Python 分布式锁
1,数据一致性
当多个进程/线程对同一个共享资源读写,会因为资源的争夺而出现混乱,导致数据不一致。
如下图:
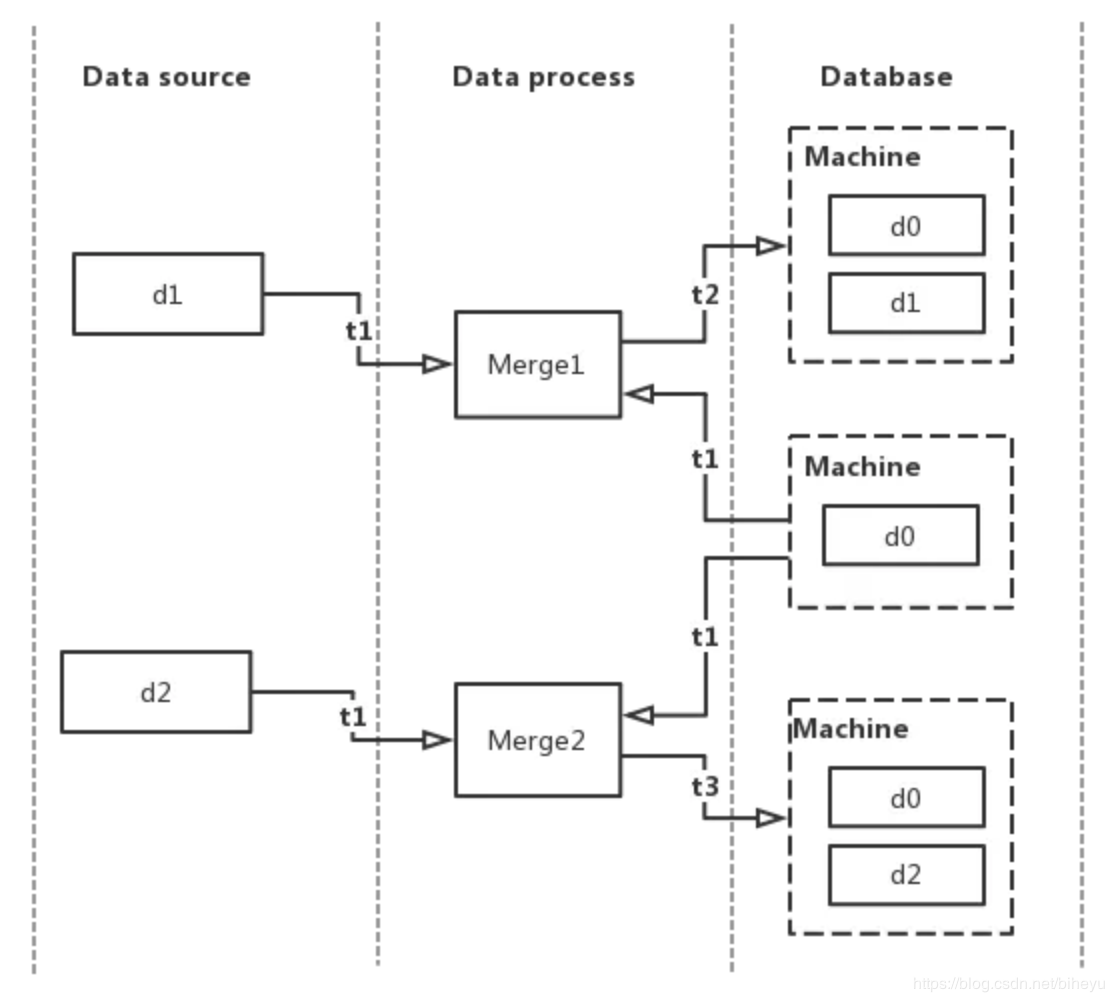
在数据库的原始数据是 d0,上图的处理流程如下:
t1 时刻,有两个数据源的数据 d1,d2 分别到达数据处理层,主进程分配线程 Merge1 处理 d1,Merge2 处理 d2,两者又同时(假设还是 t1 )从数据库获取原始数据 d0
t2 时刻,Merge1 合并完 d0 和 d1 的数据,并将合并后的数据存到数据库,数据库的数据变成 d0 + d1
t3 时刻,Merge2 合并完 d0 和 d2 的数据,并将合并后的数据存到数据库,数据库的数据变成 d0 + d2
t1 到 t3,数据库最终的数据变成了 d0 + d2,数据源 d1 的数据消失,出现数据不一致问题。
上面所列的问题,是由于多线程同时对某一个共享数据进行读写导致,我们只要找到一种方案,使得对共享数据的访问是同步的,即可解决该问题。当有某个线程或者进程已经访问了该数据,其他进程或者线程就必须等待其访问结束,才可拥有该共享数据的访问权(进入临界区)。最简单的方式,就是加个同步锁。
锁的实现方式,按照应用的实现架构,可能会有以下几种类型:
如果处理程序是单进程多线程的,在 python下,就可以使用 threading 模块的 Lock 对象来限制对共享变量的同步访问,实现线程安全。
单机多进程的情况,在 python 下,可以使用 multiprocessing 的 Lock 对象来处理。
多机多进程部署的情况,就得依赖一个第三方组件(存储锁对象)来实现一个分布式的同步锁了。
2,分布式锁实现方式
目前主流的分布式锁实现方式有以下几种:
基于数据库来实现,如 mysql
基于缓存来实现,如 redis
基于 zookeeper 来实现
下面我们简单介绍下这几种锁的实现。
2.1,基于数据库的锁:
基于数据库的锁实现也有两种方式,一是基于数据库表,另一种是基于数据库排他锁。
基于数据库表的增删:
基于数据库表增删是最简单的方式,首先创建一张锁的表主要包含下列字段:方法名,时间戳等字段。
具体使用的方法,当需要锁住某个方法时,往该表中插入一条相关的记录。这边需要注意,方法名是有唯一性约束的,如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。执行完毕,需要delete该记录。
对于上述方案可以进行优化,如应用主从数据库,数据之间双向同步。一旦挂掉快速切换到备库上;做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍;使用while循环,直到insert成功再返回成功,虽然并不推荐这样做;还可以记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了,实现可重入锁。
数据库的排他锁:
基于MySql的InnoDB引擎,可以使用以下方法来实现加锁操作。
在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。其他没有获取到锁的就会阻塞在上述select语句上,可能的结果有2种,在超时之前获取到了锁,在超时之前仍未获取到锁。
获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,释放锁 connection.commit() 。
存在的问题主要是性能不高和sql超时的异常。
2.2,基于zookeeper实现
基于zookeeper临时有序节点可以实现的分布式锁。每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
提供的第三方库有 curator ,具体使用读者可以自行去看一下。Curator提供的InterProcessMutex是分布式锁的实现。acquire方法获取锁,release方法释放锁。另外,锁释放、阻塞锁、可重入锁等问题都可以有有效解决。讲下阻塞锁的实现,客户端可以通过在ZK中创建顺序节点,并且在节点上绑定监听器,一旦节点有变化,Zookeeper会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中序号最小的,如果是就获取到锁,便可以执行业务逻辑。
