多图预警——从 RAID 到分布式系统中的副本分布
原文首发于个人博客「tobe的呓语」欢迎大家的访问收藏啊~
我们知道,在面对大规模数据的计算和存储时,有两种处理思路:
- 垂直扩展(scale up):通过升级单机的硬件,如 CPU、内存、磁盘等,提高计算机的处理能力。
- 水平扩展(scale out):通过添加更多的机器到分布式系统中,提高整个系统的处理能力。
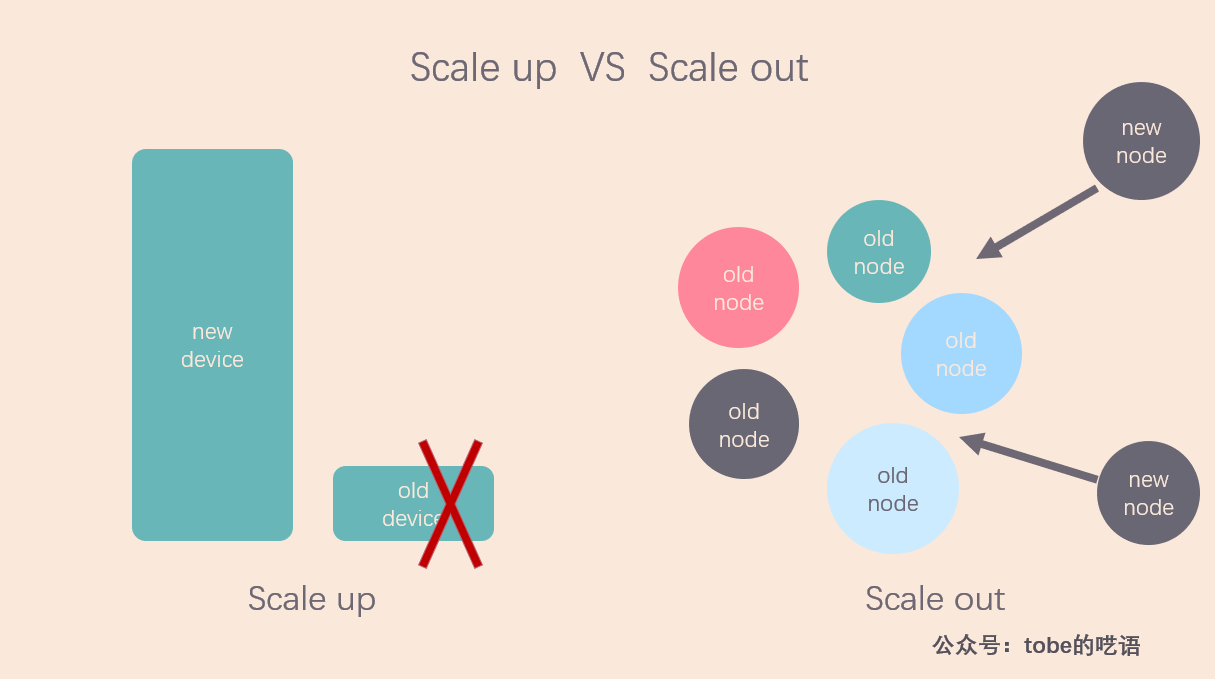
在分布式技术尚未成熟的时候,小型机、中型机、大型机、超级计算机逐步升级的方案几乎是大型公司的唯一选择,但是这种垂直扩展是有天花板的,硬件升级的速度远远比不上数据规模的增速,即使是超级计算机也无法满足人们对计算资源的需求。
水平扩展方案,也就是在一个系统里不断添加机器的方案,就这么走上了历史舞台。这就是现在的分布式技术。
在这篇文章里,我将分别介绍单机系统下的 RAID 存储技术以及分布式系统下的存储分布技术,这两种技术在思想上有很相近的地方,希望读者慢慢体会。
RAID
RAID,全称是Redundant Array of Inexpensive/Independent Disks,也就是磁盘冗余阵列,这里的 I 有两种说法,一种是 Inexpensive,廉价,另一种是Independent ,独立。所谓 RAID 就是将多块磁盘组合在一起,对外抽象成一个容量大,读写速度高,容错性好的大型磁盘。
我很喜欢「抽象」这个概念,因为它为我们屏蔽了更底层的细节,比如操作系统中的文件系统,虚拟内存等。在我看来,RAID 就是对多个独立磁盘的抽象。
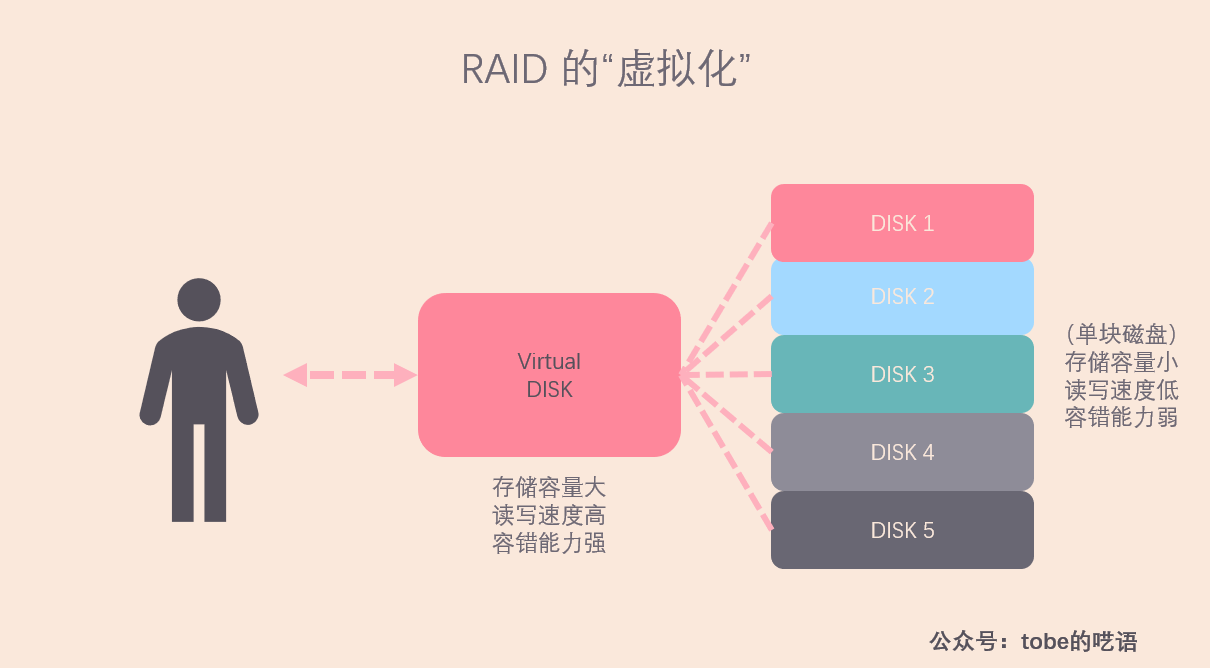
注意,上面的图里的三个方面(存储容量、读写速度、数据可靠性)是衡量存储系统的重要标准,我们在分布式系统里也会提及,不过现在让我们先来看看常用的 RAID 技术。
RAID 0
