后缀自动机&回文自动机学习笔记
在学了一天其实是边学边摆之后我终于大概$get$后缀自动机了,,,就很感动,于是时隔多年我终于决定再写篇学习笔记辽$QwQ$
$umm$和$FFT$学习笔记一样,这是一篇单纯的$gql$的知识总结博,对新手并不友好,想学$SAM$的话我是推荐几篇博客:1 2 3(没有$hihocoder$主要我$jio$得有点太理论化了,全是文字没有图其实我挺难看下去的然后也没那么形象比较难理解$kk$
然后因为我对纯文字的抽象知识点理解起来比较垃圾,,,所以全文可能会放比较多的图$QwQ$
先放个已经建好的$SAM$介绍下它的基本元素趴$QwQ$
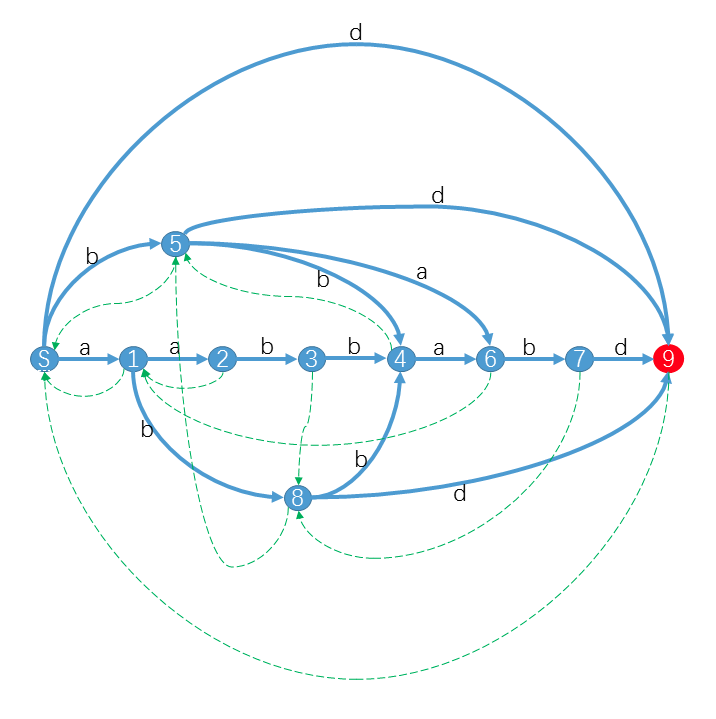
这个是字符串$aabbabd$的$SAM$.不难发现这个图总的有三个基本元素,分别是节点.绿线.蓝线
事实上$SAM$的核心也就这三个东西,我大概分别介绍下这三个东西$QwQ$
首先是节点.
我们先定义一个东西,叫$endpos(x)$,表示的字符串$x$的所有出现位置,这里的出现位置指的末端的出现位置$QwQ$
就理解为,$kmp$的时候所有匹配到$x$的末尾节点的位置$QwQ$
然后对于一个节点的定义就是所有$endpos$相等的$x$的集合.
拿这个$aabbabd$举例?$\{aabb,abb,bb\}$的$endpos$就都等于$\{ 4 \}$,$\{b\}$的$endpos$就等于$\{3,4,6\}$
昂然后关于节点几个常见性质记录下,只是证明的话就懒得证了,其实大部分都还挺满显然的?不明白的自己举个例子啥的就$get$了$QwQ$
1.对于同一个节点内的所有字符串都互为后缀.
依然拿$aabbabd$举例子?看到这个$aabb,abb,bb$,发现,嗷,确实互为后缀呢$QwQ$
然后说了没有证明,不过挺显然的我$jio$得其实还,,,
2.设$x_1$,$x_2$都是$S$的子串,不妨设$|x_1|<|x_2|$,则有.$x_1$是$x_2$的后缀当且仅当$endpos(x_1) \supseteq endpos(s_2)$.$x_1$不是$x_2$的后缀当且仅当$endpos(s_1) \cap endpos(s_2) = \emptyset$
这个挺好理解我就不举例子辽$QwQ$
3.设$substrings(st)$表示节点$st$包含的所有字符串,$longest(st)$表示节点$st$所有字符串中最长的一个,$shortest(st)$表示节点$st$所有字符串中最短的一个.则有对所有$x\in substrings(st)$,都是$longest(st)$的后缀
$umm$这个其实和第一个是差不多的我不说了$QwQ$
4.对于任意一个状态$st$,以及$longest(st)$的任意一个后缀$x$,当$|shortest(st)|\leq |x|\leq longest(st)$时有$x\in substrings(st)$.也就说$substrings(st)$实际上是$longest(st)$的一段连续后缀$w$
证明显然不明白自己随便举例趴$QwQ$
5.没了,,,?$QwQ$
然后是这个绿色的线
在前面港节点的性质的时候就港了说$substrings(st)$就$longest(st)$的一段连续后缀,所以考虑为什么在$shortest(st)$后面就断开辣?