最后,Zookeeper实现的分布式锁其实存在一个缺点,那就是性能上可能并没有缓存服务那么高。因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。ZK中创建和删除节点只能通过Leader服务器来执行,然后将数据同不到所有的Follower机器上。并发问题,可能存在网络抖动,客户端和ZK集群的session连接断了,zk集群以为客户端挂了,就会删除临时节点,这时候其他客户端就可以获取到分布式锁了。
用法参考:https://yunjianfei.iteye.com/blog/2164888
2.3,基于缓存redis实现
相对于基于数据库实现分布式锁的方案来说,基于缓存来实现在性能方面会表现的更好一点,存取速度快很多。而且很多缓存是可以集群部署的,可以解决单点问题。
使用redis的SETNX实现分布式锁,多个进程执行以下Redis命令:
SETNX lock.id <current Unix time + lock timeout + 1>
SETNX是将 key 的值设为 value,当且仅当 key 不存在。若给定的 key 已经存在,则 SETNX 不做任何动作。
返回1,说明该进程获得锁,SETNX将键 lock.id 的值设置为锁的超时时间,当前时间 +加上锁的有效时间。
返回0,说明其他进程已经获得了锁,进程不能进入临界区。进程可以在一个循环中不断地尝试 SETNX 操作,以获得锁。
3,分布式锁保持数据一致的原理
每种实现方式各有千秋,综合考量,我们最终决定使用 redis,主要原因是:
redis 是基于内存来操作,存取速度比数据库快,在高并发下,加锁之后的性能不会下降太多
redis 可以设置键值的生存时间(TTL)
redis 的使用方式简单,总体实现开销小
同时使用 redis 实现的分布锁还需要具备以下几个条件:
同一个时刻只能有一个线程占有锁,其他线程必须等待直到锁被释放
锁的操作必须满足原子性
不会发生死锁,例如已获得锁的线程在释放锁之前突然异常退出,导致其他线程会一直在循环等待锁被释放
锁的添加和释放必须由同一个线程来设置
我们在上图 的基础上,在 Data process 和 Database 之间加了一层锁,我们在 redis 中使用添加了一个 lock_key 来作为锁的标识,流程图如下:
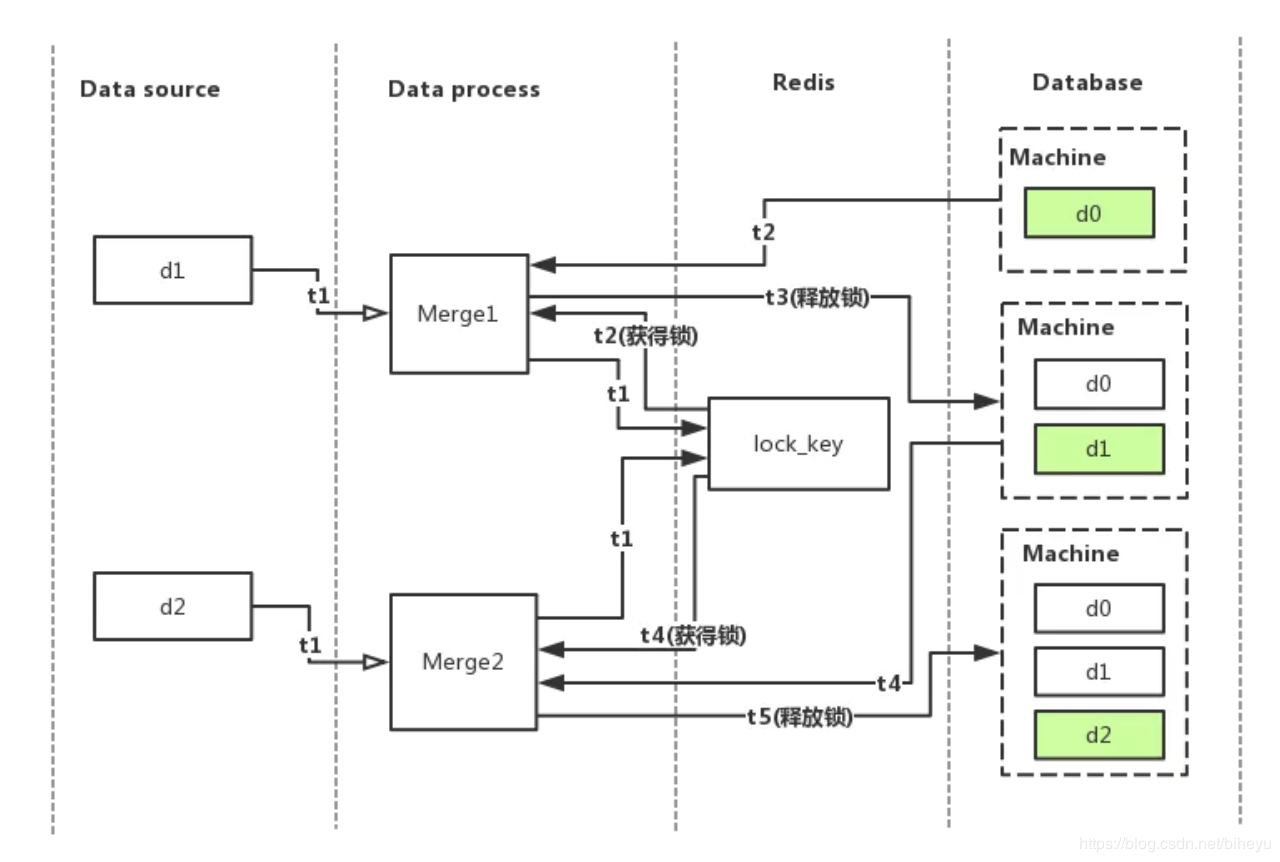
还是假设某台机器(图中的machine)在数据库的原始数据是 d0,上图的处理流程变成了:
t1 时刻,有两个数据源的数据 d1,d2 同时到达数据处理层,主进程分配了线程 Merge1 处理 d1,线程 Merge2 处理 d2,两者又同时尝试从 redis 获得锁
t2 时刻,Merge1 成功获得了锁,同时从数据库中加载 machine 的原始数据 d0,Merge2 循环等待 Merge1 释放锁
t3 时刻,Merge1 合并完数据,并将合并好的数据 d0 + d1 存放到数据库,最后释放锁
t4 时刻,Merge2 获得了锁,同时从数据库中加载machine的数据 d0 + d1
t5 时刻,Merge2 合并完数据,并将合并好的数据 d0 + d1 + d2 存放到数据库,最后释放锁
从以上可以看到保持数据一致的原理其实也不难,无非就是使用一个键值来使得多个线程对同一台机器的数据的读写是同步的,但是在实现的过程中,往往会忽视了分布式锁所要具备的某个条件,极端情况下,还是会出现数据不一致的问题。
几个要用到的redis命令:
setnx(key, value):“set if not exits”,若该key-value不存在,则成功加入缓存并且返回1,否则返回0。
get(key):获得key对应的value值,若不存在则返回nil。
getset(key, value):先获取key对应的value值,若不存在则返回nil,然后将旧的value更新为新的value。
expire(key, seconds):设置key-value的有效期为seconds秒。
4,死锁的问题
