hadoop学习笔记(六):hadoop全分布式集群的环境搭建
本文原创,如需转载,请注明作者以及原文链接!
一、前期准备:
1、jdk安装 不要用centos7自带的openJDK
2、hostname 配置 配置位置:/etc/sysconfig/network文件
3、hosts 配置 配置位置 : /etc/hosts
4、date 配置 date -s "....."设置日期一致
5、 关闭安全机制 /etc/sysconfig/selinux
6、 关闭防火墙:firewall iptables off
7、映射文件更改 :windows 域名映射 /etc/hosts文件
本环境的搭建角色:主结点node01,从结点node02,、node03,、node04,第二主节点secondaryNameNode的位置:node02
密匙文件分发到从结点
分发命令举例:
[root@node01 hadoop-2.6.]# scp id_dsa.pub node02:`pwd`/node01.pub
这些都设置好了之后才具备全分布式搭建的条件
二、环境搭建
节点: node01/02/03/04全分布分配方案:
NN SNN DN
NODE01 *
NODE02 * *
NODE03 *
NODE04 *
节点状态:
node01: 伪分布
node02/03/04 : ip配置完成
建立各节点通讯(hosts) 可以通过Ping 结点主机的别名来检查是否结点之间能够通讯成功
设置时间同步:date -s “xxxx-x-xx xx:xx:xx”
秘钥分发:
在每个节点上登录一下自己:产生.ssh目录 ------------------------具体的从新登陆代码:
从node01向node02/node03/node04分发公钥 (公钥的名称要变化)
scp id_dsa.pub node03:`pwd`/node06.pub ---------------------》要明白这里的主结点分发给从结点的公钥文件的名称为啥要变化,是为了如果有其他的结 点 也想要管理这个几点的话, 也会发公钥文件给从结点,如果不改名的话,第二个管理结 点的分发的公钥文件会覆盖掉第一个下发的公钥文件。
各节点把node01的公钥追加到认证文件里:
cat ~/node06.pub >> ~/.ssh/authorized_keys ----------------------》这样之后才会能够实现主结点到从结点的免密登录
node02/node03/node04安装jdk环境,node01分发profile给其他节点,并重读配置文件 :通过source 或者. /etc/profile的形式
分发hadoop部署程序2.6.5 到其他节点
copy node06 下的 hadoop 为 hadoop-local (管理脚本只会读取hadoop目录)
[root@node06 etc]# cp -r hadoop/ hadoop-pesudo --------------->作为分布式集群的备份目录,如果以后想要启动伪分布式集群的话,则可以将这个备份文件改名为hadoop
配置core-site.xml ---------------------》需要配置的是产生的dataNode、DataNode等结点的数据文件,如fsimage文件的位置
配置hdfs-site.xml ---------------------》配置从结点的个数和,第二主结点的位置,如可以将第二个主结点放到其他的某个从结点的位置 之上
配置slaves
分发sxt目录以及他一下的所有的内容及目录 到其他07,08,09节点 ----------------》这样做的好处就是,不用在其他的每个从结点上再去一一的建立一个相同的目录了
格式化集群:hdfs namenode -format ----------------->注意这里格式化完毕之后仅仅是产生一个头结点的数据文件,其他的服务器上 的从结点的数据文 件 和存放数据文件的目录是集群启动的时候才会产生的
至此集群搭建完毕!!!
