GHM论文笔记(CVPR2019)
目录
作者要解决的问题
仍然是one-stage中的一个经典问题,正负、难易样本不均衡。因为anchor的原因,pos : neg>= 1 : 70。负样本大多比较简单,所以也导致了难易样本的问题。
Focal loss(CVPR2017)
Focal loss的解决方案
传统的交叉熵损失函数:
\[
L_{CE} = -[p^*(log(p) + (1-p^*)log(1-p)]
\]
\(p^*=\{0, 1\}\)为真实标签,\(p \in (0, 1)\)为网络的预测概率。可以看到,传统的交叉熵损失函数平等的看待正负样本。
Focal loss
\[
L = -[\alpha p^\gamma p^*log(p) + (1-\alpha)(1-p)^\gamma (1-p^*)log(1-p)]
\]
可以看到Focal loss引入了两个超参数\(\alpha, \gamma\),\(\alpha\)用来平衡正负样本,\(\gamma\)用来平衡难易样本。简单分析一下,加号的左侧是正样本的损失,右侧是负样本的损失。通过乘上不同的系数\((\alpha, 1-\alpha)\),来平衡正负样本。对于简单样本,其loss较小,概率值更接近真实标签,这样概率的\(\gamma\)次方越小,相反地,难样本的就会变大,使难样本的损失上升,使网络关注难样本。
Focal loss的不足
虽然Focal loss这篇论文也在一定程度上解决了正负样本不均衡的问题,但是Focal loss引入了两个超参数,调参费劲,且只能应用到box分类上,无法解决回归的问题。
设计思路
梯度与样本的关系
作者观察到难易样本的分布与梯度有着如下的关系,可以看到,梯度较小时(简单样本),样本数量非常多,梯度适中时,样本较少。另外值得注意的一点是,梯度在1左右的样本数量还是不少的。作者将这些样本视为异常值,解决特别难的样本会导致其他的样本准确率下降。
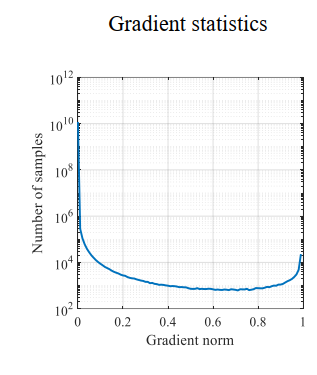
针对以上发现,作者采用梯度分布(梯度附近的样本数)来处理难易样本不平衡的问题。简单思路就是梯度小的样本数比较大,那就给他们乘上一个小系数,梯度大的样本少乘以一个大的系数。不过这个系数不是靠自己调的,而是根据样本的梯度分布来确定的。
梯度分布计算方法:将0-1的梯度切bin,计算每个bin内落入的样本数量。
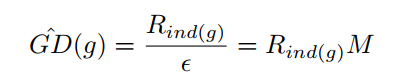
其中\(\epsilon\)是每个bin的宽度,\(M\)是\(\epsilon\)的倒数,表示将0-1切分成多少个bin,\(R_{ind(g)}\)表示每个bin内落入的样本数,计算方法如下:
\[
R_{ind(g)} = \sum_{k=1}^{N} \delta(g_k,g) \quad \delta(g_k,g) =
\begin{cases}
1 \quad if \quad g-\frac{\epsilon}{2} <= g_k <= g+\frac{\epsilon}{2}\\
0 \quad otherwise
\end{cases}
\]
\[
\beta_i = \frac{N}{GD(g_i)}
\]
\(g\)是某点的梯度模,可以理解为以这一点创建一个bin,\(g_k\)是样本的梯度模,N是样本总数。