SETNX实现分布式锁,可能会存在死锁的情况。与单机模式下的锁相比,分布式环境下不仅需要保证进程可见,还需要考虑进程与锁之间的网络问题。某个线程获取了锁之后,断开了与Redis 的连接,锁没有及时释放,竞争该锁的其他线程都会hung,产生死锁的情况。
在使用 SETNX 获得锁时,我们将键 lock.id 的值设置为锁的有效时间,线程获得锁后,其他线程还会不断的检测锁是否已超时,如果超时,等待的线程也将有机会获得锁。然而,锁超时,我们不能简单地使用 DEL 命令删除键 lock.id 以释放锁。
考虑以下情况:
A已经首先获得了锁 lock.id,然后线A断线。B,C都在等待竞争该锁;
B,C读取lock.id的值,比较当前时间和键 lock.id 的值来判断是否超时,发现超时;
B执行 DEL lock.id命令,并执行 SETNX lock.id 命令,并返回1,B获得锁;
C由于各刚刚检测到锁已超时,执行 DEL lock.id命令,将B刚刚设置的键 lock.id 删除,执行 SETNX lock.id命令,并返回1,即C获得锁。
上面的步骤很明显出现了问题,导致B,C同时获取了锁。在检测到锁超时后,线程不能直接简单地执行 DEL 删除键的操作以获得锁。
对于上面的步骤进行改进,问题是出在删除键的操作上面,那么获取锁之后应该怎么改进呢?
首先看一下redis的GETSET这个操作, GETSET key value ,将给定 key 的值设为 value ,并返回 key 的旧值(old value)。利用这个操作指令,我们改进一下上述的步骤。
A已经首先获得了锁 lock.id,然后线A断线。B,C都在等待竞争该锁;
B,C读取lock.id的值,比较当前时间和键 lock.id 的值来判断是否超时,发现超时;
B检测到锁已超时,即当前的时间大于键 lock.id 的值,B会执行
GETSET lock.id <current Unix timestamp + lock timeout + 1> 设置时间戳,通过比较键 lock.id 的旧值是否小于当前时间,判断进程是否已获得锁;
B发现GETSET返回的值小于当前时间,则执行 DEL lock.id命令,并执行 SETNX lock.id 命令,并返回1,B获得锁;
C执行GETSET得到的时间大于当前时间,则继续等待。
在线程释放锁,即执行 DEL lock.id 操作前,需要先判断锁是否已超时。如果锁已超时,那么锁可能已由其他线程获得,这时直接执行 DEL lock.id 操作会导致把其他线程已获得的锁释放掉。
使用Zookeeper实现分布式锁的优点:
有效的解决单点问题,不可重入问题,非阻塞问题以及锁无法释放的问题。实现起来较为简单。
使用Zookeeper实现分布式锁的缺点:
性能上不如使用缓存实现分布式锁。 需要对ZK的原理有所了解。
5,redis代码实现分布式锁
结合上面(分布式锁保持数据一致的原理)提到的使用redis分布式锁的三种条件,使用三种不同获取redis锁的方式,探索分布式锁的使用方法。
下面使用同一份测试代码:
我们启用了多线程去对 redis 中的 test_key 的值进行自增操作,理想情况,test_key 的值应该等于线程的数量,比如开了 10 个线程,test_key的值最终应该是 10。
- import threading, time, redis
- from redis import StrictRedis
- def increase_data(redis_conn, lock, key):
- lock_value = lock.get_lock(key) #获取锁
- value = redis_conn.get(key) #获取数据
- time.sleep(0.1)
- if value:
- value = int(value) + 1
- else:
- value = 0
- redis_conn.set(key, value)
- thread_name = threading.current_thread().name
- print(thread_name, value)
- lock.del_lock(key) #释放锁
- ##主程序
