【48】数据扩充(Data augmentation)
数据扩充(Data augmentation)
大部分的计算机视觉任务使用很多的数据,所以数据扩充是经常使用的一种技巧来提高计算机视觉系统的表现。我认为计算机视觉是一个相当复杂的工作,你需要输入图像的像素值,然后弄清楚图片中有什么,似乎你需要学习一个复杂方程来做这件事。
在实践中,更多的数据对大多数计算机视觉任务都有所帮助,不像其他领域,有时候得到充足的数据,但是效果并不怎么样。但是,当下在计算机视觉方面,计算机视觉的主要问题是没有办法得到充足的数据。
对大多数机器学习应用,这不是问题,但是对计算机视觉,数据就远远不够。所以这就意味着当你训练计算机视觉模型的时候,数据扩充会有所帮助,这是可行的,无论你是使用迁移学习,使用别人的预训练模型开始,或者从源代码开始训练模型。让我们来看一下计算机视觉中常见的数据扩充的方法。

或许最简单的数据扩充方法就是垂直镜像对称,假如,训练集中有上面这张图片,然后将其翻转得到右边的图像。对大多数计算机视觉任务,左边的图片是猫,然后镜像对称仍然是猫,如果镜像操作保留了图像中想识别的物体的前提下,这是个很实用的数据扩充技巧。

另一个经常使用的技巧是随机裁剪,给定一个数据集,然后开始随机裁剪,可能修剪这个(编号1),选择裁剪这个(编号2),这个(编号3),可以得到不同的图片放在数据集中,你的训练集中有不同的裁剪。随机裁剪并不是一个完美的数据扩充的方法,如果你随机裁剪的那一部分(红色方框标记部分,编号4),这部分看起来不像猫。但在实践中,这个方法还是很实用的,随机裁剪构成了很大一部分的真实图片。
镜像对称和随机裁剪是经常被使用的。
当然,理论上,你也可以使用旋转,剪切(shearing:此处并非裁剪的含义,图像仅水平或垂直坐标发生变化)图像,可以对图像进行这样的扭曲变形,引入很多形式的局部弯曲等等。当然使用这些方法并没有坏处,尽管在实践中,因为太复杂了所以使用的很少。
第二种经常使用的方法是彩色转换,有这样一张图片,然后给R、G和B三个通道上加上不同的失真值。
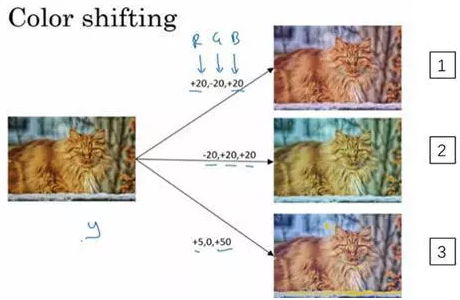
在这个例子中(编号1),要给红色、蓝色通道加值,给绿色通道减值。红色和蓝色会产生紫色,使整张图片看起来偏紫,这样训练集中就有失真的图片。为了演示效果,我对图片的颜色进行改变比较夸张。在实践中,对R、G和B的变化是基于某些分布的,这样的改变也可能很小。
这么做的目的就是使用不同的R、G和B的值,使用这些值来改变颜色。在第二个例子中(编号2),我们少用了一点红色,更多的绿色和蓝色色调,这就使得图片偏黄一点。
在这(编号3)使用了更多的蓝色,仅仅多了点红色。在实践中,R、G和B的值是根据某种概率分布来决定的。这么做的理由是,可能阳光会有一点偏黄,或者是灯光照明有一点偏黄,这些可以轻易的改变图像的颜色,但是对猫的识别,或者是内容的识别,以及标签y,还是保持不变的。所以介绍这些,颜色失真或者是颜色变换方法,这样会使得你的学习算法对照片的颜色更改更具鲁棒性。
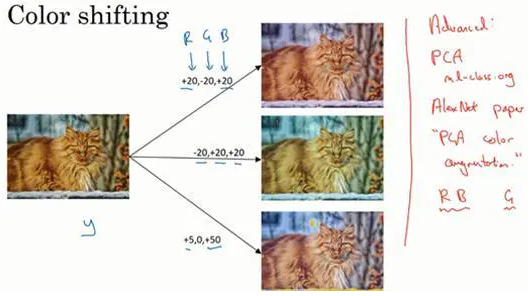
这是对更高级的学习者的一些注意提醒,你可以不理解我用红色标出来的内容。
