吴裕雄--天生自然HADOOP操作实验学习笔记:hive DDL
实验目的
了解hive DDL的基本格式
了解hive和hdfs的关系
学习hive在hdfs中的保存方式
学习一些典型常用的hiveDDL
实验原理
有关hive的安装和原理我们已经了解,这次实验我们通过使用hive进行简单的测试进一步了解hive。hive DDL的意思是Hive Data Definition Language,hive数据定义语言,操作和关系型数据库的DDL类似,但是也有很多新功能。我们学习的方式就是通过打开官方网站的文档,进行操作。
1.电脑语言
数据库模式定义语言并非程序设计语言,DDL数据库模式定义语言是SQL语言(结构化查询语言)的组成部分。SQL语言包括四种主要程序设计语言类别的语句:数据定义语言(DDL),数据操作语言(DML),数据控制语言(DCL)和事务控制语言(TCL)。
DDL描述的模式,必须由计算机软件进行编译,转换为便于计算机存储、查询和操纵的格式,完成这个转换工作的程序称为模式编译器。
模式编译器处理模式定义主要产生两种类型的数据:数据字典以及数据类型和结构定义。
数据字典和数据库内部结构信息是创建该模式所对应的数据库的依据,根据这些信息创建每个数据库对应的逻辑结构;对数据库数据的访问、查询也根据模式信息决定数据存取的方式和类型,以及数据之间的关系和对数据的完整性约束。
数据字典是模式的内部信息表示,数据字典的存储方式对不同的DBMS各不相同。
数据类型和结构的定义,是指当应用程序与数据库连接操作时,应用程序需要了解产生和提取的数据类型和结构。是为各种宿主语言提供的用户工作区的数据类型和结构定义,使用户工作区和数据库的逻辑结构相一致,减少数据的转换过程,这种数据类型和结构的定义通常用一个头文件来实现。
数据库模式的定义通常有两种方式: 交互方式定义模式和通过数据描述语言DDL 描述文本定义模式。
2.DDL
数据库模式定义语言DDL(Data Definition Language),是用于描述数据库中要存储的现实世界实体的语言。一个数据库模式包含该数据库中所有实体的描述定义。
DDL基本格式
hive的官网是hive.apache.org,打开以后进入Language Manual页面,选择DDL。就可以看到hiveDDL的基本格式:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
create后面的[TEMPORARY] [EXTERNAL]是两个选项,因为hive的数据是存储在hdfs上的, 如果选择了external,删除hive表后,hdfs上的数据不会删除,否则删除表格也会删除数据。然后是选择hive表格属性名和数据类型。partitioned by是分区,stored as是存储方式,还有一些其余的相关选项。
3.hive数据类型
首先我们需要了解hive的数据类型,primitive_type、array_type、map_type、struct_type,其中primitive_type常用的有INT、BIGINT、BOOLEAN、FLOAT、DOUBLE、STRING等,其他的可以查看官网。
4.hive分区
hive添加分区以后,实际上这个hive表就多了分区属性,而分区是通过文件夹的形式表现出来的。例如学生属性表包括了id和姓名,根据性别分区,这样我们的最后的表格的数据就包括了id、姓名和性别三个属性,而hdfs上的数据被放在两个文件夹下,每个文件夹下的数据都有两列:id和姓名。
5.hive ROW FORMAT
ROW FORMAT的意思是每一行的格式,最简单的就是通过分隔符,另外还有正则表达式或者自定义的类。例如 WITH SERDEPROPERTIES ("input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*?)\" (-|[0-9]*) (-|[0-9]*)"代表每一行格式符合这个正则表达式。而row format delimited fields terminated by ',' collection by '-' map keys terminated by ':' lines terminated by '\n';代表通过使用分隔符隔开每个属性。
6.hive存储
hive支持多种存储方式,例如文本、压缩的序列化文件、parquet文件等。
实验环境
1.操作系统
服务器:Linux_Centos
操作机:Windows_7
服务器默认用户名:root,密码:123456
操作机默认用户名:hongya,密码:123456
2.实验工具
1.Xshell