- if __name__ == "__main__":
- pool = redis.ConnectionPool(host='127.0.0.1', port=6379, db=8)
- redis = StrictRedis(connection_pool=pool)
- lock = RedisLock(redis)
- key = 'test_key'
- thread_count = 10
- redis.delete(key)
- for i in range(thread_count):
- thread = threading.Thread(target=increase_data, args=(redis, lock, key))
- thread.start()
方式一:加锁操作非原子性
在这个版本中,当线程 A get(key) 的值为空时,set key 的值为 1,并返回,这表示线程 A 获得了锁,可以继续执行后面的操作,否则需要一直循环去获取锁,直到 key 的值再次为空,重新获得锁,执行任务完毕后释放锁。
- class RedisLock(object):
- def __init__(self, redis_conn):
- self.redis_conn = redis_conn
- def get_lock_key(self, key):
- lock_key = 'lock_%s' %key
- return lock_key
- def get_lock(self, key):
- lock_key = self.get_lock_key(key)
- while True:
- value = self.redis_conn.get(lock_key)
- if not value:
- self.redis_conn.set(lock_key, 1)
- return True
- time.sleep(0.01)
- def del_lock(self, key):
- lock_key = self.get_lock_key(key)
- return self.redis_conn.delete(lock_key)
执行测试脚本,得到的结果如下:
- Thread-1 1
- Thread-5 2
- Thread-2 2
- Thread-6 3
- Thread-7 3
- Thread-4 3
- Thread-9 4
- Thread-8 5
- Thread-10 5
- Thread-3 5
观察结果就发现,同时有多个线程输出的结果是一样的。乍一看上面加锁的代码逻辑似乎没啥问题,但是结果却事与愿违,原因是上面的代码 get(key) 和 set(key, value) 并不是原子性的,A 线程在 get(key) 的时候发现是空值,于是重新 set(key, value),但在 set 完成的前一刻,B 线程恰好 get(key) 的时候得到的还是空值,然后也顺利获得锁,导致数据被两个或多个线程同时修改,最后出现不一致。
方式二:使用 setnx 来实现
鉴于上面版本是由于命令不是原子性操作造成两个或多个线程同时获得锁的问题,这个版本改成使用 redis 的 setnx 命令来进行锁的查询和设置操作,setnx 即 set if not exists,顾名思义就是当key不存在的时候才设置 value,并返回 1,如果 key 已经存在,则不进行任何操作,返回 0。
- def get_lock(self, key):
- lock_key = self.get_lock_key(key)
- while True:
- value = self.redis_conn.setnx(lock_key, 1)
- if value:
- return True
- time.sleep(0.01)
代码执行结果:
- ('Thread-1', 0)
- ('Thread-9', 1)
- ('Thread-4', 2)
- ('Thread-8', 3)
- ('Thread-7', 4)
- ('Thread-10', 5)
- ('Thread-2', 6)
- ('Thread-6', 7)
- ('Thread-5', 8)
- ('Thread-3', 9)
