小匠第二周期打卡笔记-Task05
一、卷积神经网络基础
知识点记录:
神经网络的基础概念主要是:卷积层、池化层,并解释填充、步幅、输入通道和输出通道之含义。
二维卷积层:
常用于处理图像数据,将输入和卷积核做互相关运算,并加上一个标量偏置来得到输出。卷积层的模型参数包括卷积核和标量偏置。
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn(kernel_size))
self.bias = nn.Parameter(torch.randn(1)) def forward(self, x):
return corr2d(x, self.weight) + self.bias
案例:构造一张6×8的图像,中间4列为黑(0),其余为白(1),希望检测到颜色边缘。我们的标签是一个6×7的二维数组,第2列是1(从1到0的边缘),第6列是-1(从0到1的边缘)。
X = torch.ones(6, 8)
Y = torch.zeros(6, 7)
X[:, 2: 6] = 0
Y[:, 1] = 1
Y[:, 5] = -1
print(X)
print(Y)
希望学习一个1×2卷积层,通过卷积层来检测颜色边缘。
conv2d = Conv2D(kernel_size=(1, 2))
step = 30
lr = 0.01
for i in range(step):
Y_hat = conv2d(X)
l = ((Y_hat - Y) ** 2).sum()
l.backward()
# 梯度下降
conv2d.weight.data -= lr * conv2d.weight.grad
conv2d.bias.data -= lr * conv2d.bias.grad # 梯度清零
conv2d.weight.grad.zero_()
conv2d.bias.grad.zero_()
if (i + 1) % 5 == 0:
print('Step %d, loss %.3f' % (i + 1, l.item())) print(conv2d.weight.data)
print(conv2d.bias.data)
二维互相关运算:
二位互相关运算的输入是一个二维输入数组和一个二维核数组,输入也是一个二维数组,其中核数组通常称为卷积核或过滤器。卷积核的尺寸通常小于输入数组,卷积核在输入数组上滑动,在每个位置上,卷积核与读位置处输入子数组按元素相乘并求和,得到输出数组中相应位置的元素。如图相互关运算之例:阴影部分分别是输入的第一个计算区域、核数组以及对应的输出。

import torch
import torch.nn as nn def corr2d(X, K):
H, W = X.shape
h, w = K.shape
Y = torch.zeros(H - h + 1, W - w + 1)
