分类问题(一)MINST数据集与二元分类器
分类问题
在机器学习中,主要有两大类问题,分别是分类和回归。下面我们先主讲分类问题。
MINST
这里我们会用MINST数据集,也就是众所周知的手写数字集,机器学习中的 Hello World。sk-learn 提供了用于直接下载此数据集的方法:
from sklearn.datasets import fetch_openml
minst = fetch_openml('mnist_784', version=1)
minst.keys()
>dict_keys(['data', 'target', 'feature_names', 'DESCR', 'details', 'categories', 'url'])
像这种sk-learn 下载的数据集,一般都有相似的字典结构,包括:
- DESCR:描述数据集
- data:包含一个数组,每行是一条数据,每列是一个特征
- target:包含一个数组,为label值
我们看一下这些数组:
X,y = minst['data'],minst['target']
X.shape, y.shape
>((70000, 784), (70000,))
可以看到一共有 70000 张图片,每张图片包含784个特征。这是因为每张图包含28×28像素点,每个特征代表的是此像素点强度,取值范围从0(白)到255(黑)。我们先看一下其中一条数据。首先获取一条数据的特征向量,然后reshape到一个28×28 的数组,最后用matplotlib 的imshow() 方法显示即可:
import matplotlib as mpl
import matplotlib.pyplot as plt some_digit = X[0]
some_digit_image = some_digit.reshape(28, 28) plt.imshow(some_digit_image, cmap = mpl.cm.binary, interpolation="nearest")
plt.axis("off")
plt.show()
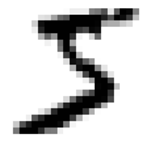
从图片来看,这个应该是数字5,我们可以通过label 进行验证:
y[0]
>''
可以看到这个label的数值是 string,我们需要将它们转换成int:
import numpy as np y = y.astype(np.uint8)
>array([5, 0, 4, ..., 4, 5, 6], dtype=uint8)
现在,我们初步了解了数据集。在训练之前,必须要将数据集分为训练集与测试集。这个MINST数据集已经做好了划分,前60000 为训练接,后10000为测试集,直接取用即可:
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
这个训练集已经做过了shuffle,基本可以确保k-折交叉验证的各个集合基本相似(例如不会出现某个折中缺失一些数字)。另一方面,有些学习算法对于训练数据的顺序比较敏感,所以对数据集进行shuffle的好处是避免数据的顺序对训练造成的影响。
训练二元分类器
我们先简化此问题,仅让我们的模型判断一个数字,例如5。这样的分类器称为二元分类器,仅能将数据分为两个类别:数字5和非数字5。下面我们为这类分类器创建label:
y_train_5 = (y_train == 5)
y_test_5 = (y_test == 5)
现在我们选择一个分类器并进行训练,可以先从一个随机梯度下降(Stochastic Gradient Descent,SGD) 分类器开始,使用sk-learn的SGDClassifer 类。这个分类器的优点是:能够高效地处理非常大的数据集。因为它每次均仅处理一条数据(也正因如此,SGD非常适合online learning 场景)。下面创建一个SGDClassifer 并在整个训练集上进行训练:
from sklearn.linear_model import SGDClassifier sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_5)
SGDClassifier在训练时会随机选择数据,如果要复现结果的话,则需要手动设置random_state 参数。现在我们可以使用已训练好的模型进行预测一个手写数字是否是5:
sgd_clf.predict([X_test[0], X_test[1], X_test[2]])
>array([False, False, False])
看起来结果还不错,我们稍后评估一下这个模型的性能。
分类问题(一)MINST数据集与二元分类器的更多相关文章
- Softmax 回归 vs. k 个二元分类器
如果你在开发一个音乐分类的应用,需要对k种类型的音乐进行识别,那么是选择使用 softmax 分类器呢,还是使用 logistic 回归算法建立 k 个独立的二元分类器呢? 这一选择取决于你的类别之间 ...
- 神经网络中的Heloo,World,基于MINST数据集的LeNet
前言 最近刚开始接触机器学习,记录下目前的一些理解,以及看到的一些好文章mark一下 1.MINST数据集 MNIST 数据集来自美国国家标准与技术研究所, National Institute of ...
- 3.Minst数据集分类
import numpy as np from keras.datasets import mnist from keras.utils import np_utils from keras.mode ...