结果是正确的,但是如果满足于此,还是会出问题的,比如假设 A 线程获得了锁后,由于某种异常原因导致线程 crash了,一直不释放锁呢?我们稍微改一下测试用例的 increase 函数,模拟某个线程在释放锁之前因为异常退出。
- def increase_data(redis_conn, lock, key):
- lock_value = lock.get_lock(key) #获取锁
- value = redis_conn.get(key) #获取数据
- time.sleep(0.1)
- if not value:
- value = int(value) + 1
- else:
- value = 0
- redis_conn.set(key, value)
- thread_name = threading.current_thread().name
- print(thread_name, value)
- if thread_name == "Thread-2":
- print("thread-2 crash ....")
- import sys
- sys.exit(1)
- lock.del_lock(key) #释放锁
代码执行结果:
- Thread-2 3
- Thread-2 crash..
- .....
线程 2 crash 之后,后续的线程一直获取不了锁,便一直处于等待锁的状态,于是乎产生了死锁。如果数据是多线程处理的,比如每来一个数据就开一个线程去处理,那么堆积的线程会逐渐增多,最终可能会导致系统崩溃。
使用了 redis 来实现分布式锁,何不利用 redis 的 ttl 机制呢,给锁加上过期时间。
代码修改为:
- def get_lock(self, key, timeout=1):
- lock_key = self.get_lock_key(key)
- while True:
- value = self.redis_conn.set(lock_key, 1, nx=True, ex=timeout)
- if value:
- break
- else:
- print("waiting....")
- time.sleep(0.1)
执行结果:
- ('Thread-1', 0)
- ('Thread-10', 1)
- ('Thread-8', 2)
- ('Thread-3', 3)
- ('Thread-2', 4)
- thread-2 crash ....
- ('Thread-7', 5)
- waiting....
- waiting....
- waiting....
- ('Thread-9', 6)
- ('Thread-6', 7)
- ('Thread-4', 8)
- ('Thread-5', 9)
结果正确,线程 2 在 crash 后,其他线程在等待,直到锁过期。
进行到这里,似乎已经可以解决数据不一致的问题了,但在欢喜之余,不妨多想想会不会出现其他问题。比如假设 A 进程的逻辑还没处理完,但是锁由于过期时间到了,导致锁自动释放掉,这时 B 线程获得了锁,开始处理 B 的逻辑,然后 A 进程的逻辑处理完了,就把 B 进程的锁给删除了。
方式三:锁的生成和删除必须是同一个线程
先修改代码,设置代码的执行时间大于ttl时间
- def increase_data(redis_conn, lock, key):
- lock_value = lock.get_lock(key) #获取锁
- value = redis_conn.get(key) #获取数据
- time.sleep(2.5) #模拟实际情况下进行的某些耗时操作, 且执行时间大于锁过期的时间
- if value:
- value = int(value) + 1
- else:
- value = 0
- redis_conn.set(key, value)
- thread_name = threading.current_thread().name
- print(thread_name, value)
- if thread_name == "Thread-2":
- print("thread-2 crash ....")