就依然拿前面那个$\{aabb,abb,bb\}$港趴,发现继续看后缀应该就是$b$了,但是发现,$b$的$endpos$是$\{3,4,6\}$,也是出现新节点.然后再后面后缀是$\_$,$endpos$是$\{1,2,3,4,5,6,7\}$,于是又出现了新节点
也就说当$longest(st)$的某个后缀在其他位置出现时,就会断掉,然后出现新的节点
在这个图上的话是有,节点$S$是$\_$,节点5是$b$,节点4是$\{aabb,abb,bb\}$,于是连一条$4->5->S$的路径,表示的$longest(4)$即$aabb$的所有后缀依次在$4,5,S$中$QwQ$
对了,叫绿线,听起来就,有点捞,,,还是说下鸭,官方名字叫$Suffix\ Link$
最后说下蓝色的线
首先说另外一个东西,设$next(st)$表示节点$st$遇到的下一个字母的集合,即$next(st)=\{S[i+1],i\in endpos(st)\}$
然后关于这个$next(st)$有一个性质是说,将节点$st$中的所有字符串后面接上字符$c$之后,都依然属于同一个节点
所以定义一个$trans(st,c)$表示在节点$st$后面接上$c$之后指向的节点.
然后这个蓝线就是这个$trans$,蓝线上面的字母就$c$.
最后关于构建我就不说了,,,主要原理我还没有完全$get$(就分类讨论三个里面最复杂的那个,,,我还没$get$昂$kk$
所以我就不说了,只大概说下,就对每个节点要保存的只有$longset,shortest,suffix\ link,trans$,然后构造是用的增量法,即将元素一个个加进去$QwQ$
然后放下板子题代码$QwQ$
#include<bits/stdc++.h>
using namespace std;
#define il inline
#define ll long long
#define gc getchar()
#define mp make_pair
#define P pair<int,int>
#define ri register int
#define rc register char
#define rb register bool
#define w(i) edge[i].wei
#define rp(i,x,y) for(ri i=x;i<=y;++i)
#define my(i,x,y) for(ri i=x;i>=y;--i)
#define lb(x) lower_bound(b+1,b+1+num,x)-b
#define ub(x) upper_bound(b+1,b+1+num,x)-b const int N=+;
int lst=,tot=,t[N],A[N],sz[N];
ll as;
char str[N];
struct node{int fa,len,to[];}nod[N<<]; il int read()
{
rc ch=gc;ri x=;rb y=;
while(ch!='-' && (ch>'' || ch<''))ch=gc;
if(ch=='-')ch=gc,y=;
while(ch>='' && ch<='')x=(x<<)+(x<<)+(ch^''),ch=gc;
return y?x:-x;
}
il void extend(ri c)
{
ri p=lst,np=++tot;lst=np;sz[np]=;nod[np].len=nod[p].len+;
while(p && !nod[p].to[c])nod[p].to[c]=np,p=nod[p].fa;
if(!p)return void(nod[np].fa=);
ri q=nod[p].to[c];if(nod[p].len+==nod[q].len)return void(nod[np].fa=q);
ri nq=++tot;nod[nq]=nod[q];nod[nq].len=nod[p].len+;nod[q].fa=nod[np].fa=nq;
while(p && nod[p].to[c]==q)nod[p].to[c]=nq,p=nod[p].fa;
} int main()
{
//freopen("3802.in","r",stdin);freopen("3802.out","w",stdout);
scanf("%s",str+);ri len=strlen(str+);rp(i,,len)extend(str[i]-'a'+);
rp(i,,tot)t[nod[i].len]++;rp(i,,tot)t[i]+=t[i-];rp(i,,tot)A[t[nod[i].len]--]=i;
my(i,tot,){ri nw=A[i];sz[nod[nw].fa]+=sz[nw];if(sz[nw]>)as=max(as,1ll*sz[nw]*nod[nw].len);}
printf("%lld\n",as);
return ;
}
阿最后还是写几个基本应用趴$QwQ$
拓扑序
根据$len$排序,得到的就是$parent$树的$bfs$序,也是自动机的拓扑序
rp(i,,tot)t[nod[i].len]++;rp(i,,tot)t[i]+=t[i-];rp(i,,tot)A[t[nod[i].len]--]=i;
