爬虫-Requests 使用入门
requests 的底层实现其实就是 urllib
json在线解析工具
----------------------------------------------
Linux alias命令用于设置指令的别名。
home目录中~/.bashrc 这个文件主要保存个人的一些个性化设置,如命令别名、路径等。
注意:1,写绝对路径
2,有空格
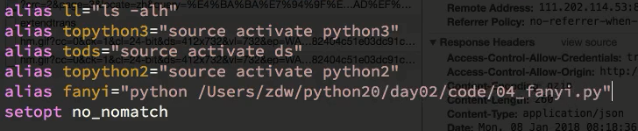
改好后使用source ~/.bashrc 使用文件生效
------------------------------------------------
assert response.status_code==200
assert response.status_code==200
raise异常
raise 引发一个异常
例子:如果输入的数据不是整数,则引发一个ValueError
inputValue=input("please input a int data :")
if type(inputValue)!=type(1):
raise ValueError
else:
print inputValue
假设输入1.2,运行结果为:
please input a int data :1.2
Traceback (most recent call last):
File "C:/Users/lirong/PycharmProjects/untitled/openfile.py", line 3, in <module>
raise ValueError
ValueError
如果输入1,运行结果为:
please input a int data :1
url编码
https://www.baidu.com/s?wd=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2
字符串格式化的另一种方式
"传{}智播客".format(1)
使用代理ip
代理IP百度有很多,推荐使用高匿IP
用法:requests.get("http://www.baidu.com", proxies = proxies)
proxies的形式:字典
proxies = {
"http": "http://12.34.56.79:9527",
"https": "https://12.34.56.79:9527",
}
问题:为什么爬虫需要使用代理? 让服务器以为不是同一个客户端在请求 防止我们的真实地址被泄露,防止被追究
准备一堆的ip地址,组成ip池,随机选择一个ip来时用
如何随机选择代理ip,让使用次数较少的ip地址有更大的可能性被用到
{"ip":ip,"times":0}
[{},{},{},{},{}],对这个ip的列表进行排序,按照使用次数进行排序
选择使用次数较少的10个ip,从中随机选择一个
检查ip的可用性
可以使用requests添加超时参数,判断ip地址的质量
在线代理ip质量检测的网站
携带cookie请求
携带一堆cookie进行请求,把cookie组成cookie池
使用requests提供的session类来请求登陆之后的网站的思路
requests 提供了一个叫做session类,来实现客户端和服务端的会话保持
使用方法:
1 实例化一个session对象
2 让session发送get或者post请求
session = requests.session()
response = session.get(url,headers)
实例化session
先使用session发送请求,登录对网站,把cookie保存在session中
再使用session请求登陆之后才能访问的网站,session能够自动的携带登录成功时保存在其中的cookie,进行请求
不发送post请求,使用cookie获取登录后的页面
cookie过期时间很长的网站
在cookie过期之前能够拿到所有的数据,比较麻烦
配合其他程序一起使用,其他程序专门获取cookie,当前程序专门请求页面
字典推导式,列表推导式
cookies="anonymid=j3jxk555-nrn0wh; _r01_=1; _ga=GA1.2.1274811859.1497951251;
_de=BF09EE3A28DED52E6B65F6A4705D973F1383380866D39FF5; ln_uact=mr_mao_hacker@163.com; depovince=BJ;
jebecookies=54f5d0fd-9299-4bb4-801c-eefa4fd3012b|||||; JSESSIONID=abcI6TfWH4N4t_aWJnvdw;
ick_login=4be198ce-1f9c-4eab-971d-48abfda70a50; p=0cbee3304bce1ede82a56e901916d0949; first_login_flag=1;
ln_hurl=http://hdn.xnimg.cn/photos/hdn421/20171230/1635/main_JQzq_ae7b0000a8791986.jpg;
t=79bdd322e760beae79c0b511b8c92a6b9; societyguester=79bdd322e760beae79c0b511b8c92a6b9;
id=327550029; xnsid=2ac9a5d8; loginfrom=syshome; ch_id=10016; wp_fold=0"
cookies = {i.split("=")[0]:i.split("=")[1] for i in cookies.split("; ")}
[self.url_temp.format(i * 50) for i in range(1000)]
获取登录后的页面的三种方式
实例化session,使用session发送post请求,在使用他获取登陆后的页面
import requests session = request.session()
post_url = ""
post_data = {"email":"xx@163.com","password":"xxx"}
headers = {
...}
# 使用session发送post请求,cookie保存在其中
session.post(post_url,data=post_data,headers=headers)
#在使用session进行请求登陆之后才能访问的地址
r = session.get("http://www.renren.com/327550029/profile",headers=headers) #保存页面
with open("renren1.html","w",encoding="utf-8") as f:
f.write(r.content.decode())
headers中添加cookie键,值为cookie字符串
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36",
"Cookie":...