- import sys
- sys.exit(1)
- lock.del_lock(key) #释放锁
- 执行结果:
- ('Thread-1', 0)
- Thread-5 is waiting..
- ('Thread-4', 0)
- ('Thread-2', 1)
- thread-2 crash ....
- ('Thread-3', 1)
- ('Thread-5', 1)
从以上结果可以看出,由于每个线程的执行时间大于锁的过期时间,当线程的任务还没执行完时,锁已经自动释放,使得下一个线程获得了锁,而后下一个线程的锁被上一个执行完了的线程删掉或者也是自动释放(具体要看线程的执行时间和锁的释放时间),于是又产生了同一个数据被两个或多个线程同时修改的问题,导致数据出现不一致。
我们用四个线程,按照时间顺序画的流程图如下:
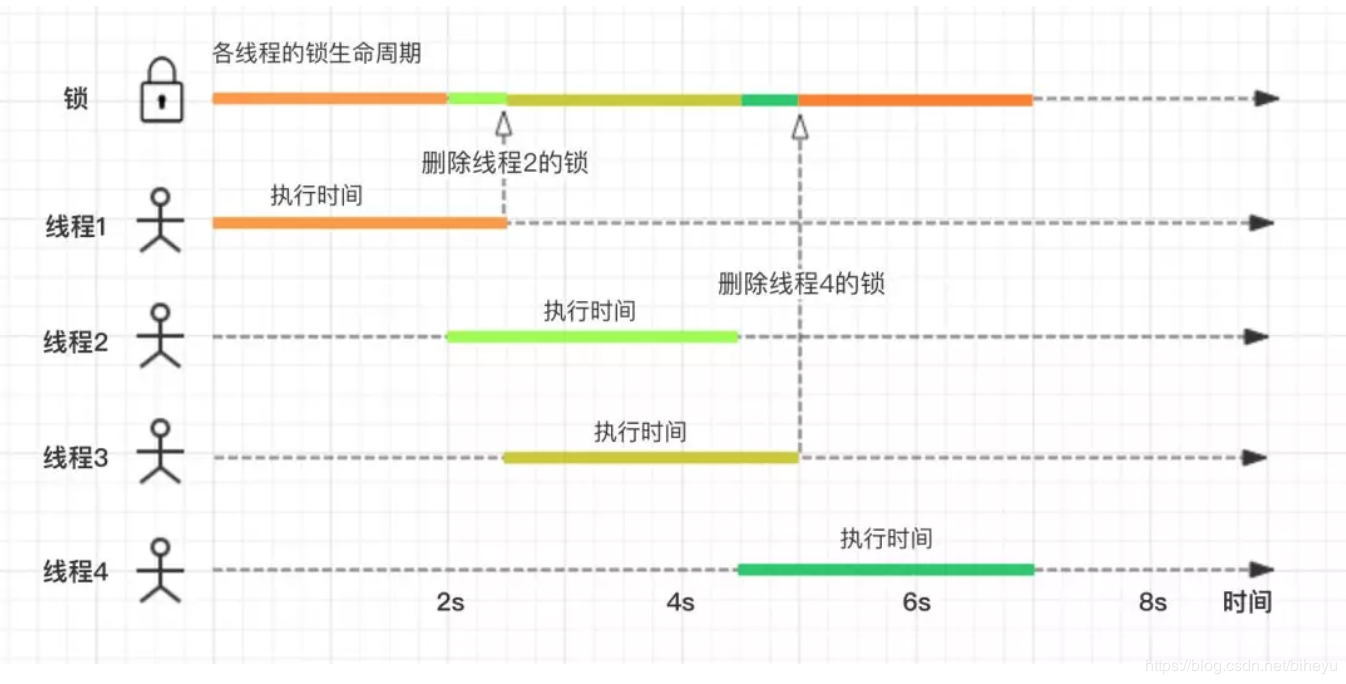
可以看到,在 2.5s 和 5s 的时刻,都产生了误删锁的情况。
既然这个现象是由于锁过期导致误删别人家的锁引发的,那我们就顺着这个思路,强制线程只能删除自己设置的锁。如果是这样,就得被每个线程的锁添加一个唯一标识了。看看上面的锁机制,我们每次添加锁的时候,都是给 lock_key 设为 1,无论是 key 还是 value,都不具备唯一性,如果把 key 设为每个线程唯一的,那在分布式系统中,得产生 N (等于总线程数)个 key 了 ,从直观性和维护性上来说,这都是不可取的,于是乎只能从 value 入手了。我们看到每个线程都可以取到一个唯一标识,即线程 ID,如果加上进程的 PID,以及机器的 IP,就可以构成一个线程锁的唯一标识了,如果还担心不够唯一,再打上一个时间戳了,于是乎,我们的分布式锁最终版就变成了以下这样:
- class RedisLock(object):
- def __init__(self, redis_conn):
- self.redis_conn = redis_conn
- self.ip = socket.gethostbyname(socket.gethostname())
- self.pid = os.getpid()
- def get_lock_key(self, key):
- lock_key = 'lock_%s' %key
- return lock_key
- def gen_unique_value(self):
- thread_name = threading.current_thread().name
- time_now = time.time()
- unique_value = "{0}-{1}-{2}-{3}".format(self.ip, self.pid, thread_name, time_now)
- return unique_value
- def get_lock(self, key, timeout=1):
- lock_key = self.get_lock_key(key)
- unique_value = self.gen_unique_value()
- print("unique value %s" % unique_value)
- while True:
- value = self.redis_conn.set(lock_key, 1, nx=True, ex=timeout)
- if value:
- return unique_value
- else:
- thread_name = threading.current_thread().name
- print("{} is waiting..".format(thread_name))
- time.sleep(0.1)
- def del_lock(self, key, value):
- lock_key = self.get_lock_key(key)
- old_lock_value = self.redis_conn.get(lock_key)
- if old_lock_value == value:
- return self.redis_conn.delete(lock_key)
- 修改测试代码:
- def increase_data(redis_conn, lock, key):
- lock_value = lock.get_lock(key) #获取锁
- value = redis_conn.get(key) #获取数据