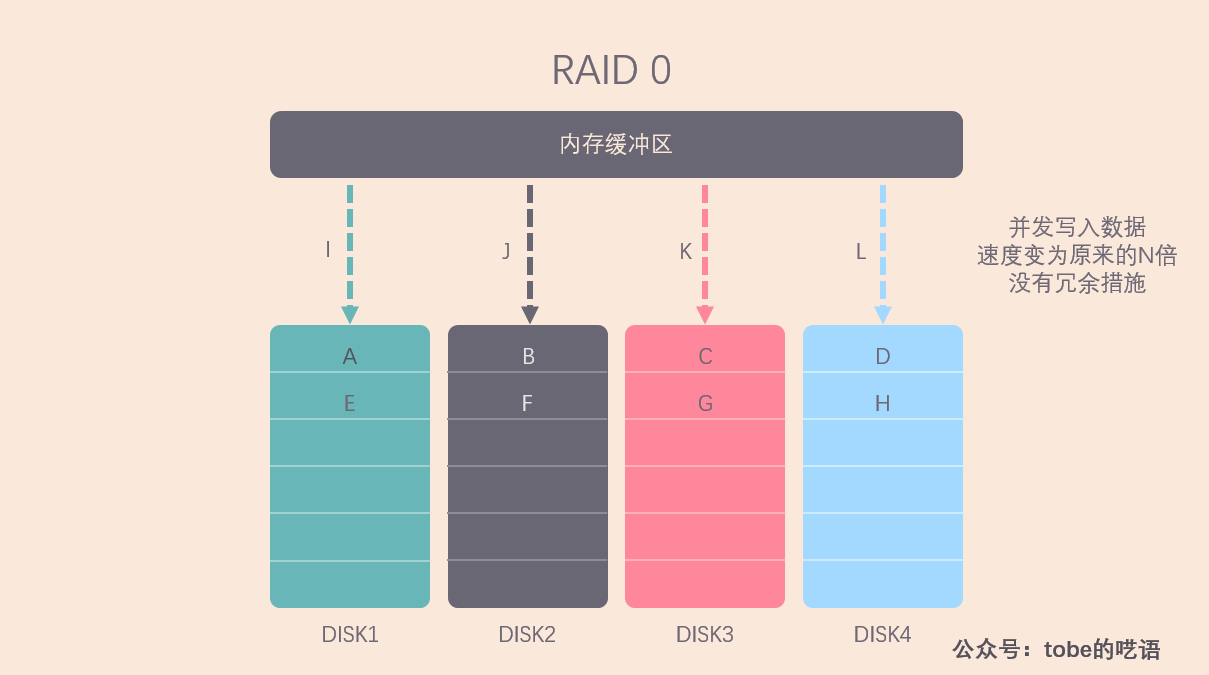
RAID 0 是数据在从内存缓冲区写入磁盘时,根据磁盘的数量,将数据分成 N 份,然后把这些数据并发写入 N 块磁盘,每块磁盘上存储不同的数据,这样整体的数据写入速度是单个磁盘的 N 倍,读取当然也是并发执行的。
因此 RAID 0 具有极快的数据读写速度。但是RAID 0不做数据备份,N块磁盘中只要有一块损坏,数据完整性就被破坏,其他磁盘的数据就无法使用了。
RAID 1
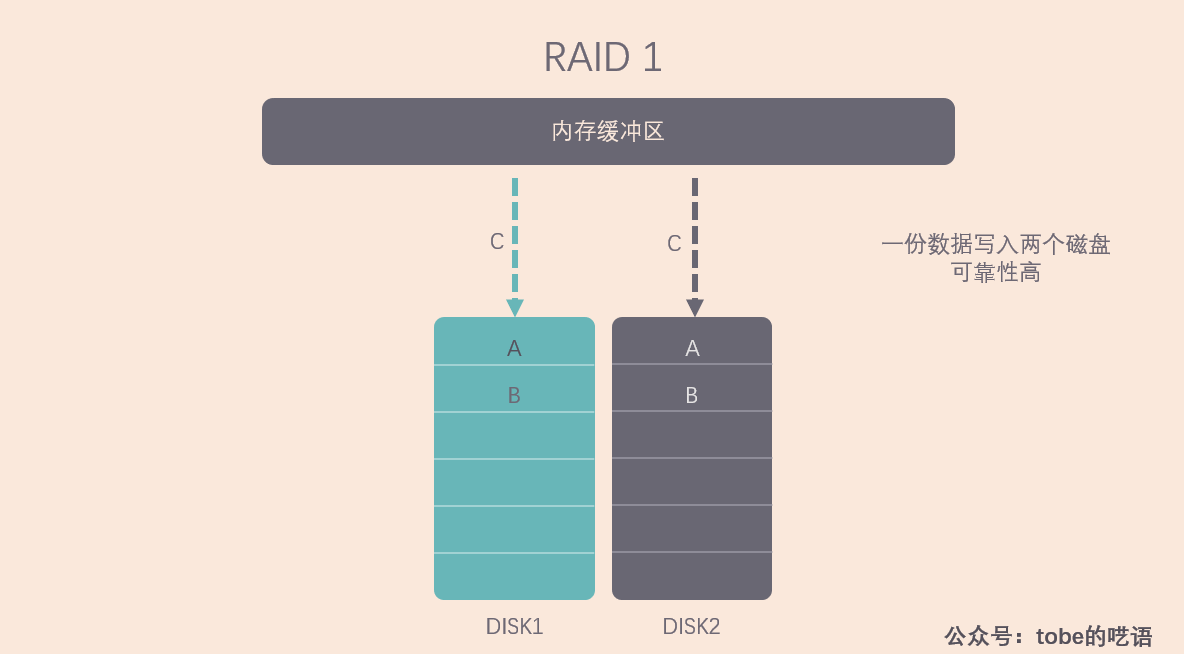
RAID 1 的策略更为简单,不管你有几个磁盘,都给我存一样的数据,这样数据的可靠性极高,但是写入速度收到很大影响。
Any read request can be serviced by any drive in the set. If a request is broadcast to every drive in the set, it can be serviced by the drive that accesses the data first (depending on its seek time and rotational latency), improving performance. Sustained read throughput, if the controller or software is optimized for it, approaches the sum of throughputs of every drive in the set, just as for RAID 0. Actual read throughput of most RAID 1 implementations is slower than the fastest drive. Write throughput