KMP算法简明法则
KMP算法也算是相当经典,但是对于初学者来说确实有点绕,大学时候弄明白过后来几年不看又忘记了,然后再弄明白过了两年又忘记了,好在之前理解到了关键点,看了一遍马上又能理解上来。关于这个算法的详解网上文章可以说遍地开花,可我觉得大多数文章,不需要看内容,光看看详解的文章篇幅就可以吓死人,然后讲来讲去内容也让人云里雾里。我在这里结合自己的理解,简单的解释一下。
在读这篇文章之前,首先请忘记以前了解的关于KMP算法的任何知识点。因为关于有些文章的解释还不一样,可能会让本来就很绕的说法变得更绕,与其说哪样还不如心中无一物一切归零重新开始。
然后来看一张图,这是两段字符暴力匹配的过程:
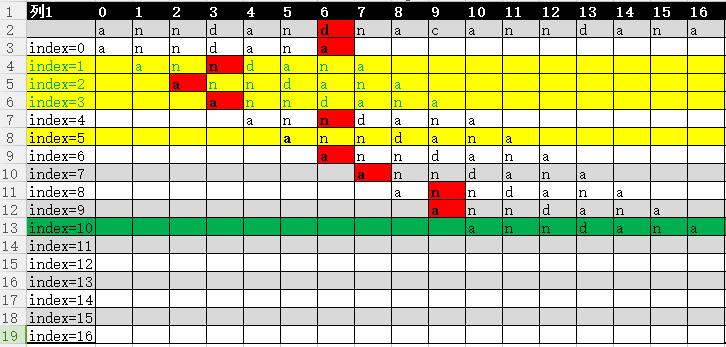
以上黄色部分是多余比较,红色是不匹配,绿色的匹配成功
目标字符串T:anndandnacanndana
匹配字符串P:anndana
匹配的时候匹配字符串从前到后移动了10次比较结束,最后得到确认结果。但是事实上图中黄色部分的比较是不需要的,也就是说如果利用KMP算法的特点,从中可以减少4次移动,从而会减少一些无意义的比较次数。那么问题来了,KMP算法为什么能减少这么多次比较次数呢?这究竟是有什么内部含义?
事实上,KMP算法就是典型的利用空间换时间,首先根据匹配字符串(annacanna) 特点,换算出来一张表(Next数组),每次移动多少根据表中的数据取值。
好吧,以上就是KMP的概要,归结起来也就是两条法则:
Next数组计算法则:对于任何字符串P的第n项(记为Pn),此时的Next[n]为字符串P第n项之前的前缀和后缀共有字符串的最大长度。所谓前缀和后缀,就是分别除去首字符和末尾字符后的所有元素,然后取最大共有字符串的长度。
以anndana例:
1."a"的前缀和后缀都为空集,共有元素的长度为0;
2."an"的前缀为[a],后缀为[n],共有元素的长度为0;
3."ann"的前缀为[a, an],后缀为[nn, n],共有元素的长度0;
4."annd"的前缀为[a, an, ann],后缀为[nnd, nn, d],共有元素的长度为0;
5."annda"的前缀为[a, an, ann, annd],后缀为[nnda, nda,da, a],共有元素为"a",长度为1;
6."anndan"的前缀为[a, an, ann, annd, annda],后缀为[nndan, ndan, dan, an, a],共有元素为"an","a",但是长度为2;
7."anndana"的前缀为[a, an, ann, annd, annda, anndan],后缀为[nndana, ndana, dana, ana, na, a],共有元素“a”的长度为1。
移动法则:对于要比较的目标字符串T和匹配字符串P,首先利用匹配字符串P换算出来匹配移动表Next数组,然后匹配,当P(n)与T(m)不等的时候:
1) 如果n=0,则匹配字符串向右移动1位
2) 如果n>0 则取Next(n),向右移动整个匹配字符串直到P(Next(n))与T(m)对其比较,可以说移动位数就是已匹配字符串长度-Next(n)。
那么结合上图理解
1.当index=0的时候,不匹配索引出现在6,因为next[6]=2,那么按照上面的法则,就应该讲P(2)与T(6)对其比较,于是需要将P移动5位,那么index=1与index=2,index=3就是多余的比较而画上了黄色。
2.当index=3的时候因为第一项就不匹配,于是出现时n=0,此时右移一位,同样后面也是这个道理。
3.当index=4的时候,因为第三项不匹配,于是出现n=2,而next[2]=0,按照上面法则就应该移动2位。这一行道理也很简单,因为T1=P1,T2=P2,但是P1!=P2,那么必然会有T2!=P1,所以index=5也是多余的。
事实上,以上图的目标字符串T:anndandnacanndana,匹配字符串P:anndana为例,当T(6)和P(6)出现不等的时候,此时取Next(6)=2,然后移动使得P(2)与T(6)比较。可是我们为什么会想到移动这么多位呢?因为对于P来说,前两项和第4,5两项相等都是an,此时算出来Next数组对应值为2,那么第2,3两项也就是nd断然不会与前两项或者第4,5两项相等,可以想象假如相等,那么next数组对应的值就不是2了,所移动的位数也会发生改变。因为next数组决定了字符串的特诊,而KMP算法巧妙的利用这条已经比较过的信息来规避掉多余的比较。细细品味,其他类型的字符串也很巧妙,但是本质还是一样的。
void getnext(int next[],string T)
{
next[]=-;
int i=,j=-;
while(i<T.length()-)
{
if( (j==-)||(T[i]==T[j]) )
{
i++;
j++;
if(T[i]!=T[j]) next[i]=j;
else next[i]=next[j];
}
else
j=next[j];
}
}
int KMP(int pos,string M,string N)
{
int next[];
getnext(next,N);
int i=pos-,j=;
int mlen=M.length(),nlen=N.length();
while( (i<mlen )&&(j<nlen ))
{
if( (j==-)||(M[i]==N[j]) )
{
i++;j++;
}
else
j=next[j];
}
if(j>=nlen) return i-nlen+;
else return ;
}
KMP算法简明法则的更多相关文章
- kmp算法简明教程
在字符串s中寻找模式串p的位置,这是一个字符串匹配问题. 举例说明: i = 0 1 2 3 4 5 6 7 8 9 10 11 12 13 s = a b a a c a b a a a b a a ...