- time.sleep(2.5) #模拟实际情况下进行的某些耗时操作, 且执行时间大于锁过期的时间
- if value:
- value = int(value) + 1
- else:
- value = 0
- redis_conn.set(key, value)
- thread_name = threading.current_thread().name
- print(thread_name, value)
- if thread_name == "Thread-2":
- print("thread-2 crash ....")
- import sys
- sys.exit(1)
- lock.del_lock(key, lock_value) #释放锁
运行结果:
- unique value 192.168.1.110-45351-Thread-1-1555730398.38
- unique value 192.168.1.110-45351-Thread-2-1555730398.39
- unique value 192.168.1.110-45351-Thread-3-1555730398.4
- unique value 192.168.1.110-45351-Thread-4-1555730398.42
- unique value 192.168.1.110-45351-Thread-5-1555730398.43
- ('Thread-1', 0)
- Thread-3 is waiting..
- Thread-2 is waiting..
- Thread-3 is waiting..
- Thread-2 is waiting..
- ('Thread-4', 0)
- Thread-3 is waiting..
- ('Thread-5', 0)
- ('Thread-3', 1)
- ('Thread-2', 1)
- thread-2 crash ....
以上可以看出,问题没有得到解决。因为什么原因呢?以上我们设置值的唯一性只能确保线程不会误删其他线程产生的锁,进而出现连串的误删锁的情况,比如 A 删了 B 的锁,B 执行完删了 C 的锁 。使用 redis 的过期机制,只要业务的处理时间大于锁的过期时间,就没有一个很好的方式来避免由于锁过期导致其他线程同时占有锁的问题,所以需要熟悉业务的执行时间,来合理地设置锁的过期时间。
还需注意的一点是,以上的实现方式中,删除锁(del_lock)的操作不是原子性的,先是拿到锁,再判断锁的值是否相等,相等的话最后再删除锁,既然不是原子性的,就有可能存在这样一种极端情况:在判断的那一时刻,锁正好过期了,被其他线程占有了锁,那最后一步的删除,就可能会造成误删锁了。可以使用官方推荐的 Lua 脚本来确保原子性:
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
但是只要锁的过期时间设置的足够合理,这个问题其实是可以忽略的,也可以说出现这种极端情况的概率是及其小的。
以上我们使用 redis 来实现一个分布式的同步锁,来保证数据的一致性,其特点是:
满足互斥性,同一个时刻只能有一个线程可以获取锁
利用 redis 的 ttl 来确保不会出现死锁,但同时也会带来由于锁过期引发的多线程同时占有锁的问题,需要我们合理设置锁的过期时间来避免
利用锁的唯一性来确保不会出现误删锁的情况
以上的方案中,我们是假设 redis 服务端是单集群且高可用的,忽视了以下的问题:如果某一时刻 redis master 节点发生了故障,集群中的某个 slave 节点变成 master 节点,这时候就可能出现原 master 节点上的锁没有及时同步到 slave 节点,导致其他线程同时获得锁。对于这个问题,可以参考 redis 官方推出的 redlock 算法,但是比较遗憾的是,该算法也没有很好地解决锁过期的问题。
————————————————
版权声明:本文为CSDN博主「达西布鲁斯」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/biheyu828/article/details/89005866
Python 分布式锁的更多相关文章
- python使用redis实现协同控制的分布式锁
python使用redis实现协同控制的分布式锁 上午的时候,有个腾讯的朋友问我,关于用zookeeper分布式锁的设计,他的需求其实很简单,就是节点之间的协同合作. 我以前用redis写过一个网络锁 ...