判断子串/后缀
在$SAM$上匹配,如果没有转移到$NULL$就是子串,如果转移到接受状态就是后缀
顺便说下匹配?考虑对查询串一个个字母查询,类似于$AC$自动机和$kmp$一样的,一直跳$fa$直到到根或者可以匹配位置.然后如果能匹配就匹配,否则重置$t$和$p$,最后如果匹配完成就加入答案就成$QwQ$
考虑对节点$x$,拥有的子串个数就$len[x]-len[fa[x]]$,然后$\sigema$下就成,$over$
#include<bits/stdc++.h>
using namespace std;
#define il inline
#define ll long long
#define gc getchar()
#define mp make_pair
#define P pair<int,int>
#define ri register int
#define rc register char
#define rb register bool
#define w(i) edge[i].wei
#define rp(i,x,y) for(ri i=x;i<=y;++i)
#define my(i,x,y) for(ri i=x;i>=y;--i)
#define lb(x) lower_bound(b+1,b+1+num,x)-b
#define ub(x) upper_bound(b+1,b+1+num,x)-b const int N=+;
int lst=,tot=,t[N],A[N],sz[N];
ll as;
char str[N];
struct node{int fa,len,to[];}nod[N<<]; il int read()
{
rc ch=gc;ri x=;rb y=;
while(ch!='-' && (ch>'' || ch<''))ch=gc;
if(ch=='-')ch=gc,y=;
while(ch>='' && ch<='')x=(x<<)+(x<<)+(ch^''),ch=gc;
return y?x:-x;
}
il void extend(ri c)
{
ri p=lst,np=++tot;lst=np;sz[np]=;nod[np].len=nod[p].len+;
while(p && !nod[p].to[c])nod[p].to[c]=np,p=nod[p].fa;
if(!p)return void(nod[np].fa=);
ri q=nod[p].to[c];if(nod[p].len+==nod[q].len)return void(nod[np].fa=q);
ri nq=++tot;nod[nq]=nod[q];nod[nq].len=nod[p].len+;nod[q].fa=nod[np].fa=nq;
while(p && nod[p].to[c]==q)nod[p].to[c]=nq,p=nod[p].fa;
} int main()
{
//freopen("3802.in","r",stdin);freopen("3802.out","w",stdout);
ri len=read();scanf("%s",str+);rp(i,,len)extend(str[i]-'a'+);
rp(i,,tot)as+=nod[i].len-nod[nod[i].fa].len;
printf("%lld\n",as);
return ;
}
先求出拓扑序,从而求出每个节点的$endpos$数量$QwQ$
然后就按着拓扑序求出每个节点的子树大小,然后就用逼近法就成$QwQ$
先给第一个串建一个$SAM$,然后匹配第二个串就成,$over$
字符串最小表示法
考虑先复制字符串并丢进$SAM$中,然后每次贪心走就行$over$
求两个前缀的最长公共后缀
$umm$答案就$len[lca(x,y)]$?过分显然了$QwQ$
(这个可以用在两个串求任意两点结尾的$lcs$,就接在一起中间加"#"就变成这个了$QwQ$
求任意子串出现个数
考虑一个子串在它及它的子树中出现?所以按拓扑序$dp$就完事$QwQ$
求模式串在文本串中的出现位置
预处理一个$parent$数的倍增和$endpos$大小($umm$这个其实直接$len[x]-len[fa[x]]$就是,,,?
然后扫描模式串,记录当前匹配到了第多少位,然后判断是否匹配完了.如果匹配完了就倍增往上跳到满足$len\geq$的最高位置,把这个位置的$endpos$集合大小统计到答案中
最后
众所周知会$SAM$就会$PAM$了
所以我顺便写下$PAM$的学习笔记趴$QwQ$
$umm$其实我$jio$得这和$SAM$没有太大关系,,,?比较像$kmp$昂$QwQ$,,,?
咕了明天写$QwQ$
后缀自动机&回文自动机学习笔记的更多相关文章
- 后缀自动机/回文自动机/AC自动机/序列自动机----各种自动机(自冻鸡) 题目泛做
题目1 BZOJ 3676 APIO2014 回文串 算法讨论: cnt表示回文自动机上每个结点回文串出现的次数.这是回文自动机的定义考查题. #include <cstdlib> #in ...