}
r = requests.get("http://www.renren.com/327550029/profile",headers=headers)
#保存页面
with open("renren2.html","w",encoding="utf-8") as f:
f.write(r.content.decode())
在请求方法中添加cookies参数,接收字典形式的cookie。字典形式的cookie中的键是cookie的name对应的值,值是cookie的value对应的值
# coding=utf-
import requests headers = {...,} cookies="anonymid=j3jxk555-nrn0wh; ..."
cookies = {i.split("=")[]:i.split("=")[] for i in cookies.split("; ")}
print(cookies) r=requests.get("http://...",headers=headers,cookies=cookies) #保存页面
with open("renren3.html","w",encoding="utf-8") as f:
f.write(r.content.decode())
-------------------------------------------
response = requests.url(...)
response.encoding # 查看编码
response.encoding = 'utf-8' # 指定编码
response.content.decode() # 将二进制的获取网页数据返回到本地进行解码 另两种方法 response.content.decode('gbk') response.text
爬虫-Requests 使用入门的更多相关文章
- Python 爬虫-Requests库入门
2017-07-25 10:38:30 response = requests.get(url, params=None, **kwargs) url : 拟获取页面的url链接∙ params : ...
- 初学Python之爬虫的简单入门
初学Python之爬虫的简单入门 一.什么是爬虫? 1.简单介绍爬虫 爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等. 网络爬虫是一种自动获取网页内容的程序,为搜索引擎提供了重要的 ...
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(38):爬虫框架 Scrapy 入门基础(六) Item Pipeline
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- touchWX 自定义组件以及传值
创建如图文件 index.wxc: <template> <view class="wx-test" bindtap="handleTap"& ...
- JS中的垃圾回收(GC)
垃圾回收(GC): 1. 就像人生活的时间长了会产生垃圾一样,程序运行过程中也会产生垃圾,这些垃圾积攒过多以后,会导致程序运行的速度过慢, 所以我们需要一个垃圾回收的机制,来处理程序运行中产生的垃圾. ...
- docker学习---搭建Docker LAMP环境
1.环境 系统版本:CentOS Linux release 7.4.1708 docker版本:docker-ce-18.09 主机IP:192.168.121.121 2.载入MySQL和PHP镜 ...
- window操作命令
netstat -ano 查看所有端口 netstat -ano|findstr "8005" 查看指定端口
- Q:微信小程序一次性订阅消息(前台收集)
说明:官方文档(https://developers.weixin.qq.com/miniprogram/dev/framework/open-ability/subscribe-message.ht ...
- 【Codeforces Round #589 (Div. 2) D】Complete Tripartite
[链接] 我是链接,点我呀:) [题意] 题意 [题解] 其实这道题感觉有点狗. 思路大概是这样 先让所有的点都在1集合中. 然后随便选一个点x,访问它的出度y 显然tag[y]=2 因为和他相连了嘛 ...
- NX二次开发-UFUN旋转视图UF_VIEW_rotate_view
NX11+VS2013 #include <uf.h> #include <uf_view.h> #include <uf_obj.h> #include < ...
- [NOI.AC] palindrome
思路: \(50pts\) \(f[l,r]\)表示区间\([l,r]\)能够变成多少个串,转移枚举\(l\),利用\(hash\)判字符串相等. 复杂度\(O(Tn^3)\) \(70pts\) 考 ...
- Python 爬虫-爬取京东手机页面的图片
具体代码如下: __author__ = 'Fred Zhao' import requests from bs4 import BeautifulSoup import os from urllib ...
- SPSS如何调用已建立的数据文件
SPSS如何调用已建立的数据文件 调用已建立的数据文件 SPSS可以调用SPSS(*.sav),Excel(*.xls),dBASE(*.dbf),ASCII(*.dat,*.txt)等数据文件. 2 ...