is always slower because every drive must be updated, and the slowest drive limits the write performance. The array continues to operate as long as at least one drive is functioning.1
这段话意思是说,RAID 1 的读取速度取决于哪一个硬盘能最先访问到待读取的数据,如果软件上有优化,可以达到 RAID 0 的读取速度。但是最慢的磁盘限制了写入速度,因为系统需要等待最慢的磁盘完成写入并做好检验工作。RAID 1 的可靠性好,只要阵列里有任意一块磁盘还能用,阵列就能继续工作,而且当新磁盘替代旧磁盘后,系统会自动复制数据。
RAID 10
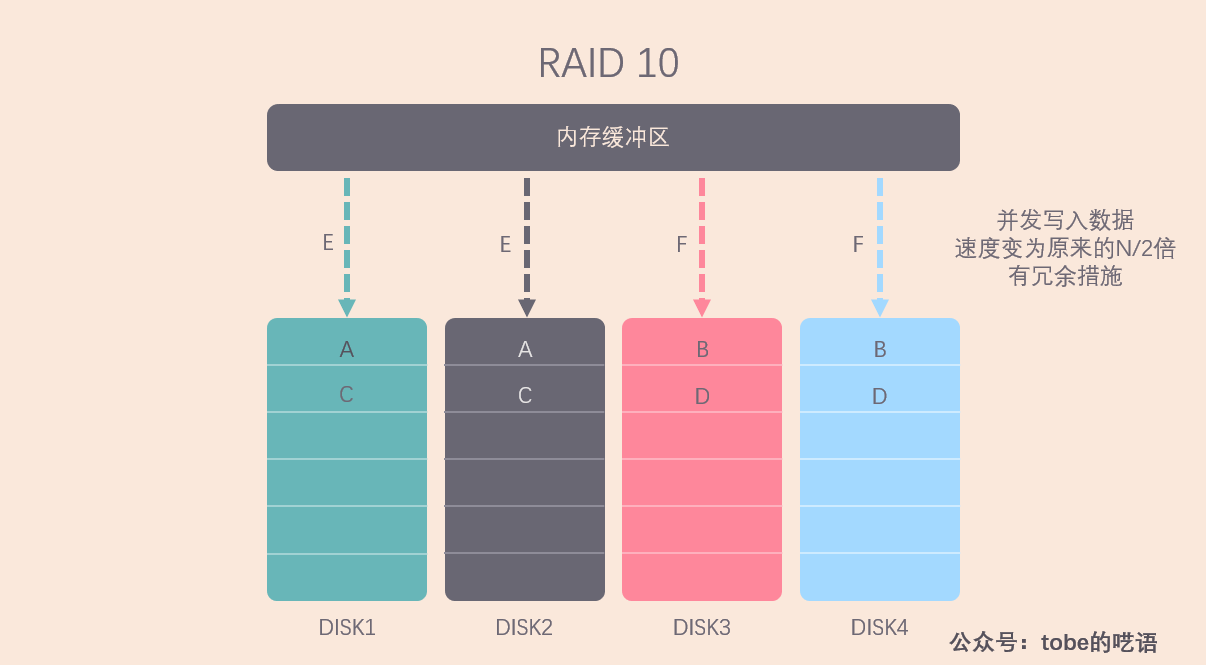
RAID 0 读写速度高,但没有数据冗余, RAID 1 做了数据备份,但读写速度受到制约,所以就需要想办法结合 RAID 0 和 RAID 1,扬长避短,RAID 10 就这么出现了。
RAID 10 就是将 N 个磁盘平均分成两份,这两份互为镜像,相当于是 RAID 1,但对于每份磁盘中的 N/2 块磁盘来说,其存储方式像 RAID 0 一样,可以做到并发读写。这样就做到了折中,在读写速度和容错能力上有一个平衡。
我们不难看出来,RAID 10 的磁盘利用率较低,有一半的磁盘都拿来做备份了,着实有些奢侈。
就一般情况而言,服务器上很少出现同时损坏两块磁盘的情况,往往是损坏一块磁盘的时候,就换上新的磁盘,然后利用恢复技术恢复损坏磁盘上的数据,所以我们可以据此设计一个磁盘利用率更高的方案。
RAID 3 and RAID 5
有了前面的讨论,我们可以想到,如果任何一块磁盘上的数据,都能通过其它 N-1 块磁盘上的数据恢复出来,不就解决我们的问题了吗?
