t-SNE and PCA
1.t-SNE
- t-分布领域嵌入算法
- 虽然主打非线性高维数据降维,但是很少用,因为
- 比较适合应用于可视化,测试模型的效果
- 保证在低维上数据的分布与原始特征空间分布的相似性高
因此用来查看分类器的效果更加
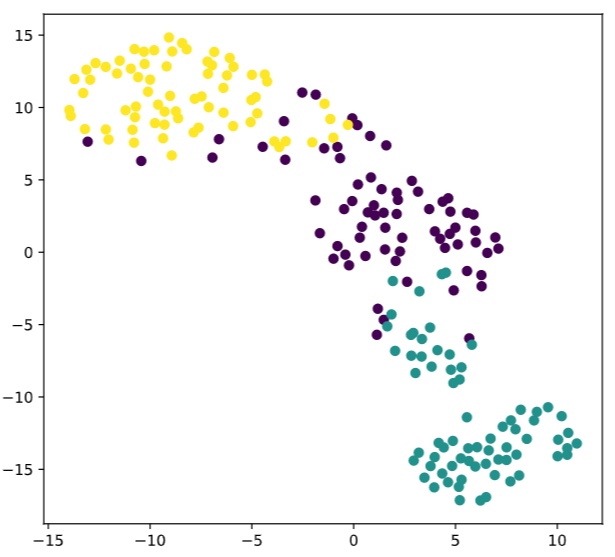
1.1 复现demo
# Import TSNE
from sklearn.manifold import TSNE
# Create a TSNE instance: model
model = TSNE(learning_rate=200)
# Apply fit_transform to samples: tsne_features
tsne_features = model.fit_transform(samples)
# Select the 0th feature: xs
xs = tsne_features[:,0]
# Select the 1st feature: ys
ys = tsne_features[:,1]
# Scatter plot, coloring by variety_numbers
plt.scatter(xs,ys,c=variety_numbers)
plt.show()
2.PCA
主成分分析是进行特征提取,会在原有的特征的基础上产生新的特征,新特征是原有特征的线性组合,因此会达到降维的目的,但是降维不仅仅只有主成分分析一种
- 当特征变量很多的时候,变量之间往往存在多重共线性。
- 主成分分析,用于高维数据降维,提取数据的主要特征分量
- PCA能“一箭双雕”的地方在于
- 既可以选择具有代表性的特征,
- 每个特征之间线性无关
- 总结一下就是原始特征空间的最佳线性组合
有一个非常易懂的栗子知乎
2.1 数学推理
可以参考【机器学习】降维——PCA(非常详细)
Making sense of principal component analysis, eigenvectors & eigenvalues
2.2栗子
sklearn里面有直接写好的方法可以直接使用
from sklearn.decomposition import PCA
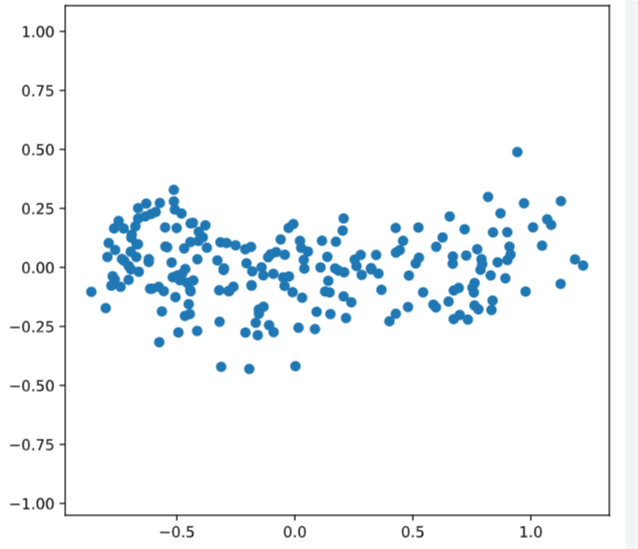
# Perform the necessary imports
import matplotlib.pyplot as plt
from scipy.stats import pearsonr
# Assign the 0th column of grains: width
width = grains[:,0]
# Assign the 1st column of grains: length
length = grains[:,1]
# Scatter plot width vs length
plt.scatter(width, length)
plt.axis('equal')
plt.show()
# Calculate the Pearson correlation
correlation, pvalue = pearsonr(width, length)
# Display the correlation
print(correlation)

# Import PCA
from sklearn.decomposition import PCA
# Create PCA instance: model
model = PCA()
# Apply the fit_transform method of model to grains: pca_features
pca_features = model.fit_transform(grains)
# Assign 0th column of pca_features: xs
xs = pca_features[:,0]
# Assign 1st column of pca_features: ys
ys = pca_features[:,1]
# Scatter plot xs vs ys
plt.scatter(xs, ys)
plt.axis('equal')
plt.show()
# Calculate the Pearson correlation of xs and ys
correlation, pvalue = pearsonr(xs, ys)
# Display the correlation
print(correlation)
<script.py> output:
2.5478751053409354e-17
2.3intrinsic dimension