- 电影评论分类:二分类问题(IMDB数据集)
IMDB数据集是Keras内部集成的,初次导入需要下载一下,之后就可以直接用了. IMDB数据集包含来自互联网的50000条严重两极分化的评论,该数据被分为用于训练的25000条评论和用于测试的250 ...
- ML.NET 示例:二元分类之垃圾短信检测
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
- PyTorch迁移学习-私人数据集上的蚂蚁蜜蜂分类
迁移学习的两个主要场景 微调CNN:使用预训练的网络来初始化自己的网络,而不是随机初始化,然后训练即可 将CNN看成固定的特征提取器:固定前面的层,重写最后的全连接层,只有这个新的层会被训练 下面修改 ...
- 第三章——分类(Classification)
3.1 MNIST 本章介绍分类,使用MNIST数据集.该数据集包含七万个手写数字图片.使用Scikit-Learn函数即可下载该数据集: >>> from sklearn.data ...
- 机器学习入门12 - 分类 (Classification)
原文链接:https://developers.google.com/machine-learning/crash-course/classification/ 1- 指定阈值 为了将逻辑回归值映射到 ...
- sklearn提供的自带的数据集
sklearn 的数据集有好多个种 自带的小数据集(packaged dataset):sklearn.datasets.load_<name> 可在线下载的数据集(Downloaded ...
随机推荐
- Spring的BeanFactory和FactoryBean
官方定义 BeanFactory:Spring Bean容器的根接口 FactoryBean:各个对象的工厂接口,如果bean实现了这个接口,它将被用作对象的工厂,而不是直接作为bean实例. 源码解 ...
- 将一个Head下的Line复制到另一个Head下(ef+linq)
今天工作中有一个需求,要求将一个Item下的Line复制到另外一个Item下面 这个需求在工作中很多,按照以往的经验肯定是先delete from,然后再一条条遍历后insert into 这两天正好 ...
- CF #618 div.2
序 闲来无事,打场CF,本人蒟蒻,考场A了前三道,第四有解答 正文 T1 Non-zero 是道水题.... 给你一个序列a.要求你输出最少的操作次数使这个序列的累和与累乘都不为0: 一次操作指给\( ...
- 一些实用的GitHub项目
原文链接:http://www.louisvv.com/archives/2036.html 最近整理了一些在GitHub上比较热门的开源项目 关于GitHub,快速了解请戳这里 其中涵盖了:学习教程 ...
- Codeforces Round #622(Div 2)C2. Skyscrapers (hard version)
题目链接 : C2. Skyscrapers (hard version) 题目描述 : 与上一道题类似,只是数据范围变大, 5e5, 如果用我们原来的方法,铁定是超时的. 考察点 : 单调栈,贪心, ...
- C#设计模式学习笔记:简单工厂模式(工厂方法模式前奏篇)
本笔记摘抄自:https://www.cnblogs.com/PatrickLiu/p/7551373.html,记录一下学习过程以备后续查用. 一.引言 简单工厂模式并不属于GoF23里面的设计模式 ...
- Jenkins-Publish Over SSH插件
插件安装 打开Jenkins的“系统管理>管理插件”,选择“可选插件”,在输入框中输入“Publish over SSH”进行搜索,如果搜索不到可以在“已安装”里确认是否已经安装过.在搜索结果中 ...
- CF718C Sasha and Array [线段树+矩阵]
我们考虑线性代数上面的矩阵知识 啊呸,是基础数学 斐波那契的矩阵就不讲了 定义矩阵 \(f_x\) 是第 \(x\) 项的斐波那契矩阵 因为 \(f_i * f_j = f_{i+j}\) 然后又因为 ...
- [PAT] A1019 General Palindromic Number
[题目] https://pintia.cn/problem-sets/994805342720868352/problems/994805487143337984 题目大意:给定一个N和b,求N在b ...
- PAT (Basic Level) Practice (中文)1064 朋友数 (20 分) (set)
如果两个整数各位数字的和是一样的,则被称为是“朋友数”,而那个公共的和就是它们的“朋友证号”.例如 123 和 51 就是朋友数,因为 1+2+3 = 5+1 = 6,而 6 就是它们的朋友证号.给定 ...