校验机制正好满足我们的要求。
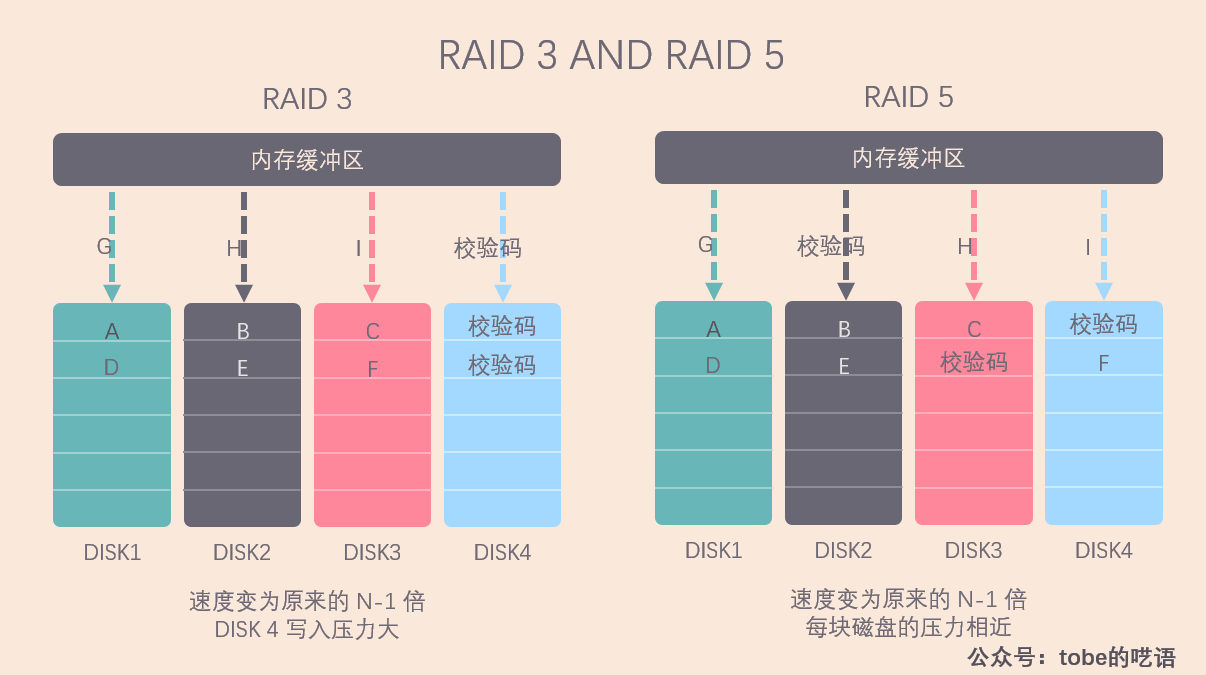
在写入磁盘的时候,我们把数据分成 N-1 份,并发写入 N-1 块磁盘,然后用剩下的一块磁盘记录校验数据,这样我们就可以容忍任意一块磁盘的损坏。
根据校验数据写入的位置,我们有了两种方案:
- RAID 3:所有的校验数据写在同一块磁盘上。在数据修改较频繁的场景下,任何一块磁盘上数据的修改都会导致校验盘要重新写入数据。这会导致校验盘比其他磁盘更容易损坏,所以 RAID 3 很少在实践中使用。用专业一点的话来说,就是负载不均衡了。
- RAID 5:校验数据螺旋式地写入所有磁盘。看上面的图就能分辨出这两种方案的差别,RAID 5 让每一块磁盘都承担一部分的校验工作,这样修改校验数据的压力也就被分散到了所有的磁盘,做到了我们所期望的负载均衡。因此 RAID 5 是使用更为广泛的方案。
RAID 6
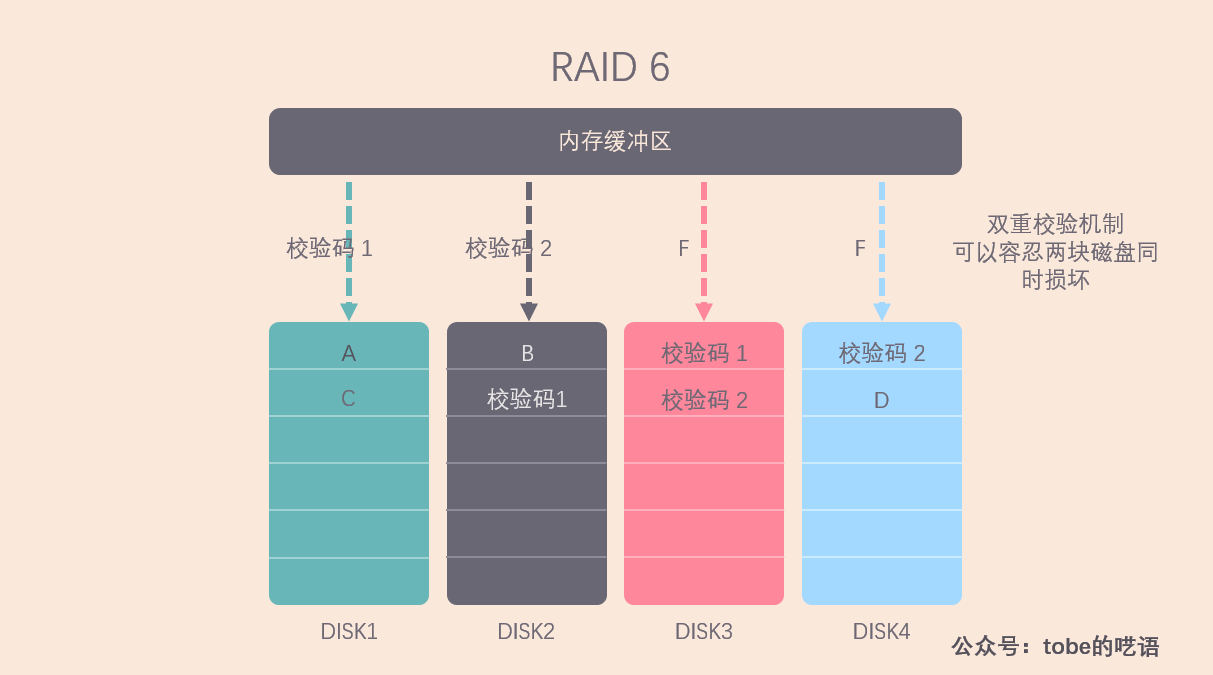