- 牛客多校第四场 I string 后缀自动机/回文自动机
这个回文自动机的板有问题,它虽然能过这道题,但是在计算size的时候会出锅! 题意: 求一个字符串中本质不同的连续子串有几个,但是某串和它反转后的字符串算一个. 题解: 要注意的是,一般字符串题中的“ ...
- BZOJ 3790 神奇项链(回文自动机+线段树优化DP)
我们预处理出来以i为结尾的最长回文后缀(回文自动机的构建过程中就可以求出)然后就是一个区间覆盖,因为我懒得写贪心,就写了线段树优化的DP. #include<iostream> #incl ...
- 回文树/回文自动机(PAM)学习笔记
回文树(也就是回文自动机)实际上是奇偶两棵树,每一个节点代表一个本质不同的回文子串(一棵树上的串长度全部是奇数,另一棵全部是偶数),原串中每一个本质不同的回文子串都在树上出现一次且仅一次. 一个节点的 ...
- 字符串数据结构模板/题单(后缀数组,后缀自动机,LCP,后缀平衡树,回文自动机)
模板 后缀数组 #include<bits/stdc++.h> #define R register int using namespace std; const int N=1e6+9; ...
- 省选算法学习-回文自动机 && 回文树
前置知识 首先你得会manacher,并理解manacher为什么是对的(不用理解为什么它是$O(n)$,这个大概记住就好了,不过理解了更方便做$PAM$的题) 什么是回文自动机? 回文自动机(Pal ...
- 回文树(回文自动机PAM)小结
回文树学习博客:lwfcgz poursoul 边写边更新,大概会把回文树总结在一个博客里吧... 回文树的功能 假设我们有一个串S,S下标从0开始,则回文树能做到如下几点: 1.求串S前缀0~ ...
- URAL 2040 Palindromes and Super Abilities 2 (回文自动机)
Palindromes and Super Abilities 2 题目链接: http://acm.hust.edu.cn/vjudge/contest/126823#problem/E Descr ...
- [模板] 回文树/回文自动机 && BZOJ3676:[Apio2014]回文串
回文树/回文自动机 放链接: 回文树或者回文自动机,及相关例题 - F.W.Nietzsche - 博客园 状态数的线性证明 并没有看懂上面的证明,所以自己脑补了一个... 引理: 每一个回文串都是字 ...
随机推荐
- Mybatis Generator配置文件完整配置详解
完整的Mybatis Generator(简称MBG)的最完整配置文件,带详解,再也不用去看EN的User Guide了 可以搭配着mybatis generator的中文文档看:http://mbg ...
- C++ 结构体的定义
struct 结构体名称{ 数据类型 A: 数据类型 B; }结构体变量名; 相当于: struct 结构体名称{ 数据类型 A: 数据类型 B; }; struct 结构体名 ...
- python -- 类中--内置方法
isinstance 和 issubclass isinstance(obj,b) 检查是否obj是否是类b的对象 class A(object):pass class B(A):pass b=B ...
- hdu 1358 Period (KMP求循环次数)
Problem - 1358 KMP求循环节次数.题意是,给出一个长度为n的字符串,要求求出循环节数大于1的所有前缀.可以直接用KMP的方法判断是否有完整的k个循环节,同时计算出当前前缀的循环节的个数 ...
- jq杂项方法/工具方法----trim() html() val() text() attr()
https://www.cnblogs.com/sandraryan/ $.trim() 函数用于去除字符串两端的空白字符.在中间的时候不会去掉. var str = ' 去除字符串左右两端的空格,换 ...
- Python--day70--ORM一对一表结构
ORM一对一表结构:
- 程序中打开IE浏览器并访问指定地址
最简单的方法 Process.Start("iexplore.exe"); //直接打开IE浏览器(打开默认首页) Process.Start(" ...
- H3C PPP MP配置示例三
- PHP两个变量值互换(不用第三变量)
<?php /** * 双方变量为数字或者字符串时 * 使用list()和array()方法可以达到交换变量值得目的 */ $a = "This is A"; // a ...
- 关于top命令
top命令交互操作指令 下面列出一些常用的 top命令操作指令 q:退出top命令 :立即刷新 s:设置刷新时间间隔 c:显示命令完全模式 t::显示或隐藏进程和CPU状态信息 m:显示或隐藏内存状态 ...