- KMP算法简明扼要的理解
KMP算法也算是相当经典,但是对于初学者来说确实有点绕,大学时候弄明白过后来几年不看又忘记了,然后再弄明白过了两年又忘记了,好在之前理解到了关键点,看了一遍马上又能理解上来.关于这个算法的详解网上文章 ...
- 浅谈KMP算法及其next[]数组
KMP算法是众多优秀的模式串匹配算法中较早诞生的一个,也是相对最为人所知的一个. 算法实现简单,运行效率高,时间复杂度为O(n+m)(n和m分别为目标串和模式串的长度) 当字符串长度和字符集大小的比值 ...
- 字符串匹配的BF算法和KMP算法学习
引言:关于字符串 字符串(string):是由0或多个字符组成的有限序列.一般写作`s = "123456..."`.s这里是主串,其中的一部分就是子串. 其实,对于字符串大小关系 ...
- 【算法】KMP算法
简介 KMP算法由 Knuth-Morris-Pratt 三位科学家提出,可用于在一个 文本串 中寻找某 模式串 存在的位置. 本算法可以有效降低在一个 文本串 中寻找某 模式串 过程的时间复杂度.( ...
- 简单有效的kmp算法
以前看过kmp算法,当时接触后总感觉好深奥啊,抱着数据结构的数啃了一中午,最终才大致看懂,后来提起kmp也只剩下“奥,它是做模式匹配的”这点干货.最近有空,翻出来算法导论看看,原来就是这么简单(先不说 ...
- KMP算法
KMP算法是字符串模式匹配当中最经典的算法,原来大二学数据结构的有讲,但是当时只是记住了原理,但不知道代码实现,今天终于是完成了KMP的代码实现.原理KMP的原理其实很简单,给定一个字符串和一个模式串 ...
- 萌新笔记——用KMP算法与Trie字典树实现屏蔽敏感词(UTF-8编码)
前几天写好了字典,又刚好重温了KMP算法,恰逢遇到朋友吐槽最近被和谐的词越来越多了,于是突发奇想,想要自己实现一下敏感词屏蔽. 基本敏感词的屏蔽说起来很简单,只要把字符串中的敏感词替换成"* ...
- KMP算法实现
链接:http://blog.csdn.net/joylnwang/article/details/6778316 KMP算法是一种很经典的字符串匹配算法,链接中的讲解已经是很明确得了,自己按照其讲解 ...
随机推荐
- [转]C++ 使用Makefile文件
//*********list class.h**********class tdate {private:int month;int day;int year;public:tdate();tdat ...
- java之jvm学习笔记六(实践写自己的安全管理器)
安全管理器SecurityManager里设计的内容实在是非常的庞大,它的核心方法就是checkPerssiom这个方法里又调用AccessController的checkPerssiom方法,访问控 ...
- 9.3.2 The force and release procedural statements
Frm: IEEE Std 1364™-2001, IEEE Standard Verilog® Hardware Description Language Another form of proce ...
- centos安装完php-fpm、nginx后访问网站出现权限问题
nginx.conf www.conf 这两个文件上面改用户为www. 如果不知道自己的配置文件位置问题,使用命令查找文件位置: find / -name 'nginx.conf' -print 添加 ...
- jquery网页定位导航特效
<!DOCTYPE html> <html lang="en"> <head> <script src="http://code ...
- Selenium(二)---无界面模式+滑动底部
一.使用无界面模式 1.正常情况启动 selenium 是有界面的 2.有些情况下,需要不显示界面,这时只要设置一下参数就可以实现了 # 不想显示界面可以用 Chrome——配置一下参数就好 from ...
- Blahut-Arimoto algorithm Matlab源码
For a discrete memoryless channel , the capacity is defined as where and denote the input and outp ...
- C++ 系列:函数可变长参数
一.基础部分 1.1 什么是可变长参数 可变长参数:顾名思义,就是函数的参数长度(数量)是可变的.比如 C 语言的 printf 系列的(格式化输入输出等)函数,都是参数可变的.下面是 printf ...
- [JZOJ3235] 数字八
题目 题目大意 给你一个二维的图,其中.代表完好,*代表有缺陷. 现在要在图上刻一个数字\(8\),满足: 由两个矩形组成. 每个矩形中必须有空隙在内部,也就是说,至少为\(3*3\)的矩形. 上矩形 ...
- JS函数进阶
函数的定义方式 函数声明 函数表达式 new Function 函数声明 function foo () { } 函数表达式 var foo = function () { } 函数声明与函数 ...