相较于 RAID 5,RAID 6 的可靠性更高,因为 RAID 6 采用了两种校验码螺旋写入的方案,这样可以容忍两块磁盘同时损坏。
什么情况下需要这样的容错能力?在大型服务器上,每块磁盘的容量往往很大,在某一块磁盘损坏后,即使立马替换上了新磁盘,也需要很长时间才能把所有数据恢复完毕,那么在这段时间里,如果有另一块磁盘损坏,数据就没办法恢复了,这是我们不能接受的,因此就需要 RAID 6 来确保数据的完整性。
分布式存储方案
PS:本文着重于分布式系统的副本与数据分布的关系,因为这部分的思想与 RAID 有相似之处,关于一致性哈希等问题将单独写一篇文章介绍。
分布式系统应对的存储规模要比单机大很多,但基本思想和设计目标都是一致的:
- 提高系统的吞吐量
- 提高系统的存储容量
- 利用数据备份,提高系统可靠性
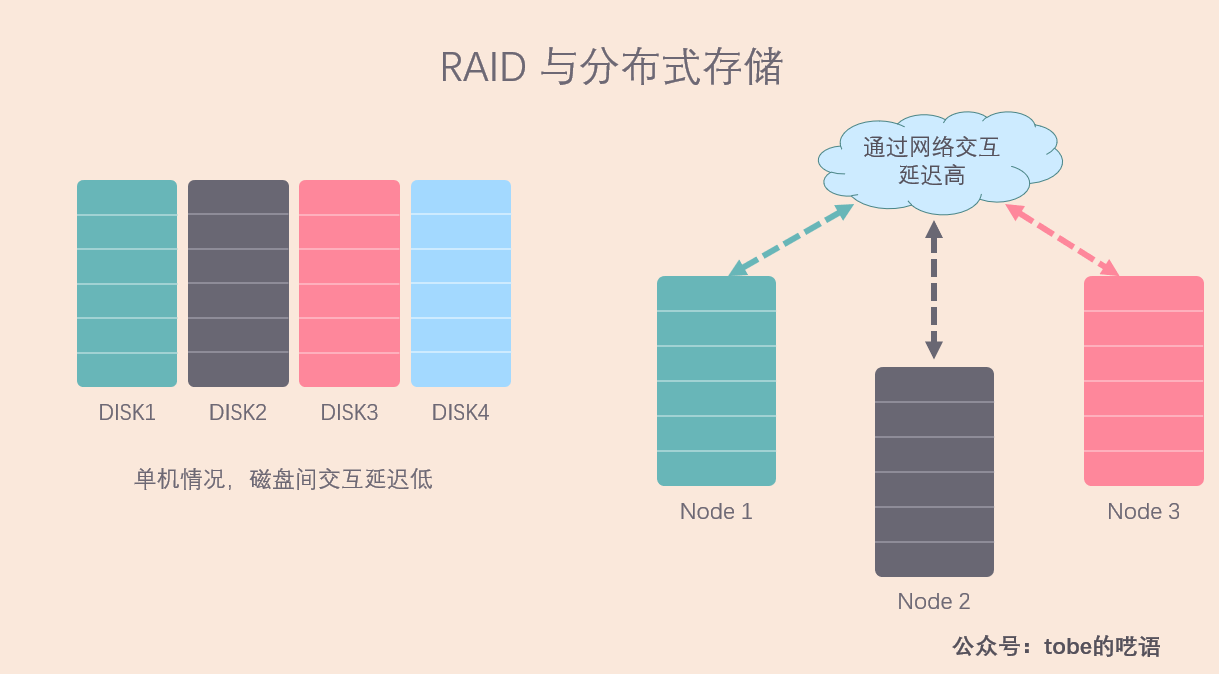
与单机情况不同,分布式系统面临的问题要多得多,因为服务器之间的数据是通过网络传输,延时较高,甚至可能会出现网络中断,导致某些机器无法访问。这对我们的存储方案有很大影响,比如,我们还能用类似 RAID 5 的校验方式来做冗余吗?