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
return Y
X = torch.tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
K = torch.tensor([[0, 1], [2, 3]])
Y = corr2d(X, K)
print(Y)
互相关运算与卷积运算
卷积层得名于卷积运算,但是卷积层中用到的并非卷积运算而是互相关运算。卷积运算过程:将核数组上下翻转、左右翻转,再与输入数组做互相关运算。由于卷积层的核数组是科学系的,所以是用互相关运算与使用卷积运算并无本质区别。
特征图和感受野
二维卷积层输出的二维数组可以看作是输入在空间维度(宽和高)上某一级的表征,也叫特征图。影响元素x的前向计算的所有可能输入区域叫做x的感受野。
我们可以通过更深的卷积神经网络使特征图中单个元素的感受野变得更加广阔,从而捕捉输入上更大尺寸的特征。
填充和步幅:
填充
再输入高和宽的两侧填充元素(通常是0元素)
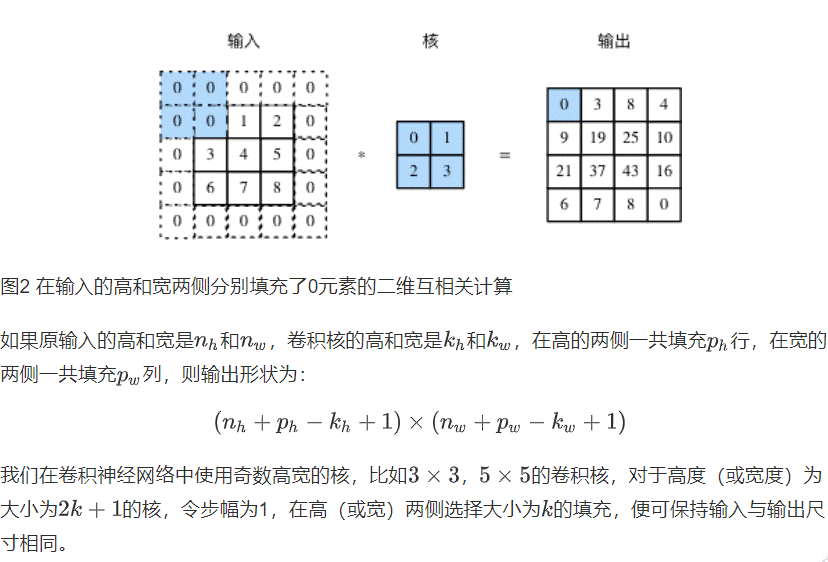
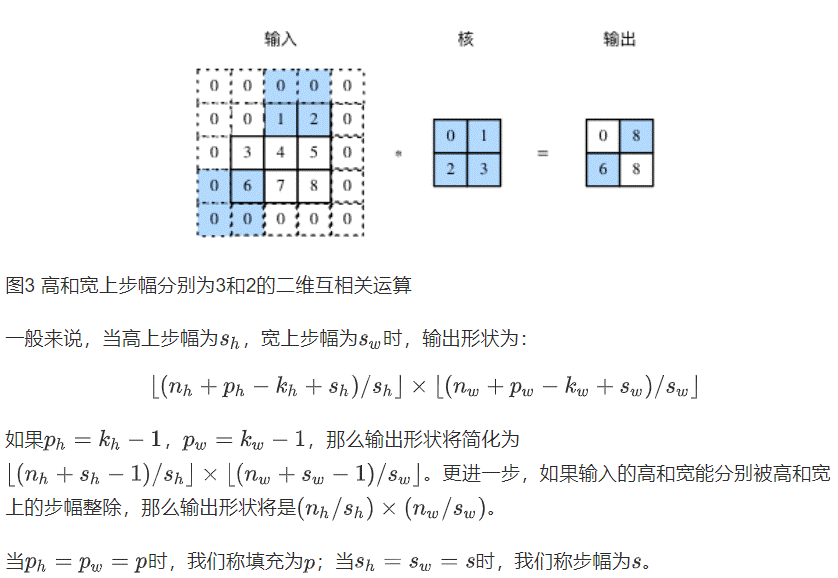
步幅:
互相关运算中,卷积核再输入数组上滑动,每次滑动的行数与列数即是步幅。
多输入通道和多输出通道
真实数据维度通常很高,彩图除宽高外还有RGB3个颜色通道,可以表示为一个3X h X w 的多维数组,将大小为3的这一维称为通道维。
多输入通道
卷积层的输入可以包含多个通道
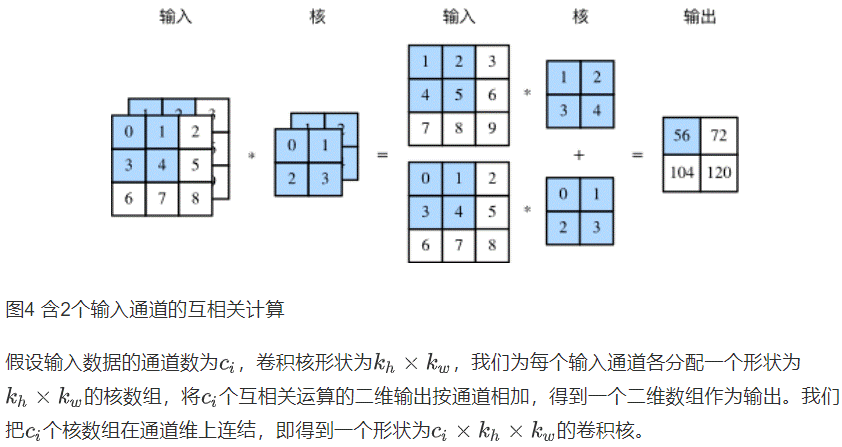
多输出通道 
1 X 1卷积层

卷积层和全连接层的对比:
二维卷积层经常用于处理图像,与此前的全连接层相比,其主优势:
全连接层把图像展平成一个向量,在输入图像上相邻的元素可能因为展平操作不再相邻,网络难以捕捉局部信息。而卷积层的设计,天然的具有提取局部信息的能力。

池化
二维池化层
池化层主要用于缓解卷积层对位置的过度敏感性。同卷积层一样,池化层每次对输入数据的一个固定形状窗口中的元素计算输出,池化层直接计算池化窗口内元素的最大值或者平均值,该运算也分别叫做最大池化或平均池化。
二、leNet
使用全连接的局限性:
图像在同一列邻近的像素在这个向量中可能相距较远。它们构成的模式可能难以被模型识别。对于大尺寸的输入图像,使用全连接层容易导致模型过大。
使用卷积层优势:
卷积层保留输入形状。卷积层通过滑动窗口将同一卷积核与不同位置的输入重读计算,从而避免参数尺寸过大。
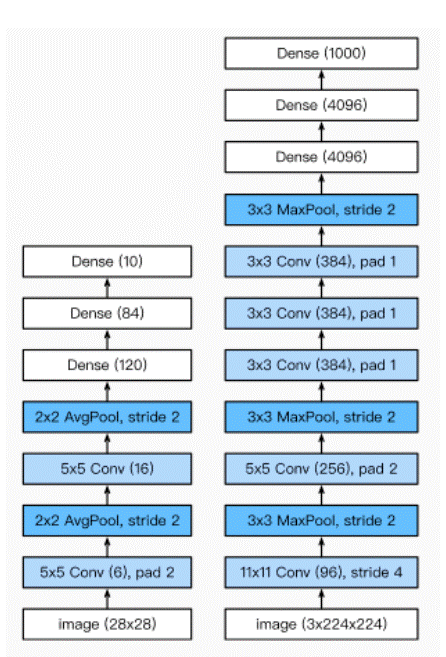
LeNet模型
leNet分为卷积层快和全连接层块两个部分。
