使用多线程的应用下,如何保证线程安全,以及线程之间的同步,或者访问共享变量等问题是十分棘手的问题,也是使用多线程下面临的问题,如果处理不好,会带来较严重的后果,使用python多线程中提供Lo ...
随机推荐
- Tornado demo3 - tcpecho分析
在这个demo中,主要是使用了Tornado中异步的TCP client和server来实现一个简单的echo效果(即客户端发送的message会从server端返回到client).代码的githu ...
- springboot4.1.1的log4j2配置
一.默认情况下,Spring Boot会用Logback来记录日志,并用INFO级别输出到控制台: 日志输出内容元素具体如下: 时间日期:精确到毫秒 日志级别:ERROR, WARN, INFO, D ...
- 关于Canvas的坐标系
注意Canvas的坐标系应该是这样子的: 看下面的例子: 最后的显示效果是:
- java虚拟机(十四)--字节码指令
字节码指令其实是很重要的,在之前学习String等内容,深入到字节码层面很容易找到答案,而不是只是在网上寻找答案,还有可能是错误的. PS:本文基于jdk1.8 首先写个简单的类: public cl ...
- 【codeforces 499C】Crazy Town
[题目链接]:http://codeforces.com/problemset/problem/499/C [题意] 一个平面,被n条直线分成若干个块; 你在其中的某一块,然后你想要要到的终点在另外一 ...
- 在skyline中将井盖、雨水箅子等部件放到地面模型上
公司三维建模组遇到这样的一个问题,怎样将井盖.雨水盖子恰好放在做好的地面模型上.传统的方法是在skyline中逐个调整井盖的对地高度,就是调整为恰好能放在地面上.或者选择很粗糙的一个方法,在“高度”属 ...
- [Day4] Nginx Http模块二
一. POST_READ阶段 1. 用户ip在http请求中的传递? 前提:Tcp连接四元组(src ip,src port,dst ip,dst port) HTTP头部 X-Formard ...
- 责任链模式(Chain of Responsibility、Handler)(请求处理建立链)
(使多个对象都有机会处理请求,从而避免了请求的发送者和接受者之间的耦合关系.将这些对象连成一条链,并沿着这条链传递该请求,直到有对象处理它为止.) 从名字中看出 ,系统中将会存在多个有类似处理能力的对 ...
- VC++1.5太伟大了
功能样样俱全,一点不比现在的VS系列差 VC++1.5全貌,虽然很古老,但是已经可以了. 新建的文档试图,多文档工程,很像样 文档试图,单文档工程,已经非常像样了,和记事本差不多了 这是资源编辑器,寒 ...
- JasperReport生命周期3
JasperReports的主要目的是为了在一个简单而灵活的方式创建页面为导向,准备好打印文档.下面的流程图描述了一个典型的工作流程,同时创建报表. 如在图片的生命周期具有以下明显的阶段 设计报表在这 ...