答案是否定的,因为做校验的成本太高了,一次校验需要其它 N-1 台机器的响应,一等就是几十毫秒,效率极低,而且网络负载太大了。相反,RAID 10 的方案看起来更适合现在的情况。
以机器为单位的副本
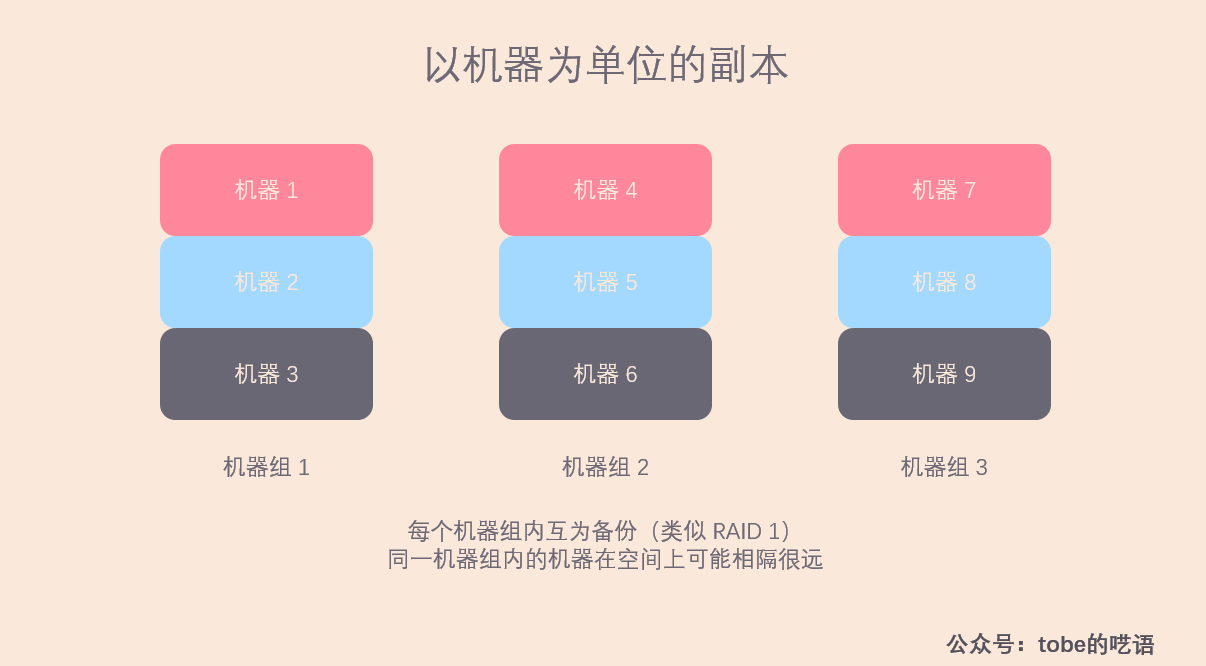
在该方式下,若干机器互为副本,副本机器之间的数据是完全一样的,就像 RAID 1 的方案一样。这种方式的优点就是简单,但缺点也很明显:
- 恢复数据的效率低:假如机器 3 磁盘损坏,丢失了所有的数据,于是我们又调度一台新机器进入该机器组,为了让该机器尽快提供服务,需要从其他两台机器上拷贝数据。但是由于网络带宽的限制,数据恢复的速度慢。
- 可扩展性不高:每个机器组有三台机器,想要扩展,就需要一次加三台机器。
- 不利于系统容错:一台机器宕机,读写压力将由剩下的两台机器承担,压力增加了 50 %,很有可能超过单台机器的处理能力。
因此,以机器作为副本单位不适合当前的场景,我们需要寻找其它的途径。
以数据段为单位的副本
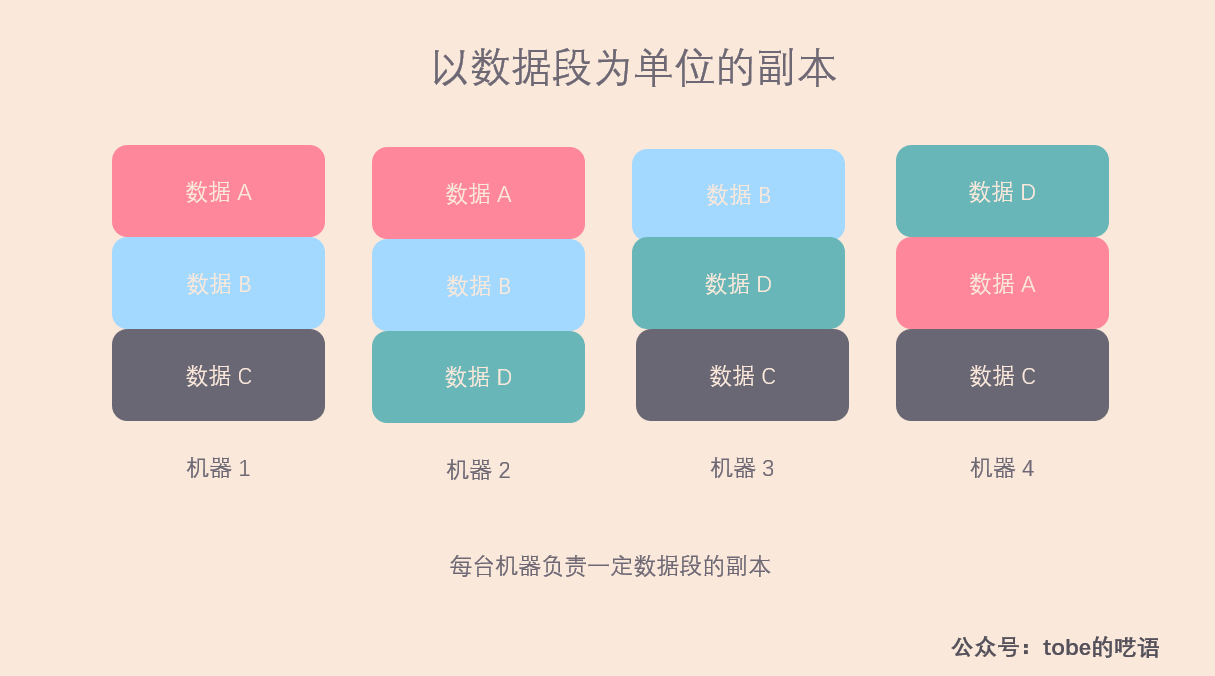
相较于以机器为副本单位,将数据拆分成以数据段为单位作为副本的灵活性更佳,下面我就用一个更直观例子来说明该方案的优点。