- python redis分布式锁改进
0X01 python redis分布式锁通用方法 REDIS分布式锁实现的方式:SETNX + GETSET 使用Redis SETNX 命令实现分布式锁 python 版本实现上述思路(案例1) ...
- python基于redis实现分布式锁
阅读目录 什么事分布式锁 基于redis实现分布式锁 一.什么是分布式锁 我们在开发应用的时候,如果需要对某一个共享变量进行多线程同步访问的时候,可以使用我们学到的锁进行处理,并且可以完美的运行,毫无 ...
- redis(二十四):Redis分布式锁以及实现(python)
阅读目录 什么事分布式锁 基于redis实现分布式锁 一.什么是分布式锁 我们在开发应用的时候,如果需要对某一个共享变量进行多线程同步访问的时候,可以使用我们学到的锁进行处理,并且可以完美的运行,毫无 ...
- 用Redis实现分布式锁
Redis有一系列的命令,特点是以NX结尾,NX是Not eXists的缩写,如SETNX命令就应该理解为:SET if Not eXists.这系列的命令非常有用,这里讲使用SETNX来实现分布式锁 ...
- Redis setNX 实现分布式锁(重复数据插入可用其来实现排他锁)
使用Redis的 SETNX 命令可以实现分布式锁,下文介绍其实现方法. SETNX命令简介 命令格式 SETNX key value 将 key 的值设为 value,当且仅当 key 不存在. 若 ...
- 用Redis构建分布式锁-RedLock(真分布)
在不同进程需要互斥地访问共享资源时,分布式锁是一种非常有用的技术手段. 有很多三方库和文章描述如何用Redis实现一个分布式锁管理器,但是这些库实现的方式差别很大,而且很多简单的实现其实只需采用稍微增 ...
- 使用Redis SETNX 命令实现分布式锁
基于setnx和getset http://blog.csdn.net/lihao21/article/details/49104695 使用Redis的 SETNX 命令可以实现分布式锁,下文介绍其 ...
- Redis实现分布式锁
http://redis.io/topics/distlock 在不同进程需要互斥地访问共享资源时,分布式锁是一种非常有用的技术手段. 有很多三方库和文章描述如何用Redis实现一个分布式锁管理器,但 ...
随机推荐
- celery中配置redis密码时的ValueError: invalid literal for int() with base 10: 'xxxx'
原配置: celery_broker = 'redis://:xxxx#xxxx@172.17.0.1:6379/0' # docker0 错误原因: 密码中不能有 # ? 等特殊字符 (无语O__O ...
- linux6.5 网卡绑定
Linux网口绑定 通过网口绑定(bond)技术,可以很容易实现网口冗余,负载均衡,从而达到高可用高可靠的目的.前提约定: 2个物理网口分别是:eth0,eth1 绑定后的虚拟口是:bond0 服务器 ...
- django里面跨域CORS的设置
安装 pip install django-cors-headers 添加应用 在settings里面配置 INSTALLED_APPS = ( ... 'corsheaders', ... ) 中间 ...
- Fatal error compiling: invalid target release: 11 -> [Help 1]
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compi ...
- rem_2
html{ font-size:625%; } body{ font-size:0.16rem; }
- promise、async、await、settimeout异步原理与执行顺序
一道经典的前端笔试题,你能一眼写出他们的执行结果吗? async function async1() { console.log("async1 start"); await as ...
- Vue学习笔记【3】——Vue指令之v-bind的三种用法
直接使用指令v-bind 使用简化指令: 在绑定的时候,拼接绑定内容::title="btnTitle + ', 这是追加的内容'" <!DOCTYPE html> & ...
- BZOJ 1303: [CQOI2009]中位数图(思路题)
传送门 解题思路 比较好想的思路题.首先肯定要把原序列转化一下,大于\(k\)的变成\(1\),小于\(k\)的变成\(-1\),然后求一个前缀和,还要用\(cnt[]\)记录一下前缀和每个数出现了几 ...
- [bzoj2287]消失之物 题解(背包dp)
2287: [POJ Challenge]消失之物 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 1138 Solved: 654[Submit][ ...
- RN 真机roload
第四步:打开调试菜单 手机设备可以通过摇一摇设备打开调试菜单,也可以打开调试菜单. 可因为是平板,摇一摇不是太方便,可以在电脑端运行命令来打开调试菜单,但有时却又无法打开调试菜单(如果是使用真机调试, ...