卷积层块的基本单位是卷积层后接平均池化层:卷积层用来识别图像里的空间模式。如线条和物体局部,之后的平均池化层则用来降低卷积对位置的敏感性。
卷积层块由两个这样的基本单位重复堆叠构成。在卷积层块中,每个卷积层都使用5X5 的床口,并在输出上使用sigmoid激活函数。第一个卷积层输出通道数为6,第二个卷积层输出通道数则增加到16。
全连接层块含3个全连接层。它们的输出个数分别是120、84、10,其中10为输出的类别个数。
在卷积层块中输入的高和宽在逐层减小。卷积层由于使用高和宽均为5的卷积核,从而将高和宽分别减少4,而池化层则将高和宽减半,但通道数则从1增加到16.全连接层则逐层减少输出个数,直到变成图像的类别数10.
概括:
卷积神经网络回事含卷积层的网络。LeNet 交替使用卷积层和最大池化层后接全连接层来进行图像分类。
三、卷积神经网络进阶
AlexNet
LeNet:在大的真实数据集上的表现并不尽如人意。
神经网络计算复杂。还没有大量深入研究参数初始化和非凸优化算法等诸多领域。
机器学习的特征提取:手工定义的特征提取函数
神经网络的特征提取:通过学习得到数据的多级表征,并逐级表⽰越来越抽象的概念或模式。
神经网络发展的限制:数据、硬件
AlexNet
首次证明了学习到的特征可以超越手工设计的特征,从而一举打破计算机视觉研究的前状。
特征:
8层变换,其中有5层卷积和2层全连接隐藏层,以及一个全连接输出层。
将sigmoid激活函数改成了更加简单的ReLU激活函数。
用Dropout 来控制全连接层的模型复杂度。
引入数据增强,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合。
#目前GPU算力资源预计17日上线,在此之前本代码只能使用CPU运行。
#考虑到本代码中的模型过大,CPU训练较慢,
#我们还将代码上传了一份到 https://www.kaggle.com/boyuai/boyu-d2l-modernconvolutionalnetwork
#如希望提前使用gpu运行请至kaggle。 import time
import torch
from torch import nn, optim
import torchvision
import numpy as np
import sys
sys.path.append("/home/kesci/input/")
import d2lzh1981 as d2l
import os
import torch.nn.functional as F device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
# 前两个卷积层后不使用池化层来减小输入的高和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
#由于使用CPU镜像,精简网络,若为GPU镜像可添加该层