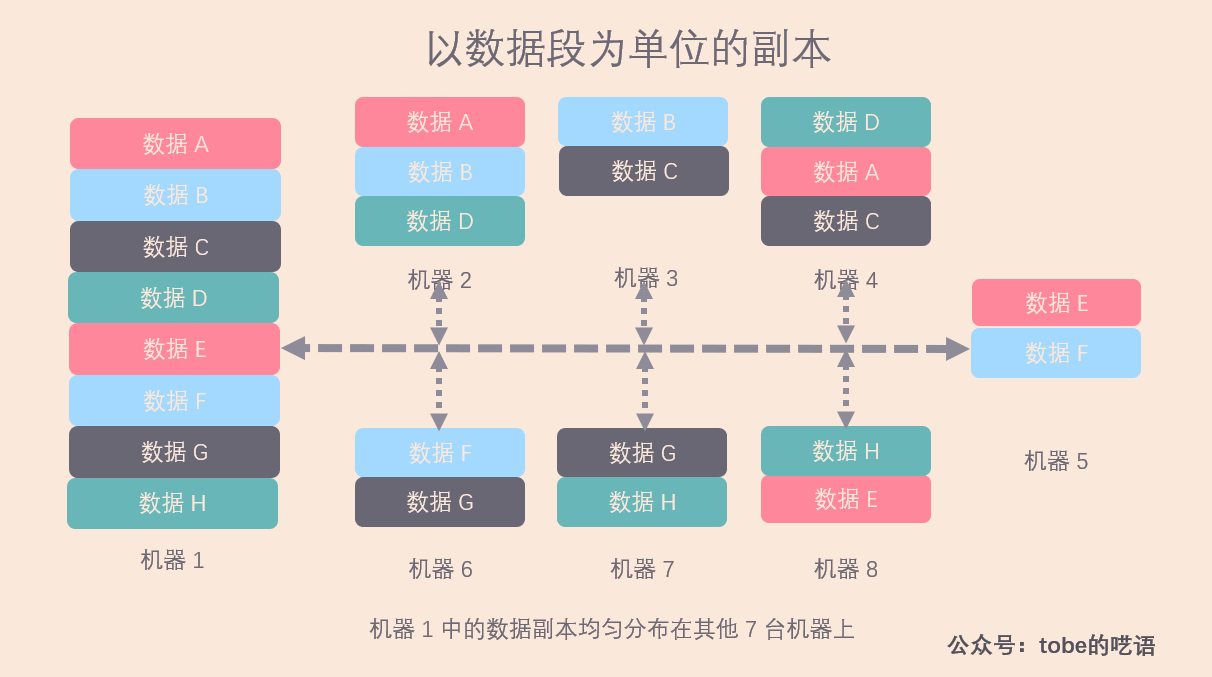
该例子下,机器 1 的所有数据都分布在其他的 7 台机器上,忽略集群中其他的机器。
这种方案为我们带来了什么好处?
- 恢复数据的效率高。假设机器 1 数据丢失,需要重新拷贝所有数据,由于数据分布在剩下的 7 台机器上,我们可以从剩下的所有机器同时拷贝恢复数据,这样,即使每台机器都以较低的资源做拷贝工作,也能很快将数据复制完毕。注意,集群越大,每台机器上承担的工作量就越小,而且实现了负载均衡。
- 集群的可扩展性高。当加入一台新的机器时,我们只需要从每台机器上迁移 1/8 比例的数据段到新机器上,实现新的负载均衡。
- 系统容错性高。假设机器 1 宕机,暂时无法提供服务,那么剩余 7 台机器的压力提高 14.3% ,可以接受。
但是这种方案不是没有问题,因为我们需要一台服务器来记录数据段与机器的对应关系,这台服务器称为元数据服务器。可以想象,随着集群规模的增长,需要管理的元数据的开销也会不断增大,副本的维护难度相应增大,所以现在一种折中的方案是,将某些数据段组成一个数据段分组,以数据段分组为粒度进行副本管理,这样,可以将副本粒度控制在一个较为合适的范围。
分布式存储的副本分布内容就介绍到这里了,希望你在看完我的文章之后有所收获,期待你的赞和转发!
