Spark RDD API(scala)
1、RDD
RDD(Resilient Distributed Dataset弹性分布式数据集)是Spark中抽象的数据结构类型,任何数据在Spark中都被表示为RDD。从编程的角度来看,RDD可以简单看成是一个数组。和普通数组的区别是,RDD中的数据时分区存储的,这样不同分区的数据就可以分布在不同的机器上,同时可以被并行处理。因此,Spark应用程序所做的无非是把需要处理的数据转换为RDD,然后对RDD进行一系列的变换和操作,从而得到结果。
2、RDD创建
RDD可以从普通数组创建出来,也可以从文件系统或者HDFS中的文件创建出来。
1) 从普通数组创建RDD,里面包含了1到9这9个数字,它们分别在3个分区中
scala> val a = sc.parallelize(1 to 9, 3)
2)读取文件README.md来创建RDD,文件中的每一行就是RDD中的一个元素
scala> val b = sc.textFile("README.md")
3、两类操作算子
主要分两类,转换(transformation)和动作(action)。两类函数的主要区别是,transformation接受RDD并返回RDD,而action接受RDD返回非RDD.
transformation操作是延迟计算的,也就是说从一个RDD生成另一个RDD的转换操作不是马上执行,需要等到有action操作的时候才真正触发运算。
action算子会触发spark提交作业job,并将数据输出spark系统。
4、转换算子
更多可以参看 链接
1)map
对RDD中的每个元素都执行一个指定的函数来产生一个新的RDD。任何原RDD中的元素在新RDD中都有且只有一个元素与之对应。
举例:
scala> val a = sc.parallelize(1 to 9, 3)
scala> val b = a.map(x => x*2)
scala> a.collect
res10: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> b.collect
res11: Array[Int] = Array(2, 4, 6, 8, 10, 12, 14, 16, 18)
对比分析下,如果换成flatMap,结果如下:

2)flatMap
与map类似,区别是原RDD中的元素经map处理后只能生成一个元素,而原RDD中的元素经flatmap处理后可生成多个元素来构建新RDD。
举例:对原RDD中的每个元素x产生y个元素(从1到y,y为元素x的值)
scala> val a = sc.parallelize(1 to 4, 2)
scala> val b = a.flatMap(x => 1 to x)
scala> b.collect
res12: Array[Int] = Array(1, 1, 2, 1, 2, 3, 1, 2, 3, 4,1,2,3,4)
对比分析下,如果换成map,结果如下:

3)mapPartitions
mapPartitions是map的一个变种。map的输入函数是应用于RDD中每个元素,而mapPartitions的输入函数是应用于每个分区,也就是把每个分区中的内容作为整体来处理的。
它的函数定义为:
def mapPartitions[U: ClassTag](f: Iterator[T] => Iterator[U], preservesPartitioning: Boolean = false): RDD[U]
f即为输入函数,它处理每个分区里面的内容。每个分区中的内容将以Iterator[T]传递给输入函数f,f的输出结果是Iterator[U]。最终的RDD由所有分区经过输入函数处理后的结果合并起来的。
举例:

上述例子中的函数myfunc是把分区中一个元素和它的下一个元素组成一个Tuple。因为分区中最后一个元素没有下一个元素了,所以(3,4)和(6,7)不在结果中。
mapPartitions还有些变种,比如mapPartitionsWithContext,它能把处理过程中的一些状态信息传递给用户指定的输入函数。还有mapPartitionsWithIndex,它能把分区的index传递给用户指定的输入函数。
4)mapWith
是map的另外一个变种,map只需要一个输入函数,而mapWith有两个输入函数。它的定义如下:
def mapWith[A: ClassTag, U: ](constructA: Int => A, preservesPartitioning: Boolean = false)(f: (T, A) => U): RDD[U]
第一个函数constructA是把RDD的partition index(index从0开始)作为输入,输出为新类型A;
第二个函数f是把二元组(T, A)作为输入(其中T为原RDD中的元素,A为第一个函数的输出),输出类型为U。
举例:把partition index 乘以10,然后加上2作为新的RDD的元素。
val x = sc.parallelize(List(1,2,3,4,5,6,7,8,9,10), 3)
x.mapWith(a => a * 10)((a, b) => (b + 2)).collect
res4: Array[Int] = Array(2, 2, 2, 12, 12, 12, 22, 22, 22, 22)
5)flatMapWith
flatMapWith与mapWith很类似,都是接收两个函数,一个函数把partitionIndex作为输入,输出是一个新类型A;另外一个函数是以二元组(T,A)作为输入,输出为一个序列,这些序列里面的元素组成了新的RDD。它的定义如下:
def flatMapWith[A: ClassTag, U: ClassTag](constructA: Int => A, preservesPartitioning: Boolean = false)(f: (T, A) => Seq[U]): RDD[U]
举例:
scala> val a = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 3)
scala> a.flatMapWith(x => x, true)((x, y) => List(y, x)).collect
res58: Array[Int] = Array(0, 1, 0, 2, 0, 3, 1, 4, 1, 5, 1, 6, 2, 7, 2,8, 2, 9)
6)flatMapValues
flatMapValues类似于mapValues,不同的在于flatMapValues应用于元素为KV对的RDD中Value。每个一元素的Value被输入函数映射为一系列的值,然后这些值再与原RDD中的Key组成一系列新的KV对。
举例
scala> val a = sc.parallelize(List((1,2),(3,4),(3,6)))
scala> val b = a.flatMapValues(x=>x.to(5))
scala> b.collect
res3: Array[(Int, Int)] = Array((1,2), (1,3), (1,4), (1,5), (3,4), (3,5))
上述例子中原RDD中每个元素的值被转换为一个序列(从其当前值到5),比如第一个KV对(1,2), 其值2被转换为2,3,4,5。然后其再与原KV对中Key组成一系列新的KV对(1,2),(1,3),(1,4),(1,5)。
7)union

8)cartesian
9)groupBy

10)filter

当需要比较不同类型数据时,参照 :更多API
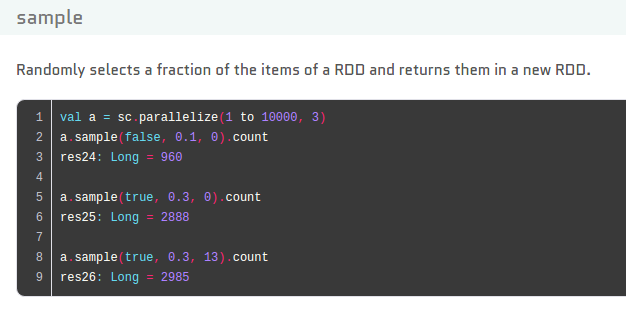
11)sample
12)Cache
将RDD元素从磁盘缓存到内存
如果数据需要复用,可以通过Cache算子,将数据缓存到内存。

13)persist

14)mapValues
顾名思义就是输入函数应用于RDD中Kev-Value的Value,原RDD中的Key保持不变,与新的Value一起组成新的RDD中的元素。因此,该函数只适用于元素为KV对的RDD。
举例:
scala> val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", " eagle"), 2)
scala> val b = a.map(x => (x.length, x))
scala> b.mapValues("x" + _ + "x").collect
res5: Array[(Int, String)] = Array((3,xdogx), (5,xtigerx), (4,xlionx),(3,xcatx), (7,xpantherx), (5,xeaglex))
15)combineByKey
16)reduceByKey
顾名思义,reduceByKey就是对元素为KV对的RDD中Key相同的元素的Value进行reduce,因此,Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对。
举例:
scala> val a = sc.parallelize(List((1,2),(3,4),(3,6)))
scala> a.reduceByKey((x,y) => x + y).collect
res7: Array[(Int, Int)] = Array((1,2), (3,10))
上述例子中,对Key相同的元素的值求和,因此Key为3的两个元素被转为了(3,10)。
17)reduce
reduce将RDD中元素两两传递给输入函数,同时产生一个新的值,新产生的值与RDD中下一个元素再被传递给输入函数直到最后只有一个值为止。
举例:对RDD中的元素求和
scala> val c = sc.parallelize(1 to 10)
scala> c.reduce((x, y) => x + y)
res4: Int = 55
18)join
19)zip