#nn.Linear(4096, 4096),
#nn.ReLU(),
#nn.Dropout(0.5), # 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10),
) def forward(self, img): feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
net = AlexNet()
print(net)
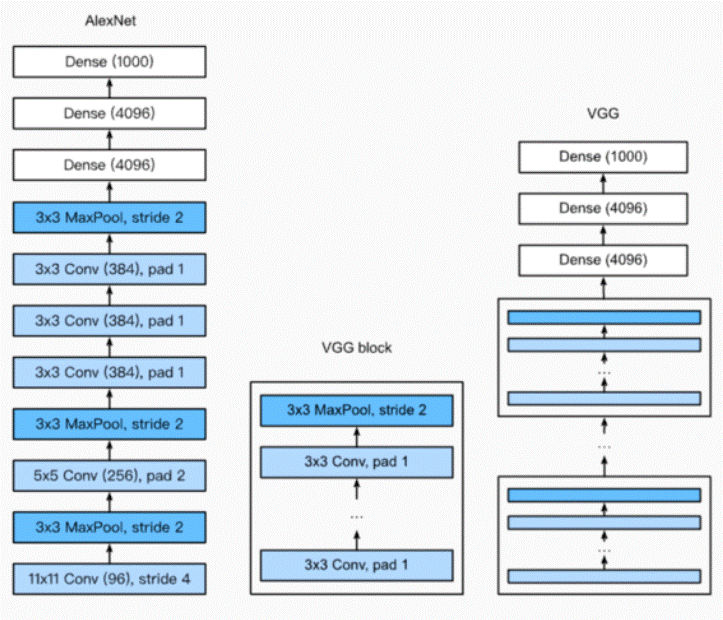
使用重复元素的网络(VGG)
VGG:
通过重复使用简单的基础块来构建深度模型。
Block:
数个相同的填充为1、窗口形状为3X3的卷积层,接上一个步幅为2、窗口形状为2X2的最大池化层。 卷积层保持输入的高和宽不变,而池化层则对其减半。
网络中的网络(NiN)
LeNet、Alex和VGG: 先以由卷积层构成的模块充分抽取空间特征,再以由全连接层构成的模块来输出分类结果。
NiN:串联多个由卷积层和“全连接”层构成的小网络来构建一个深层网络。
用了输出通道数等于标签类别数的NiN块,然后使用全局平均池化层对每个通道中所有元素求平均并直接用于分类。
1X1卷积核作用
放缩通道数:通过控制卷积核的额数量达到通道数的放缩。
增加非线性。1X1卷积核的卷积过程相当于全连接层的计算过程,并且还加入了非线性激活函数,从而可以增加网络的非线性。
计算参数少
GoogLeNet:
由Inception基础块组成
Inception 块相当于一个有4条线路的子网络。它通过不同窗口形状的卷积层和最大池化层来并行抽取信息,并使用1X1卷积层减少通道数从而减低模型复杂度。
可以定义的超参数是每个层的输出通道数,我们可以以此来控制模型复杂度。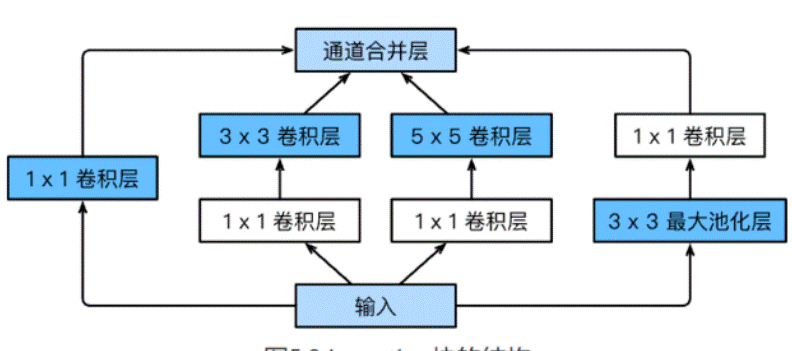
小匠第二周期打卡笔记-Task05的更多相关文章
- 小匠第二周期打卡笔记-Task03
一.过拟合欠拟合及其解决方案 知识点记录 模型选择.过拟合和欠拟合: 训练误差和泛化误差: 训练误差 :模型在训练数据集上表现出的误差, 泛化误差 : 模型在任意一个测试数据样本上表现出的误差的期望, ...
- 小匠第二周期打卡笔记-Task04
一.机器翻译及相关技术 机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经网络翻译(NMT). 主要特征:输出是单词序列而不是单个单词.输出序列的长度可能与 ...
- 小匠第一周期打卡笔记-Task02
一.文本预处理 预处理通常包括四个步骤: 读入文本 分词 建立字典,将每个词映射到一个唯一的索引(index) 将文本从词的序列转换为索引的序列,方便输入模型 读入文本: import collect ...