从上面式子可以看到,梯度分布越大,系数越小。
梯度模计算方法
具体的在二分类中,损失函数为上面提到的交叉熵函数
\[
L_{CE} = -[p^*(log(p) + (1-p^*)log(1-p)] \\
p=sigmoid(x)
\]
对x的梯度
\[
\begin{aligned}\frac{\partial L_{CE}}{\partial x} &= \frac{\partial L_{CE}}{\partial p} \times \frac{\partial p}{\partial x}\\&= (-\frac{p^*}{p} + \frac{1-p^*}{1-p}) \times p(1-p)\\&= p-p^*\end{aligned}
\]
定义梯度模\(g = |p-p^*|\)
改进
GHM-C损失函数
由此,作者提出分类的损失函数GHM-C
\[
L_{GHM-C} = \frac{1}{N}\sum\beta_i L_{CE}(p_i, p_{i}^{*})
\]
还是以这个图为例,在梯度较小时,样本数较大,梯度分布\(GD(g)\)较大,则系数较小,损失较小,这样就有效的减少了大量简单样本的作用。反之亦然。同样可以分析出特别难的样本也被抑制了。这一点也是作者希望看到的。
下面这张图的横坐标代表原先的梯度分布,纵坐标代表处理后的梯度分布。对比未经任何处理的CE曲线,在0附近的梯度,GHM-C处理后梯度被减小了,0.5左右的样本梯度被放大了,尤其值得一提的是,对于前面提到的异常样本,梯度同样被抑制了。对比Focal loss曲线,明显可以看出GHM-C更加优秀。

GHM-R损失函数
按理说像之前一样求下梯度分布就好了,不过这里有一个问题。
对于边框回归的传统损失函数smooth_L1
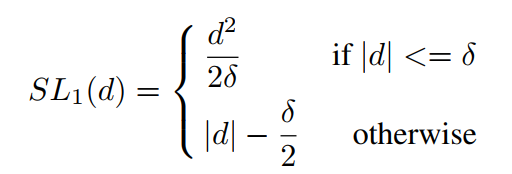
求梯度模
\(d= t_i - t_i^*\)
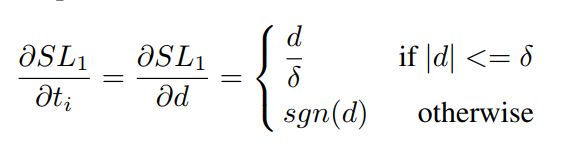
可以看到,当\(d>\delta\)时,梯度模横为1,无法衡量样本的难易程度。所以作者这里改了一下
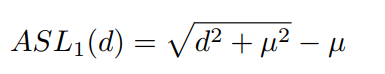
d比较小的时候,类似于\(L_2\),d较大时候类似\(L_2\),和\(SL_1\)类似。最终的损失函数如下:
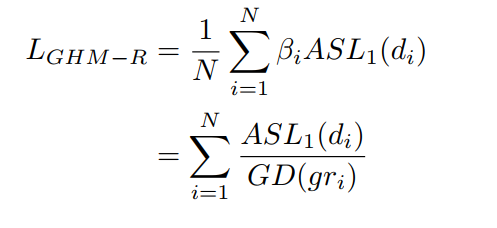
注意一点:回归的损失函数是只计算正样本的。
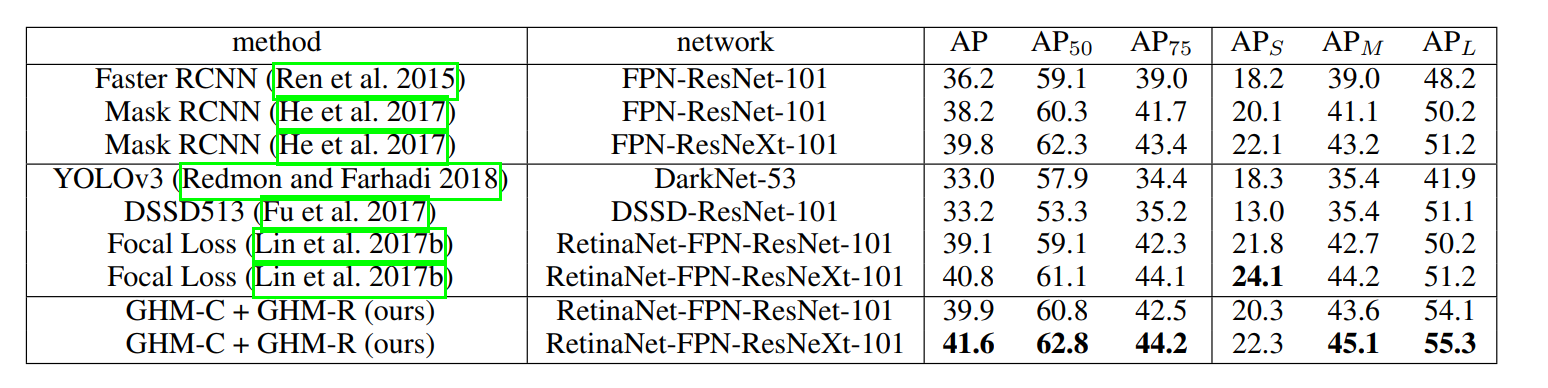
最终结果
COCO数据集上的比较
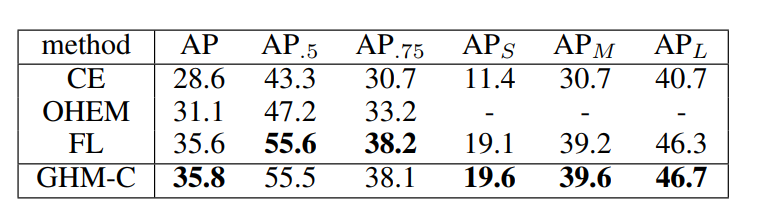
只有GHM-C的比较
只有GHM-R的比较

GHM论文笔记(CVPR2019)的更多相关文章
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
- 论文笔记(2):A fast learning algorithm for deep belief nets.
论文笔记(2):A fast learning algorithm for deep belief nets. 这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm ...