三、集群启动
启动集群:start-dfs.sh
Jps 查看各节点进程启动情况
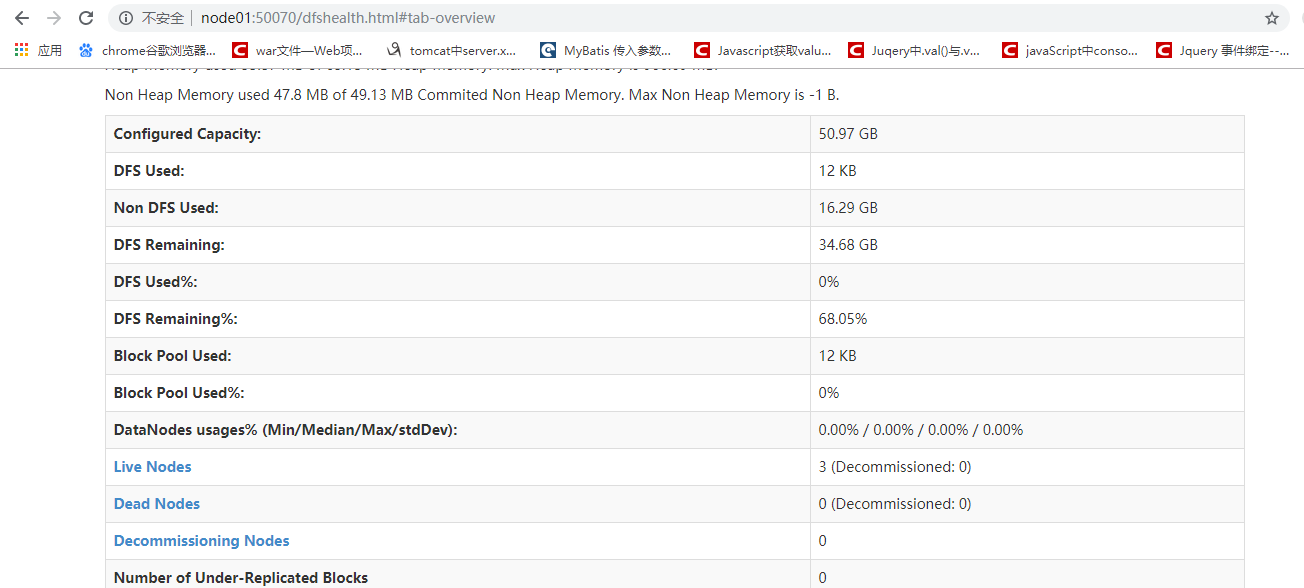
之后如果想要浏览器访问集群的话,需要查询集群和浏览器交互的端口号,一般是50070 ------------》ss -nal
浏览器成功的访问分布式存储系统
四、文件上传
- 上传文件到分布式存储系统
先创建一个用于上传的1.4M大小的文件
[root@node01 hadoop-2.6.]# for i in `seq `;do echo "hello sxt $i" >> test.txt;done
效果

具体的对于上传的文件的分割的大小可以做规定,一般的是默认128M每一块,我们可以通过以下的命令来设置
命令意义:将test.txt文件分割上传,并设置分割大小为1M,所以比如这个文件的总的大小是1.4M 的话,会分成两块
[root@node01 software]# hdfs dfs -D dfs.blocksize= -put test.txt
上传之后的效果
1)从浏览器上看
块1的存储效果
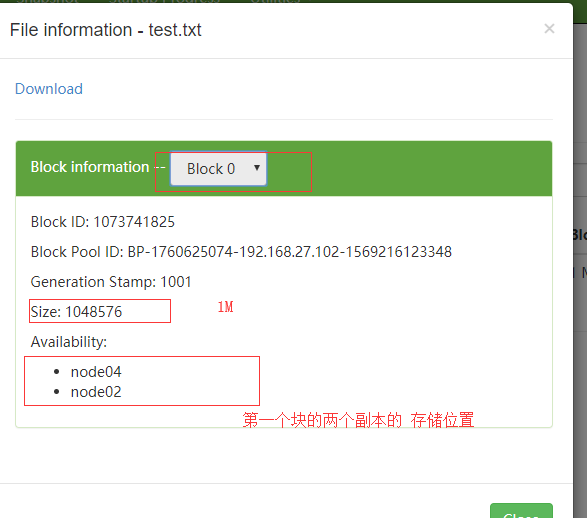
块2的存储效果

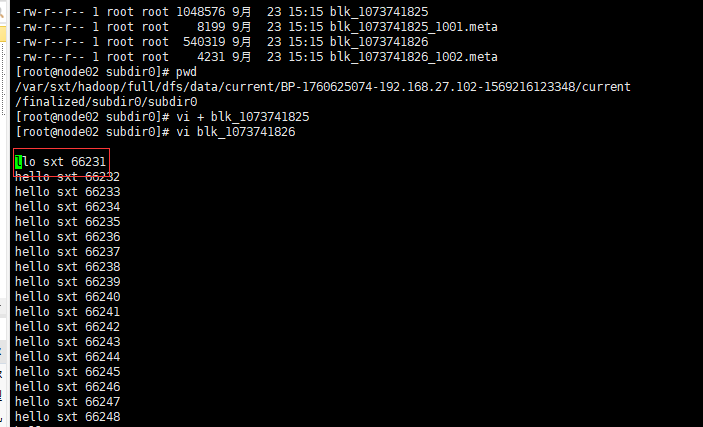
2)从xshell中看
输入命令
所在目录:存储有数据块的从结点的/var/sxt/hadoop/full/dfs/data/current/BP-1760625074-192.168.27.102-1569216123348/current路径下的文件,如下图

打开底层存储的文本文件test.txt 的blk_107341825的效果
block0

block1
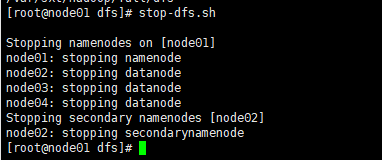
集群停止:
[root@node01 dfs]# stop-dfs.sh
hadoop学习笔记(六):hadoop全分布式集群的环境搭建的更多相关文章
- hadoop学习笔记(九):mr2HA高可用环境搭建及处步使用
本文原创,如需转载,请注明原文链接和作者 所用到的命令的总结: yarn:启动start-yarn.sh 停止stop-yarn.sh zk :zkServer.start ;:zkServer. ...