- 小匠第一周期打卡笔记-Task01
一.线性回归 知识点记录 线性回归输出是一个连续值,因此适用于回归问题.如预测房屋价格.气温.销售额等连续值的问题.是单层神经网络. 线性判别模型 判别模型 性质:建模预测变量和观测变量之间的关系,亦 ...
- 微信小程序消息通知-打卡考勤
微信小程序消息通知-打卡考勤 效果: 稍微改一下js就行,有不必要的错误,我就不改了,哈哈! index.js //index.js const app = getApp() // 填写微信小程序ap ...
- 微信小程序生命周期——小程序的生命周期及页面的生命周期。
最近在做微信小程序开发,也发现一些坑,分享一下自己踩过的坑. 生命周期是指一个小程序从创建到销毁的一系列过程. 在小程序中 ,通过App()来注册一个小程序 ,通过Page()来注册一个页面. 首先来 ...
- 微信小程序生命周期
微信小程序 生命周期 通俗的讲,生命周期就是指一个对象的生老病死. 从软件的角度来看,生命周期指程序从创建.到开始.暂停.唤起.停止.卸载的过程. 下面从一下三个方面介绍微信小程序的生命周期: 应用生 ...
- 微信小程序生命周期详解
文章出处:https://blog.csdn.net/qq_29712995/article/details/79784222 在我看来小程序的生命周期虽然简单,但是他渗透了小程序开发的整个过程,对于 ...
- [Python ]小波变化库——Pywalvets 学习笔记
[Python ]小波变化库——Pywalvets 学习笔记 2017年03月20日 14:04:35 SNII_629 阅读数:24776 标签: python库pywavelets小波变换 更多 ...
随机推荐
- css flex弹性布局学习总结
一.简要介绍 flex( flexible box:弹性布局盒模型),是2009年w3c提出的一种可以简洁.快速弹性布局的属性. 主要思想是给予容器控制内部元素高度和宽度的能力.目前已得到以下浏览器支 ...
- 关于在ssm下创建项目使用阿里巴巴下的druid数据库报错,出现无法创建连接的原因
报错原因:外部jdbc.driver使用原生jdbc驱动jdbc.driver=com.mysql.jdbc.Driverjdbc.url=jdbc:mysql:///yonghedb?charact ...
- 监控自己的电脑浏览器访问记录并生成csv格式
#!usr/bin/env python #-*- coding:utf-8 _*- """ @author:lenovo @file: 获取浏览器历史记录.py @ti ...
- LOJ6287 诗歌
题意 给定一个排列,问是否存在\(\forall a,b,a\neq b\)满足\(2|(a+b)\)且\(\frac{a+b}{2}\)在\(a,b\)间 做法 枚举中点\(a\),即需要存在类似\ ...
- 在线编辑器(WangEditor)
自己之前写了一篇关于POI 相关的博客, 想了想在公司中一般常用的不就是上传下载,poi,分页,定时等.好像还有个在线编辑器, 于是自己就花了两个多小时把编辑器相关的代码撸了遍,当然了是先百度找了找资 ...
- 论文阅读笔记(十九)【ITIP2017】:Super-Resolution Person Re-Identification With Semi-Coupled Low-Rank Discriminant Dictionary Learning
Introduction (1)问题描述: super resolution(SP)问题:Gallery是 high resolution(HR),Probe是 low resolution(LR). ...
- [51nod 1126] 求递推序列的第N项 - 矩阵乘法
#include <bits/stdc++.h> using namespace std; #define int long long const int mod = 7; struct ...
- Byte 一个字节的数据大小范围为什么是-128~127
一个字节是8位,最高位是符号位,最高位为0则是正数.最高位为1则是负数 如果一个数是正数,最大数则为:01111111,转为十进制为127, 如果一个数是负数,按照一般人都会觉得是11111111,转 ...
- JS 数组常见操作汇总,数组去重、降维、排序、多数组合并实现思路整理
壹 ❀ 引 JavaScript开发中数组加工极为常见,其次在面试中被问及的概率也特别高,一直想整理一篇关于数组常见操作的文章,本文也算了却心愿了. 说在前面,文中的实现并非最佳,实现虽然有很多种,但 ...
- 聊聊智能指针 auto_ptr、shared_ptr、weak_ptr和unique_ptr
本文为转载:https://www.cnblogs.com/zeppelin5/p/10083597.html,对作者有些地方做了修正. 手写代码是理解C++的最好办法,以几个例子说明C++四个智能指 ...