Xshell是一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议。Xshell 通过互联网到远程主机的安全连接以及它创新性的设计和特色帮助用户在复杂的网络环境中享受他们的工作。
Xshell可以在Windows界面下用来访问远端不同系统下的服务器,从而比较好的达到远程控制终端的目的。实验中我们用到XShell5,其新增功能有:
1.有效保护信息安全性;Xshell支持各种安全功能,如SSH1/SSH2协议,密码,和DSA和RSA公开密钥的用户认证方法,并加密所有流量的各种加密算法。重要的是要保持用户的数据安全与内置Xshell安全功能,因为像Telnet和Rlogin这样的传统连接协议很容易让用户的网络流量受到任何有网络知识的人的窃取。Xshell将帮助用户保护数据免受黑客攻击。
2.最好的终端用户体验;终端用户需要经常在任何给定的时间中运用多个终端会话,以及与不同主机比较终端输出或者给不同主机发送同一组命令。Xshell则可以解决这些问题。此外还有方便用户的功能,如标签环境,广泛拆分窗口,同步输入和会话管理,用户可以节省时间做其他的工作。
3.代替不安全的Telnet客户端;Xshell支持VT100,VT220,VT320,Xterm,Linux,Scoansi和ANSI终端仿真和提供各种终端外观选项取代传统的Telnet客户端。
4. Xshell在单一屏幕实现多语言;Xshell中的UTF-8在同类终端软件中是第一个运用的。用Xshell,可以将多种语言显示在一个屏幕上,无需切换不同的语言编码。越来越多的企业需要用到UTF-8格式的数据库和应用程序,有一个支持UTF-8编码终端模拟器的需求在不断增加。Xshell可以帮助用户处理多语言环境。 5. 支持安全连接的TCP/IP应用的X11和任意;在SSH隧道机制中,Xshell支持端口转发功能,无需修改任何程序,它可以使所有的TCP/IP应用程序共享一个安全的连接。

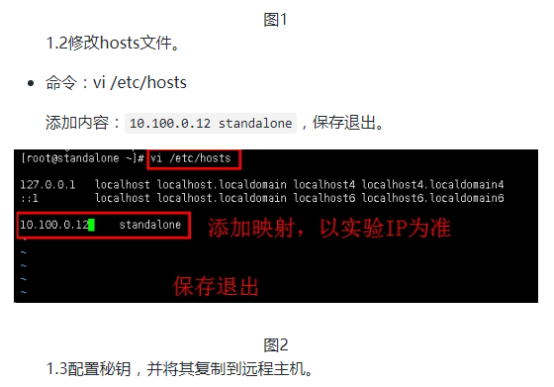
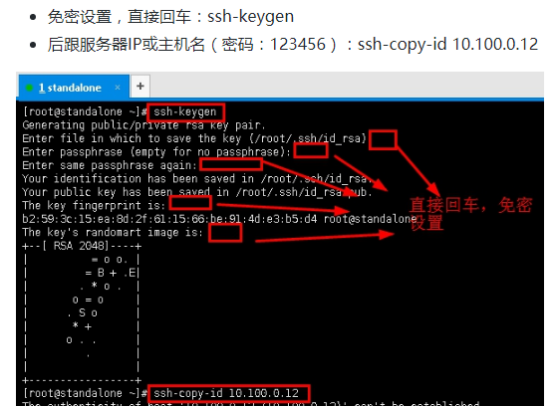
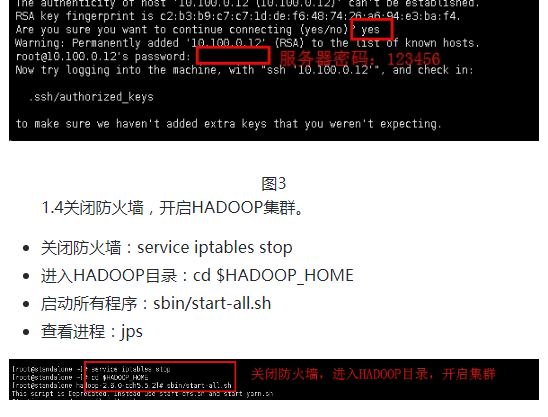



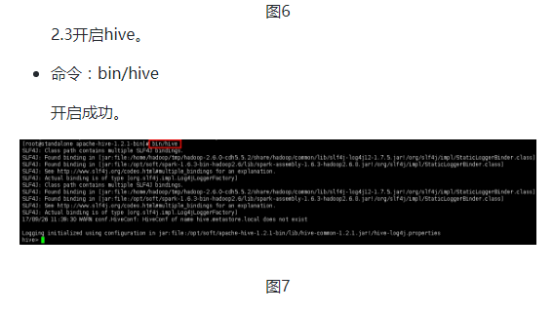
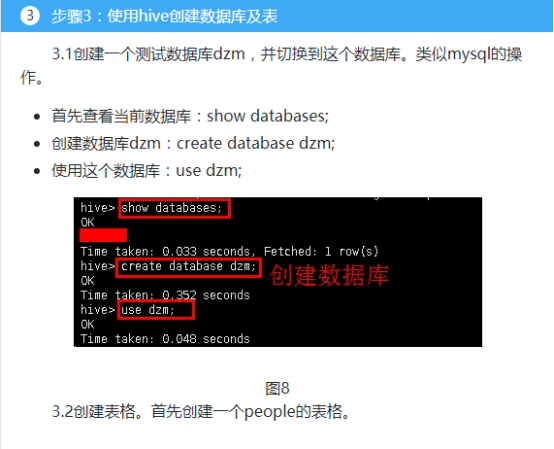