主成分的固有维度,其实就是提取主成分,得到最佳线性组合
2.3.1 提取主成分
.n_components_
提取主成分一般占总的80%以上,不过具体问题还得具体分析
# Perform the necessary imports
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
import matplotlib.pyplot as plt
# Create scaler: scaler
scaler = StandardScaler()
# Create a PCA instance: pca
pca = PCA()
# Create pipeline: pipeline
pipeline = make_pipeline(scaler,pca)
# Fit the pipeline to 'samples'
pipeline.fit(samples)
# Plot the explained variances
features =range( pca.n_components_)
plt.bar(features, pca.explained_variance_)
plt.xlabel('PCA feature')
plt.ylabel('variance')
plt.xticks(features)
plt.show()

2.3.2Dimension reduction with PCA
主成分降维
给一个文本特征提取的小例子
虽然我还不知道这个是啥,以后学完补充啊
# Import TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
# Create a TfidfVectorizer: tfidf
tfidf = TfidfVectorizer()
# Apply fit_transform to document: csr_mat
csr_mat = tfidf.fit_transform(documents)
# Print result of toarray() method
print(csr_mat.toarray())
# Get the words: words
words = tfidf.get_feature_names()
# Print words
print(words)
['cats say meow', 'dogs say woof', 'dogs chase cats']
<script.py> output:
[[0.51785612 0. 0. 0.68091856 0.51785612 0. ]
[0. 0. 0.51785612 0. 0.51785612 0.68091856]
[0.51785612 0.68091856 0.51785612 0. 0. 0. ]]
['cats', 'chase', 'dogs', 'meow', 'say', 'woof']
<script.py> output:
[[0.51785612 0. 0. 0.68091856 0.51785612 0. ]
[0. 0. 0.51785612 0. 0.51785612 0.68091856]
[0.51785612 0.68091856 0.51785612 0. 0. 0. ]]
['cats', 'chase', 'dogs', 'meow', 'say', 'woof']
t-SNE and PCA的更多相关文章
- Probabilistic PCA、Kernel PCA以及t-SNE
Probabilistic PCA 在之前的文章PCA与LDA介绍中介绍了PCA的基本原理,这一部分主要在此基础上进行扩展,在PCA中引入概率的元素,具体思路是对每个数据$\vec{x}_i$,假设$ ...
- 用scikit-learn学习主成分分析(PCA)
在主成分分析(PCA)原理总结中,我们对主成分分析(以下简称PCA)的原理做了总结,下面我们就总结下如何使用scikit-learn工具来进行PCA降维. 1. scikit-learn PCA类介绍 ...
- 主成分分析(PCA)原理总结
主成分分析(Principal components analysis,以下简称PCA)是最重要的降维方法之一.在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用.一般我们提到降维最容易想到的算法就 ...
- 机器学习基础与实践(三)----数据降维之PCA
写在前面:本来这篇应该是上周四更新,但是上周四写了一篇深度学习的反向传播法的过程,就推迟更新了.本来想参考PRML来写,但是发现里面涉及到比较多的数学知识,写出来可能不好理解,我决定还是用最通俗的方法 ...
