HBase 原理

- 逻辑数据模型

- 物理数据模型

- HBase所有行按照Rowkey进行字典排序,Table在行的方向分割为多个region

- Region 按照大小进行分割,每个table最初只有一个Region,随着数据的不断插入,Region不短增大,当增加到一定阈值后,从中间分裂成两个Region。 Table中的数据不断增加,就会有越来越的Region

- Region是HBase分布式存储和负载均衡的最小单元,一个region只能在一个RegionServer上。
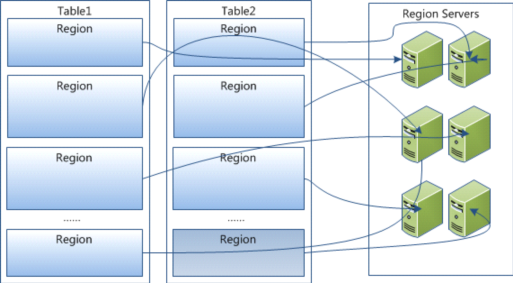
- Region虽然是分布式存储的最小单元,但不是存储的最小单元(内部有更详细的结构)。内部划分为多个Store,一个Store对应一个Column Family。 Store内部又分为一个MemStore和零到多个Storefile。Storefile以Hfile的形式存储在HDFS上

- 每个Region server 管理大约1000个HRegion。(Why:这个1000的数字应该是从BigTable的论文中来的(5 Implementation节):Each tablet server manages a set of tablets(typically we have somewhere between ten to a thousand tablets per tablet server))


这个架构图比较清晰的表达了HMaster和NameNode都支持多个热备份,使用ZooKeeper来做协调;
ZooKeeper并不是云般神秘,它一般由三台机器组成一个集群,内部使用PAXOS算法支持三台Server中的一台宕机,
也有使用五台机器的,此时则可以支持同时两台宕机,既少于半数的宕机,然而随着机器的增加,它的性能也会下降;
RegionServer和DataNode一般会放在相同的Server上实现数据的本地化。


- Client
- Zookeeper
- HMaster
- Region Server
- 写入
- 读出
HBase 原理的更多相关文章
- HBase笔记:对HBase原理的简单理解
早些时候学习hadoop的技术,我一直对里面两项技术倍感困惑,一个是zookeeper,一个就是Hbase了.现在有机会专职做大数据相关的项目,终于看到了HBase实战的项目,也因此有机会搞懂Hbas ...
- Hbase原理
Hbase原理 概述 HBase是一个构建在HDFS上的分布式列存储系统:HBase是基于Google BigTable模型开发的,典型的key/value系统:HBase是Apache Hadoop ...
- HBase原理、设计与优化实践
转自:http://www.open-open.com/lib/view/open1449891885004.html 1.HBase 简介 HBase —— Hadoop Database的简称,G ...
- 大数据技术之_11_HBase学习_01_HBase 简介+HBase 安装+HBase Shell 操作+HBase 数据结构+HBase 原理
第1章 HBase 简介1.1 什么是 HBase1.2 HBase 特点1.3 HBase 架构1.3 HBase 中的角色1.3.1 HMaster1.3.2 RegionServer1.3.3 ...
- 1、Hbase原理分析
一.Hbase介绍 1.1.对Hbase的认识 HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随机读写操作,HBase正是为此而出现. HBase参考 Google 的 Bigtable ...
- HBase原理 – 分布式系统中snapshot是怎么玩的?(转载)
snapshot(快照)基础原理 snapshot是很多存储系统和数据库系统都支持的功能.一个snapshot是一个全部文件系统.或者某个目录在某一时刻的镜像.实现数据文件镜像最简单粗暴的方式是加锁拷 ...
- 【转】HBase原理和设计
简介 HBase —— Hadoop Database的简称,Google BigTable的另一种开源实现方式,从问世之初,就为了解决用大量廉价的机器高速存取海量数据.实现数据分布式存储提供可靠的方 ...
- HBase原理和设计
转载 2016年1月10日:http://www.sysdb.cn/index.php/2016/01/10/hbase_principle/ 简介 架构 数据组织 原理 RS定位 region写入 ...
- HBase原理解析(转)
本文属于转载,原文链接:http://www.aboutyun.com/thread-7199-1-1.html 前提是大家至少了解HBase的基本需求和组件. 从大家最熟悉的客户端发起请求开始讲 ...
- HBase之一:HBase原理和设计
一.简介 HBase —— Hadoop Database的简称,Google BigTable的另一种开源实现方式,从问世之初,就为了解决用大量廉价的机器高速存取海量数据.实现数据分布式存储提供可靠 ...
随机推荐
- Spark in action on Kubernetes - 存储篇(一)
前言 在上篇文章中,我们分析了Spark Operator内部的机制,今天我们会讨论一个在大数据领域中最重要的话题 - 存储.大数据已经无声无息的融入了每个人的生活中.大到旅游买房,小到外卖打车,都可 ...
- HZOJ Permutation
输出原序列有45分…… 字典序最小可以和拓扑序联系起来. 根据原来的题意不是很可做,于是对原序列求逆,令q[p[i]]=i; 那么就成功将题意转化:相邻元素值的差大于等于k时可以交换,使序列字典序最小 ...
- 关于mybatis中llike模糊查询中#和$的使用
模糊查询: 工作中用到,写三种用法吧,第四种为大小写匹配查询 1. sql中字符串拼接 SELECT * FROM tableName WHERE name LIKE CONCAT(CONCAT('% ...
- 爬虫:Selenium + PhantomJS
更:Selenium特征过多(language/UserAgent/navigator/en-US/plugins),以Selenium打开的浏览器处于自测模式,很容易被检测出来,解决方法可选: 用m ...
- Redis在Laravel项目中的应用实例详解
https://mp.weixin.qq.com/s/axIgNPZLJDh9VFGVk7oYYA 在初步了解Redis在Laravel中的应用 那么我们试想这样的一个应用场景 一个文章或者帖子的浏览 ...
- html5的开发
1.html5的开发组织者: (1)WHATWG:由Apple.Mozilla.Google.Opera等浏览器开发者组成,成立于2004年.WHATWG开发HTML和Web应用API,同时为各浏览器 ...
- sql语句列名为变量(Spring Boot+mybitis实验环境)
之前用的#{参数},在列名.表明部分一直不能成为变量.折腾了很久,结果仅仅是改为${变量}就可以了.
- linux用户权限管理, chmod, ln
1 /etc/passwd文件 用户名 密码 UID GID Full Name 主目录 ...
- cdmc2016数据挖掘竞赛题目Android Malware Classification
http://www.csmining.org/cdmc2016/ Data Mining Tasks Description Task 1: 2016 e-News categorisation F ...
- [Atom 编辑器 ] Packages
Atom包 https://atom.io/packages 常用包整理: atom-chinese-menu 中文插件 atom-ternjs 对 es5,es6的语法支持 ato ...