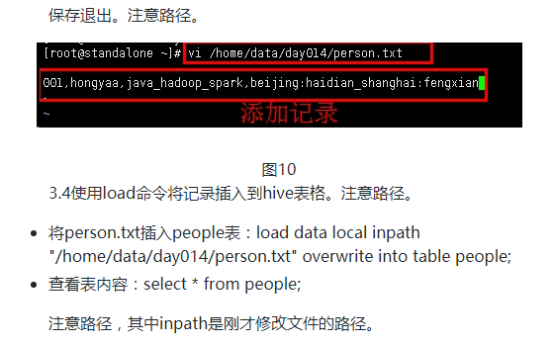
001,hongyaa,java_hadoop_spark,beijing:haidian_shanghai:fengxian

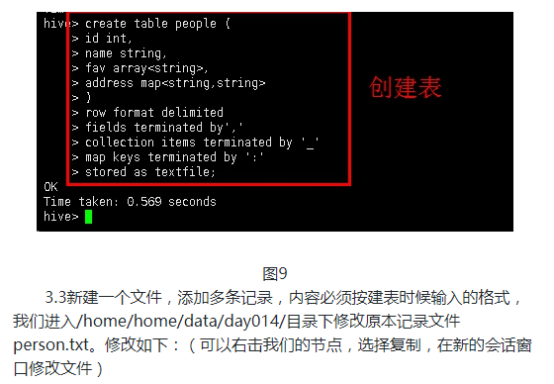
4.1创建表格,导入数据。首先创建一个student的表格。
create table student (id int, name string) partitioned by (sex string) row format delimited fields terminated by ',';
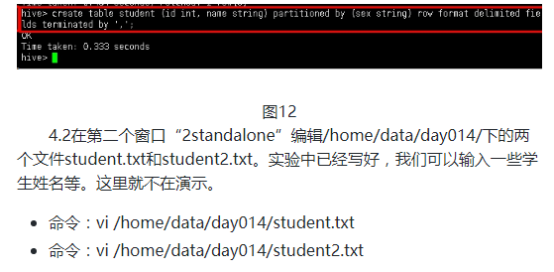

4.3回到“1standalone”,在hive中使用load语句导入到hive的分区表。
load data local inpath "/home/data/day014/student.txt" overwrite into table student partition (sex='male');
load data local inpath "/home/data/day014/student2.txt" overwrite into table student partition (sex='female');
select * from student; //查看表内容


5.1创建表格。命令如下:
CREATE TABLE apachelog (
host STRING,
identity STRING,
t_user STRING,
time STRING,
request STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*) (-|[0-9]*)"
)
STORED AS TEXTFILE;
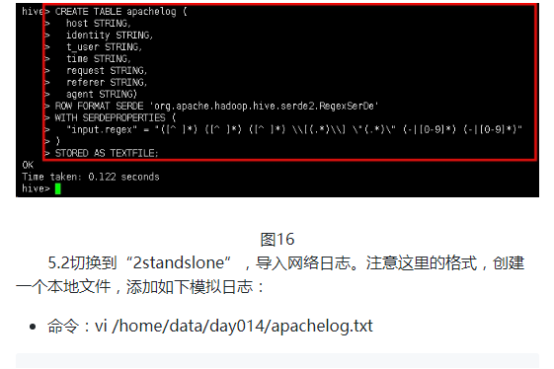
5.3切换到“1standslone”插入数据,查看内容。
load data local inpath '/home/data/day014/apachelog.txt'overwrite into table apachelog;
select * from apachelog;