- 论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN
论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN ICCV 2017 Paper: http://op ...
随机推荐
- OpenResty学习指南(一)
我的博客: https://www.luozhiyun.com/archives/217 想要学好 OpenResty,你必须理解下面 8 个重点: 同步非阻塞的编程模式: 不同阶段的作用: LuaJ ...
- CORS解决跨域问题的几种方法
一 后端服务器使用过滤器 新建过滤器: /** * 解决跨域 */ public class AccessControlAllowOriginFilter implements Filter { @O ...
- CAD制图系列之怎么画平行线
CAD怎么画平行线 输入O,点空格,输入距离100,选择已知的线,往你要偏移的方向就好! 具体方法如下:1.打开CAD制图 2.输入快捷键O 3.按下空格键 4.输入你所要的距离,例如12,并按下空格 ...
- 我的一个react路由之旅(步骤及详图)
今天开始react一个重要部分的xiao~习,路由~(过程截图,最后附代码) 以下代码只能骗糊涂蛋子,没错,就是我自己,不要打算让我敲出多高级的东西~ 理论性知识几乎没有,请不要打算让我给你说原理啥的 ...
- ros机器人之小乌龟仿真-路径记录
------------恢复内容开始------------ 通过自己不断地摸索,对ros系统有了一定的了解,首先装系统,这一过程中也遇到了很多问题,但通过不断地尝试,经过一天一夜的倒腾,总算是把系统 ...
- 【MySQL 原理分析】之 Trace 分析 order by 的索引原理
一.背景 昨天早上,交流群有一位同学提出了一个问题.看下图: 我不是大佬,而且当时我自己的想法也只是猜测,所以并没有回复那位同学,只是接下来自己做了一个测试验证一下. 他只简单了说了一句话,就是同样的 ...
- SpringBoot项目版本升级:从1.5.3升级到2.1.8版本
SpringBoot项目版本升级:从1.5.3升级到2.1.8版本 前言 简单记录一次本人在自己的SpringBoot项目project-template中,把1.5.3版本升级到2.1.8版本时升级 ...
- sqlserver install on linux chapter one
Hello The MS open the source to let people download source. You may ask where to download ? Ask goog ...
- uniapp单页面配置无导航栏
{ "path": "pages/login/login", "style": { "navigationStyle": ...
- SpringBoot2.x操作缓存的新姿势
一.介绍 spring cache 是spring3版本之后引入的一项技术,可以简化对于缓存层的操作,spring cache与springcloud stream类似,都是基于抽象层,可以任意切换其 ...