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- Hadoop(三)搭建Hadoop全分布式集群
原文地址:http://www.cnblogs.com/zhangyinhua/p/7652686.html 阅读目录(Content) 一.搭建Hadoop全分布式集群前提 1.1.网络 1.2.安 ...
- [转帖]hadoop学习笔记:hadoop文件系统浅析
hadoop学习笔记:hadoop文件系统浅析 https://www.cnblogs.com/sharpxiajun/archive/2013/06/15/3137765.html 1.什么是分布式 ...
- Elastic Stack之ElasticSearch分布式集群yum方式搭建
Elastic Stack之ElasticSearch分布式集群yum方式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搜索引擎及Lucene基本概念 1>.什么 ...
- centos 8 集群Linux环境搭建
一.集群Linux环境搭建 1. 注意事项 1.1 windows系统确认所有的关于VmWare的服务都已经启动 打开任务管理器->服务,查看五个VM选项是否打开. 1.2 确认好VmWare生 ...
- 吴裕雄--天生自然HADOOP学习笔记:hadoop集群实现PageRank算法实验报告
实验课程名称:大数据处理技术 实验项目名称:hadoop集群实现PageRank算法 实验类型:综合性 实验日期:2018年 6 月4日-6月14日 学生姓名 吴裕雄 学号 15210120331 班 ...
- Hadoop上路-01_Hadoop2.3.0的分布式集群搭建
一.配置虚拟机软件 下载地址:https://www.virtualbox.org/wiki/downloads 1.虚拟机软件设定 1)进入全集设定 2)常规设定 2.Linux安装配置 1)名称类 ...
- 暑假第二弹:基于docker的hadoop分布式集群系统的搭建和测试
早在四月份的时候,就已经开了这篇文章.当时是参加数据挖掘的比赛,在计科院大佬的建议下用TensorFlow搞深度学习,而且要在自己的hadoop分布式集群系统下搞. 当时可把我们牛逼坏了,在没有基础的 ...
随机推荐
- 搭建 Review Board - SVN 审核工具
一.安装环境 CentOS-6.7,ReviewBoard-2.5.1.1 二.安装环境的配置 1.确认当前系统中有如下包,若没有,使用yum安装 httpd-2.2.15:httpd 指的是apac ...
- 到头来还是逃不开Java - Java13核心类
Java13核心类 没有特殊说明,我的所有学习笔记都是从廖老师那里摘抄过来的,侵删 引言 兜兜转转到了大四,学过了C,C++,C#,Java,Python,学一门丢一门,到了最后还是要把Java捡起来 ...
- JS的冒泡事件
在一个对象上触发某类事件(比如单击onclick事件),如果此对象定义了此事件的处理程序,那么此事件就会调用这个处理程序,如果没有定义此事件处理程序或者事件返回true,那么这个事件会向这个对象的 ...
- 在GPU上训练数据
在GPU上训练数据 模型搬到GPU上 数据搬到GPU上 损失函数计算搬到GPU上
- Windows下解决github push failed (remote: Permission to userA/XXXX.git denied to userB.) 上传gitHub失败报错
Windows环境下解决 github push failed (remote: Permission to userA/XXXX.git denied to userB.) · 初学GitHub的朋 ...
- window使用pycharm远程连接服务器
1.进入pycharm, File->Settings->Deployment下: 1.新加一个Server,type为SFTP,name自定义一个,例如UI自动化项目: 2.在SFTP ...
- FPGA设计的注意事项
设计文档 一个完整的软件是由程序. 数据和文档三部分组成的. 在FPGA电路设计中, 撰写完善的设计文档是非常重要的. 对于一个比较复杂的设计来说, 各个子单元的功能各不相同, 实现的方法也不一样,各 ...
- CSS的长度单位
对于css的长度单位真的有必要知道一下.那么css长度单位有哪些呢? 分成两大类: 1.绝对单位:不会因为其他元素的尺寸变化而变化.坚持自我. 2.相对单位:没有一个确定的值,而是由其他元素的尺寸影响 ...
- Java必须知道的知识点
junit用法,before,beforeClass,after, afterClass的执行顺序 分布式锁 nginx的请求转发算法,如何配置根据权重转发 用hashmap实现redis有什么问题( ...
- java+layui的Excel导入导出
html: <button class="layui-btn" onclick="exportData();">导出</button> ...