吴裕雄--天生自然HADOOP操作实验学习笔记:hive DDL的更多相关文章
- 吴裕雄--天生自然HADOOP操作实验学习笔记:使用hive操作hbase
实验目的 熟悉hive和hbase的操作 熟悉hadoop.hbase.hive.zookeeper的关系 熟练大数据环境的搭建 学会分析日志排除问题 实验原理 1.hive整合hbase原理 前面大 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce代码编程
实验目的 深入了解mapreduce的底层 了解IDEA的使用 学会通过本地和集群环境提交程序 实验原理 1.回忆mapreduce模型 前面进行了很多基础工作,本次实验是使用mapreduce的AP ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:分布式及RPC通信简介
实验目的 掌握GOF设计模式的代理模式 了解掌握socket编程.java反射.动态代理 了解NIO.多线程 掌握hadoop的RPC框架使用API 实验原理 1.什么是RPC 在hadoop出现以前 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase学生选课案例
实验目的 复习hbase的shell操作和javaAPI操作 了解javaWeb项目的MVC设计 学会dao(数据库访问对象)和service层的代码编写规范 学会设计hbase表格 实验原理 前面我 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的javaAPI应用
实验目的 进一步了解hbase的操作 熟悉使用IDEA进行java开发 熟悉hbase的javaAPI 实验原理 前面已经了解通过hbase的shell操作hbase,确实比较难以使用,另外通过hiv ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的shell应用v2.0
HRegion 当表的大小超过设置值的时候,HBase会自动地将表划分为不同的区域,每个区域包含所有行的一个子集.对用户来说,每个表是一堆数据的集合,靠主键来区分.从物理上来说,一张表被拆分成了多块, ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce和yarn命令
实验目的 了解集群运行的原理 学习mapred和yarn脚本原理 学习使用Hadoop命令提交mapreduce程序 学习对mapred.yarn脚本进行基本操作 实验原理 1.hadoop的shel ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hdfs简单的shell命令
实验目的 了解bin/hadoop脚本的原理 学会使用fs shell脚本进行基本操作 学习使用hadoop shell进行简单的统计计算 实验原理 1.hadoop的shell脚本 当hadoop集 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:分布式资源调度系统yarn的安装
实验目的 复习配置hadoop初始化环境 复习配置hdfs的配置文件 学会配置hadoop的配置文件 了解yarn的原理 实验原理 1.yarn是什么 前面安装好了hdfs文件系统,我们可以根据需求进 ...
随机推荐
- 深入理解windows 消息机制
深入理解Windows消息机制 今天我们来学一学Windows消息机制,我们知道在传统的C语音程序中,当我们需要打开一个文件时,我们可以调用fopen()函数,这个函数最后又会调用操作系统提供的函数以 ...
- 谷歌翻译API
http://translate.google.cn/translate_a/t?client=t&text=你好&hl=zh-CN&sl=zh-CN&tl=en&am ...
- java(list,set,map)链接
http://blog.csdn.net/smileiam/article/details/49836865 http://blog.csdn.net/u013344815/article/detai ...
- WeChall_Enlightment (Encoding)
解题: 刚开始一看这题就蒙逼了,完全没思路,过了几天后再仔细去想想,应该是二进制的ascii码,但是原来的三张图虽然都是8的倍数,但完全转换不成有用的东西,题目的意思能否找到光,百度了一下关于三原色的 ...
- Codeforces 1062B Math(质因数分解)
题意: 给一个数n,可以将它乘任意数,或者开方,问你能得到的最小数是多少,并给出最小操作次数 思路: 能将这个数变小的操作只能是开方,所以构成的最小数一定是 $n = p_1*p_2*p_3*\dot ...
- python练习——第2题
原GitHub地址:https://github.com/Yixiaohan/show-me-the-code 题目:将 0001 题生成的 200 个激活码(或者优惠券)保存到 MySQL 关系型数 ...
- Request库的安装与使用
Request库的安装与使用 安装 pip install reqeusts Requests库的7个主要使用方法 requests.request() 构造一个请求,支撑以下各方法的基础方法 req ...
- [Effective Java 读书笔记] 第6章 枚举和注解
第三十条 用enum代替int 总得来说,使用enum有几点好处 1.编译时的类型安全, 2.可以保证就是自己定义的值,不会有月结风险, 3.每个枚举类型有自己的命名空间 4.枚举可以添加任意的方法和 ...
- 学习Sparql
一 . gstore--一种开源图数据库系统 https://www.docin.com/p-1951514687.html 二 . 使用 SPARQL 查询 RDF 数据 https://www.i ...
- firewall-cmd命令
firewalld 基本操作 安装firewalld # yum install firewalld firewall-config firewalld启动,停止,开机启动与否,查看状态 # syst ...