对R、G和B有不同的采样方式,其中一种影响颜色失真的算法是PCA,即主成分分析,但具体颜色改变的细节在AlexNet的论文中有时候被称作PCA颜色增强,PCA颜色增强的大概含义是,比如说,如果你的图片呈现紫色,即主要含有红色和蓝色,绿色很少,然后PCA颜色增强算法就会对红色和蓝色增减很多,绿色变化相对少一点,所以使总体的颜色保持一致。如果这些你都不懂,不需要担心,可以在网上搜索你想要了解的东西,如果你愿意的话可以阅读AlexNet论文中的细节,你也能找到PCA颜色增强的开源实现方法,然后直接使用它。
你可能有存储好的数据,你的训练数据存在硬盘上,然后使用符号,这个圆桶来表示你的硬盘。如果你有一个小的训练数据,你可以做任何事情,这些数据集就够了。
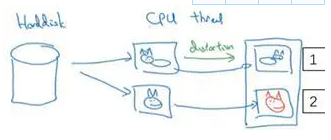
但是你有特别大的训练数据,接下来这些就是人们经常使用的方法。你可能会使用CPU线程,然后它不停的从硬盘中读取数据,所以你有一个从硬盘过来的图片数据流。你可以用CPU线程来实现这些失真变形,可以是随机裁剪、颜色变化,或者是镜像。但是对每张图片得到对应的某一种变形失真形式,看这张图片(编号1),对其进行镜像变换,以及使用颜色失真,这张图最后会颜色变化(编号2),从而得到不同颜色的猫。
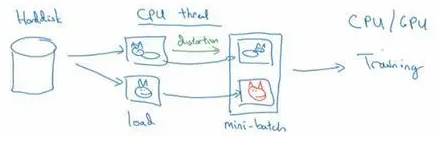
与此同时,CPU线程持续加载数据,然后实现任意失真变形,从而构成批数据或者最小批数据,这些数据持续的传输给其他线程或者其他的进程,然后开始训练,可以在CPU或者GPU上实现训一个大型网络的训练。
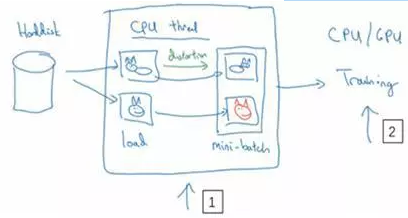
常用的实现数据扩充的方法是使用一个线程或者是多线程,这些可以用来加载数据,实现变形失真,然后传给其他的线程或者其他进程,来训练这个(编号2)和这个(编号1),可以并行实现。
这就是数据扩充,与训练深度神经网络的其他部分类似,在数据扩充过程中也有一些超参数,比如说颜色变化了多少,以及随机裁剪的时候使用的参数。
与计算机视觉其他部分类似,一个好的开始可能是使用别人的开源实现,了解他们如何实现数据扩充。当然如果你想获得更多的不变特性,而其他人的开源实现并没有实现这个,你也可以去调整这些参数。因此,我希望你们可以使用数据扩充使你的计算机视觉应用效果更好。
【48】数据扩充(Data augmentation)的更多相关文章
- 图像数据增强 (Data Augmentation in Computer Vision)
1.1 简介 深层神经网络一般都需要大量的训练数据才能获得比较理想的结果.在数据量有限的情况下,可以通过数据增强(Data Augmentation)来增加训练样本的多样性, 提高模型鲁棒性,避免过拟 ...
- Python数据增强(data augmentation)库--Augmentor 使用介绍
Augmentor 使用介绍 原图 random_distortion(probability, grid_height, grid_width, magnitude) 最终选择参数为 p.rando ...
- 常见的数据扩充(data augmentation)方法
G~L~M~R~S 一.data augmentation 常见的数据扩充(data augmentation)方法:文中图片均来自吴恩达教授的deeplearning.ai课程 1.Mirrorin ...