20)intersection

5、Action算子
1)foreach
2)saveAsTextFile
3)collect
相当于toArray,将分布式的RDD返回为一个单机的Scala Array.
4)count
原文引自:https://www.jianshu.com/p/bfeed8f7583d?utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation
Spark RDD API(scala)的更多相关文章
- Spark RDD Operations(2)
处理数据类型为Value型的Transformation算子可以根据RDD变换算子的输入分区与输出分区关系分为以下几种类型. 1)输入分区与输出分区一对一型. 2)输入分区与输出分区多对一型. 3)输 ...
- Spark RDD Operations(1)
以上是对应的RDD的各中操作,相对于MaoReduce只有map.reduce两种操作,Spark针对RDD的操作则比较多 ************************************** ...
- Intellij IDEA使用Maven搭建spark开发环境(scala)
如何一步一步地在Intellij IDEA使用Maven搭建spark开发环境,并基于scala编写简单的spark中wordcount实例. 1.准备工作 首先需要在你电脑上安装jdk和scala以 ...
- Spark RDD初探(一)
本文概要 本文主要从以下几点阐述RDD,了解RDD 什么是RDD? 两种RDD创建方式 向给spark传递函数Passing Functions to Spark 两种操作之转换Transformat ...
- spark 线性回归算法(scala)
构建Maven项目,托管jar包 数据格式 //0.fp_nid,1.nsr_id,2.gf_id,2.hydm,3.djzclx_dm,4.kydjrq,5.xgrq,6.je,7.se,8.jsh ...
- Spark学习之RDD编程(2)
Spark学习之RDD编程(2) 1. Spark中的RDD是一个不可变的分布式对象集合. 2. 在Spark中数据的操作不外乎创建RDD.转化已有的RDD以及调用RDD操作进行求值. 3. 创建RD ...
- Learning Spark中文版--第三章--RDD编程(1)
本章介绍了Spark用于数据处理的核心抽象概念,具有弹性的分布式数据集(RDD).一个RDD仅仅是一个分布式的元素集合.在Spark中,所有工作都表示为创建新的RDDs.转换现有的RDD,或者调 ...
- Scala进阶之路-Spark独立模式(Standalone)集群部署
Scala进阶之路-Spark独立模式(Standalone)集群部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道Hadoop解决了大数据的存储和计算,存储使用HDFS ...
- Spark基础:(二)Spark RDD编程
1.RDD基础 Spark中的RDD就是一个不可变的分布式对象集合.每个RDD都被分为多个分区,这些分区运行在分区的不同节点上. 用户可以通过两种方式创建RDD: (1)读取外部数据集====> ...
随机推荐
- node.js 中的 fs (文件)模块
记录 fs 模块的方法及使用 1. fs.stat 获取文件大小,创建时间等信息 // 引入 fs 模块 const fs = require('fs'); fs.stat('01.fs.js', ( ...
- 022_IO流
对象流 // FileInput.FileOutputStream(节点流)ObjectInputStreamObjectOutputStream 序列化 把内存的数据信息永久的保存在硬盘中,这个过程 ...
- html5语义化标签大全
常见的语义化标签有 <article>.<section>.<nav>.<aside>.<header>.<footer> 详细 ...
- 深入分析Synchronized原理
前言 记得开始学习Java的时候,一遇到多线程情况就使用synchronized,相对于当时的我们来说synchronized是这么的神奇而又强大,那个时候我们赋予它一个名字“同步”,也成为了我们解决 ...
- 数据整理B
- 为Python终端提供持久性历史记录
有没有办法告诉交互式Python shell在会话之间保留其执行命令的历史记录? 当会话正在运行时,在执行命令之后,我可以向上箭头并访问所述命令,我只是想知道是否有某种方法可以保存这些命令,直到下次我 ...
- 第七篇 css选择器实现字段解析
CSS选择器的作用实际和xpath的一样,都是为了定位具体的元素 举例我要爬取下面这个页面的标题 In []: title = response.css(".entry-header h1& ...
- 论文学习——《Good View Hunting: Learning Photo Composition from Dense View Pairs》
论文链接:http://www.zijunwei.org/papers/cvpr18-photo-composition.pdf 代码及数据集链接:https://www3.cs.stonybrook ...
- nodejs mysql 连接数据库
1.设计数据库 2.设计数据库表 3.下载MySQL模块 npm install --save mysql 4.编写代码 const mysql=require('mysql'); //1.连接 // ...
- BeautifulSoup 爬虫
一 安装BeautifulSoup 安装Python的包管理器pip 然后运行 $pip3 install beautifulsoup 在终端里导入它测试下是否安装成功 >>>fro ...