如果本文对你有帮助,欢迎关注我的公众号 tobe的呓语 ,带你深入计算机的世界~ 公众号后台回复关键词【计算机】有惊喜哦~

多图预警——从 RAID 到分布式系统中的副本分布的更多相关文章
- 菜鸟到大神之多图预警——从 RAID 到分布式系统中的副本分布
我们知道,在面对大规模数据的计算和存储时,有两种处理思路: 垂直扩展(scale up):通过升级单机的硬件,如 CPU.内存.磁盘等,提高计算机的处理能力. 水平扩展(scale out):通过添加 ...
- 分布式系统中生成全局ID的总结与思考
世间万物,都有自己唯一的标识,比如人,每个人都有自己的指纹(白夜追凶给我科普的,同卵双胞胎DNA一样,但指纹不一样).又如中国人,每个中国人有自己的身份证.对于计算机,很多时候,也需要为每一份数据生成 ...
- 分布式系统中的必备良药 —— RPC
阅读目录 前言 成熟的解决方案 剖析 性能测试 结语 一.前言 在上一篇分布式系统系列中<分布式系统中的必备良药 —— 服务治理>中阐述了服务治理的一些概念,那么与服务治理配套的必然会涉及 ...
- Spring整合Quartz定时任务 在集群、分布式系统中的应用(Mysql数据库环境)
Spring整合Quartz定时任务 在集群.分布式系统中的应用(Mysql数据库环境) 转载:http://www.cnblogs.com/jiafuwei/p/6145280.html 单个Q ...
- Netflix Hystrix — 应对复杂分布式系统中的延时和故障容错 转
转自 https://segmentfault.com/a/1190000005988895 前言 分布式系统中经常会出现某个基础服务不可用造成整个系统不可用的情况, 这种现象被称为服务雪崩效应. 为 ...
- 一条SQL在 MaxCompute 分布式系统中的旅程
摘要:2019杭州云栖大会大数据技术专场,由阿里云资深技术专家侯震宇.阿里云高级技术专家陈颖达以及阿里云资深技术专家戴谢宁共同以“SQL在 MaxCompute 分布式系统中的旅程 ”为题进行了演讲. ...
- 如何在高并发分布式系统中生成全局唯一Id
月整理出来,有兴趣的园友可以关注下我的博客. 分享原由,最近公司用到,并且在找最合适的方案,希望大家多参与讨论和提出新方案.我和我的小伙伴们也讨论了这个主题,我受益匪浅啊…… 博文示例: 1. ...
- 【分布式】Zookeeper在大型分布式系统中的应用
一.前言 上一篇博文讲解了Zookeeper的典型应用场景,在大数据时代,各种分布式系统层出不穷,其中,有很多系统都直接或间接使用了Zookeeper,用来解决诸如配置管理.分布式通知/协调.集群管理 ...
- 分布式系统中一些主要的副本更新策略——Dynamo/Cassandra/Riak同时采取了主从式更新的同步+异步类型,以及任意节点更新的策略。
分布式系统中一些主要的副本更新策略. 1.同时更新 类型A:没有任何协议,可能出现多个节点执行顺序交叉导致数据不一致情况. 类型B:通过一致性协议唯一确定不同更新操作的执行顺序,从而保证数据一致性 2 ...
随机推荐
- Spring Cloud Eureka------详解
一 Eureka服务治理体系 1.1 服务治理 服务治理是微服务架构中最为核心和基础的模块,它主要用来实现各个微服务实例的自动化注册和发现. Spring Cloud Eureka是Spring Cl ...
- 【Java并发基础】安全性、活跃性与性能问题
前言 Java的多线程是一把双刃剑,使用好它可以使我们的程序更高效,但是出现并发问题时,我们的程序将会变得非常糟糕.并发编程中需要注意三方面的问题,分别是安全性.活跃性和性能问题. 安全性问题 我们经 ...
- NOI2.5 1253:Dungeon Master
描述 You are trapped in a 3D dungeon and need to find the quickest way out! The dungeon is composed of ...
- Python脚本通过ftp协议移植文件
需求 项目需要定时移植多个客户服务器的文件到公司服务器上,确保文件定时同步和生成监控日志 机制原理 1.客户和公司服务器同时安装vpn,绕过复杂的网关,linux下使用的OpenVPN 2.服务器定时 ...
- oracle 11g数据库服务器安装
系统:windows7旗舰版 64位.oracle数据库服务器版本:oracle11g. 一.下载 1.登录oracle账户: 首先打开谷歌浏览器,输入网址[英文版网址:https://www.o ...
- PSR标准规范
PSR标准规范 基本代码规范 PHP代码文件 必须 以 不带 BOM 的 UTF-8 编码: 类的命名 必须 遵循 StudlyCaps 大写开头的驼峰命名规范: 类中的常量所有字母都 必须 大写,单 ...
- sql 映射文件
...
- 使用自定义注解和springAOP捕获Service层异常,并处理自定义异常
一 自定义异常 /** * 自定义参数为null异常 */ public class NoParamsException extends Exception { //用详细信息指定一个异常 publi ...
- Java Email 邮件发送
自己所编码的项目出现了问题,且是 24 小时运行于服务器上的. 如果出错了,那么我们也无从而知. 这个时候,只能通过异常捕获,然后将异常信息发送至开发者的邮箱上. 但是一个邮件的发送配置冗长,代码量至 ...
- 编译调试 .NET Core 5.0 Preview 并分析 Span 的实现原理
很久没有写过 .NET Core 相关的文章了,目前关店在家休息所以有些时间写一篇新的