- Keras Data augmentation(数据扩充)
在深度学习中,我们经常需要用到一些技巧(比如将图片进行旋转,翻转等)来进行data augmentation, 来减少过拟合. 在本文中,我们将主要介绍如何用深度学习框架keras来自动的进行data ...
- keras对图像数据进行增强 | keras data augmentation
本文首发于个人博客https://kezunlin.me/post/8db507ff/,欢迎阅读最新内容! keras data augmentation Guide code # import th ...
- 论文解读(GraphDA)《Data Augmentation for Deep Graph Learning: A Survey》
论文信息 论文标题:Data Augmentation for Deep Graph Learning: A Survey论文作者:Kaize Ding, Zhe Xu, Hanghang Tong, ...
- Regularizing Deep Networks with Semantic Data Augmentation
目录 概 主要内容 代码 Wang Y., Huang G., Song S., Pan X., Xia Y. and Wu C. Regularizing Deep Networks with Se ...
- Oracle数据泵(Data Dump)错误汇集
Oracle数据泵(Data Dump)使用过程当中经常会遇到一些奇奇怪怪的错误案例,下面总结一些自己使用数据泵(Data Dump)过程当中遇到的问题以及解决方法.都是在使用过程中遇到的问题,以后陆 ...
- 深度学习中的Data Augmentation方法(转)基于keras
在深度学习中,当数据量不够大时候,常常采用下面4中方法: 1. 人工增加训练集的大小. 通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据.也就是Data Augm ...
随机推荐
- CTF--HTTP服务--SQL注入GET参数
开门见山 1. 扫描靶机ip,发现PCS 192.168.31.37 2. 用nmap扫描开放端口信息 3. 快速扫描全部信息 4. 探测敏感信息 5. 用浏览器打开用户登录页面 6. 使用OWASP ...
- STM8 关闭PWM输出后的电平输出问题解决
STM系列的单片机PWM输出如果被关断比如用TIM1_CtrlPWMOutputs进行停止输出后,电平的高低处于不确定的状态. 他取决于: 1.GPIO初始化的特性 2.关断那一刻时的电平 3.CCM ...
- python 不可变字典 inmutabledict的实现
python inmutabledict的实现 关于在python中如何实现不可变字典的方法.早在pep416中,就建议python官方实现inmutabledict,但是官方否认了.理由主要是 根据 ...
- .windows模拟linux命令iostat的显示
脚本如下: #!/usr/bin/env python #coding:utf- import win32com.client import time def disk_status(): try: ...
- f(n)=1-1/2+1/3-1/4...+1/n
#include <stdio.h>//f(n)=1+1/1+1/2+1/3+...+1/n int main(){ int n,i; double sum=0.0; scanf(&quo ...
- JavaScript所有函数和内置方法
Number isFiniter() 检测传入的的数值是否在无穷大和无穷小之间(有限数字或者是可转换成有限数字)返回true,否则返回false.NaN返回false. isFinite(Number ...
- 《Android Studio实战 快速、高效地构建Android应用》--三、重构代码
要成为高效的Android程序员,需要头脑灵活,能够在开发.调试和测试的过程中重构代码,重构代码最大的风险是可能会引入意外的错误,Android Studio通过分析某些具有危险性的重构操作来降低风险 ...
- Codeforces 1065C Make It Equal (差分+贪心)
题意:n个塔,第i个塔由$h_i$个cube组成,每次可以切去某高度h以上的最多k个cube,问你最少切多少次,可以让所有塔高度相等 k>=n, n<=2e5 思路:差分统计每个高度i有的 ...
- 机器学习(ML)十二之编码解码器、束搜索与注意力机制
编码器—解码器(seq2seq) 在自然语言处理的很多应用中,输入和输出都可以是不定长序列.以机器翻译为例,输入可以是一段不定长的英语文本序列,输出可以是一段不定长的法语文本序列,例如 英语输入:“T ...
- 【Java并发工具类】StampedLock:比读写锁更快的锁
前言 ReadWriteLock适用于读多写少的场景,允许多个线程同时读取共享变量.但在读多写少的场景中,还有更快的技术方案.在Java 1.8中, 提供了StampedLock锁,它的性能就比读写锁 ...