- 数据降维技术(1)—PCA的数据原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
- 深度学习笔记——PCA原理与数学推倒详解
PCA目的:这里举个例子,如果假设我有m个点,{x(1),...,x(m)},那么我要将它们存在我的内存中,或者要对着m个点进行一次机器学习,但是这m个点的维度太大了,如果要进行机器学习的话参数太多, ...
- PCA、ZCA白化
白化是一种重要的预处理过程,其目的就是降低输入数据的冗余性,使得经过白化处理的输入数据具有如下性质:(i)特征之间相关性较低:(ii)所有特征具有相同的方差. 白化又分为PCA白化和ZCA白化,在数据 ...
- PCA 协方差矩阵特征向量的计算
人脸识别中矩阵的维数n>>样本个数m. 计算矩阵A的主成分,根据PCA的原理,就是计算A的协方差矩阵A'A的特征值和特征向量,但是A'A有可能比较大,所以根据A'A的大小,可以计算AA'或 ...
- 【统计学习】主成分分析PCA(Princple Component Analysis)从原理到实现
[引言]--PCA降维的作用 面对海量的.多维(可能有成百上千维)的数据,我们应该如何高效去除某些维度间相关的信息,保留对我们"有用"的信息,这是个问题. PCA给出了我们一种解决 ...
- 主成分分析 (PCA) 与其高维度下python实现(简单人脸识别)
Introduction 主成分分析(Principal Components Analysis)是一种对特征进行降维的方法.由于观测指标间存在相关性,将导致信息的重叠与低效,我们倾向于用少量的.尽可 ...
随机推荐
- mybaitis的延迟加载
概念:延迟加载:用到的时候才加载 因为我们在多表查询是,效率不如单表快,多个单表查询,然后使用懒加载,完成 多表关联查询 什么情况下使用懒加载 mybaitis中的表关系是一对一或者一对多的时候 我们 ...
- 【OpenGL】GL_DEPTH_TEST深度测试问题
记录一个深度测试的问题 在实现一个简单的OpenGL程序时,遇到了一个问题,深度测试总是有问题,无法正常显示,如下 正常情况为 通过调试发现屏幕空间中的所有深度值均为1. OpenGL代码如下: vo ...
- Xamarin.Forms 二维码扫描实践
开发环境: Visual Studio 2019 版本 16.4.5 公用平台nuget ZXing.Net.Mobile.Forms 2.4.1 Plugin.Permissions 5.0.0-b ...
- 《C# GDI+ 破境之道》:第一境 GDI+基础 —— 第二节:画矩形
有了上一节画线的基础,画矩形的各种边线就特别好理解了,所以,本节在矩形边线上,就不做过多的讲解了,关注一下画“随机矩形”的具体实现就好.与画线相比较,画矩形稍微复杂的一点就是在于它多了很多填充的样式. ...
- Python3(十) 函数式编程: 匿名函数、高阶函数、装饰器
一.匿名函数 1.定义:定义函数的时候不需要定义函数名 2.具体例子: #普通函数 def add(x,y): return x + y #匿名函数 lambda x,y: x + y 调用匿名函数: ...
- k8s系列---ingress资源和ingress-controller
https://www.cnblogs.com/zhangeamon/p/7007076.html http://blog.itpub.net/28916011/viewspace-2214747/ ...
- Bookshelf 2 01背包
B - Bookshelf 2 Time Limit:1000MS Memory Limit:65536KB 64bit IO Format:%lld & %llu Submi ...
- getElementsByName和getElementById获取控件
js对控件的操作通常使用getElementsByName或getElementById来获取不同的控件进行操作 getElementsByName() 得到的是一个array, 不能直接设value ...
- C语言:字符串拷贝(截取)、查找
C语言:字符串拷贝(截取).查找 很惭愧,学了这么久别的语言,一直没有好好学C和C++,所以现在开始认真C/C++的一些特性和比较,这里记录下C语言拷贝和截取的一些方式,由于系统库带的函数不方便,所以 ...
- Mybatis注解开发多表一对一,一对多
Mybatis注解开发多表一对一,一对多 一对一 示例:帐户和用户的对应关系为,多个帐户对应一个用户,在实际开发中,查询一个帐户并同时查询该账户所属的用户信息,即立即加载且在mybatis中表现为一对 ...