实战ELK(5) Logstash 入门
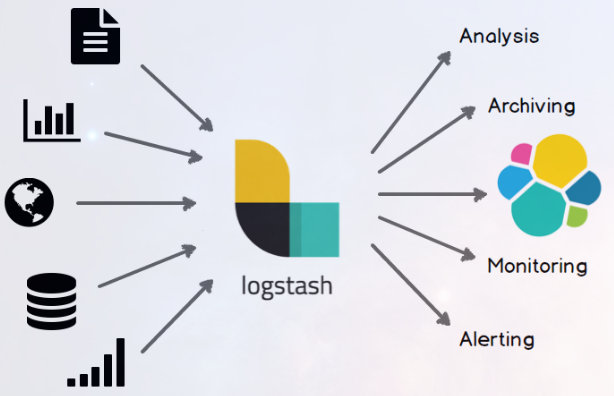
Logstash 是一个开源的数据收集引擎,它具有备实时数据传输能力。它可以统一过滤来自不同源的数据,并按照开发者的制定的规范输出到目的地。
一、原理
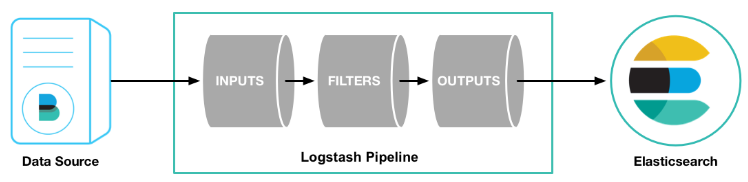
Logstash 通过管道进行运作,管道有两个必需的元素,输入和输出,还有一个可选的元素,过滤器。
输入插件从数据源获取数据,过滤器插件根据用户指定的数据格式修改数据,输出插件则将数据写入到目的地。如下图:
输入:采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。

过滤器:实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响:
- 利用 Grok 从非结构化数据中派生出结构
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化,完全排除敏感字段
- 整体处理不受数据源、格式或架构的影响

输出:选择你的存储,导出你的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。

二、安装
2.1、下载
Logstash 依赖 JDK1.8 ,因此在安装之前请确保机器已经安装和配置好 JDK1.8。
Logstash 下载:https://artifacts.elastic.co/downloads/logstash/logstash-6.5.1.rpm
2.2、安装
yum install logstash-6.5..rpm
查看启动文件来了解下文件目录
vim /etc/systemd/system/logstash.service
常用的目录:
/etc/default/logstash
/etc/sysconfig/logstash
/usr/share/logstash/bin/logstash
/etc/logstash
2.3、设置执行权限
- 方法1,修改
logstash.service
vim /etc/systemd/system/logstash.service
User=root #直接以root账户允许
Group=root
- 方法2
chown -R logstash:logstash /var/lib/logstash
chown -R logstash:logstash /var/log/logstash
2.4 、开机启动
systemctl start logstash.service
systemctl enable logstash.service
systemctl status logstash.service
2.5、我们先来一个简单的案例:
cd /usr/share/logstash
bin/logstash -e 'input { stdin { } } output { stdout {} }'
可能会有点慢

这时候输入个Hello World

在生产环境中,Logstash 的管道要复杂很多,可能需要配置多个输入、过滤器和输出插件。
因此,需要一个配置文件管理输入、过滤器和输出相关的配置。配置文件内容格式如下:
# 输入
input {
...
} # 过滤器
filter {
...
} # 输出
output {
...
}
根据自己的需求在对应的位置配置 输入插件、过滤器插件、输出插件 和 编码解码插件 即可。
三、插件用法
Logstash 每读取一次数据的行为叫做事件。
在 Logstach 目录中创建一个配置文件,名为 logstash.conf(名字任意)。
cd /usr/share/logstash
3.1 输入插件
输入插件允许一个特定的事件源可以读取到 Logstash 管道中,配置在 input {} 中,且可以设置多个。
修改配置文件:
input {
# 从文件读取日志信息
file {
path => "/var/log/elasticsearch/"
type => "elasticsearch"
start_position => "beginning"
}
}
# filter {
#
# }
output {
# 标准输出
stdout { codec => rubydebug }
}
其中,messages 为系统日志。
保存文件。键入:
bin/logstash -f logstash.conf
3.2 输出插件
输出插件将事件数据发送到特定的目的地,配置在 output {} 中,且可以设置多个。
修改配置文件:
input {
# 从文件读取日志信息
file {
path => "/var/log/error.log"
type => "error"
start_position => "beginning"
}
}
# filter {
#
# }
output {
# 输出到 elasticsearch
elasticsearch {
hosts => ["192.168.50.70:9200"]
index => "error-%{+YYYY.MM.dd}"
}
}
保存文件。键入:
bin/logstash -f logstash.conf
3.3 编码解码插件
编码解码插件本质是一种流过滤器,配合输入插件或输出插件使用。
从上图中,我们发现一个问题:Java 异常日志被拆分成单行事件记录到 Elasticsearch 中,这不符合开发者或运维人员的查看习惯。因此,我们需要对日志信息进行编码将多行事件转成单行事件记录起来。
我们需要配置 Multiline codec 插件,这个插件可以将多行日志信息合并成一行,作为一个事件处理。
Logstash 默认没有安装该插件,需要开发者自行安装。键入:
bin/logstash-plugin install logstash-codec-multiline
修改配置文件:
input {
# 从文件读取日志信息
file {
path => "/var/log/error.log"
type => "error"
start_position => "beginning"
# 使用 multiline 插件
codec => multiline {
# 通过正则表达式匹配,具体配置根据自身实际情况而定
pattern => "^\d"
negate => true
what => "previous"
}
}
}
# filter {
#
# }
output {
# 输出到 elasticsearch
elasticsearch {
hosts => ["192.168.2.41:9200"]
index => "error-%{+YYYY.MM.dd}"
}
}
保存文件。键入:
bin/logstash -f logstash.conf
4.4 过滤器插件
过滤器插件位于 Logstash 管道的中间位置,对事件执行过滤处理,配置在 filter {},且可以配置多个。
本次测试使用 grok 插件演示,grok 插件用于过滤杂乱的内容,将其结构化,增加可读性。
安装:
bin/logstash-plugin install logstash-filter-grok
修改配置文件:
input {
stdin {}
}
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER
:duration}" }
}
}
output {
stdout {
codec => "rubydebug"
}
}
保存文件。键入:
bin/logstash -f logstash.conf
启动成功后,我们输入:
55.3.244.1 GET /index.html 0.043
控制台返回:
[root@localhost logstash-5.6.]# bin/logstash -f logstash.conf
Sending Logstash's logs to /root/logstash-5.6.3/logs which is now configured via log4j2.properties
[--30T08::,][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/root/logstash-5.6.3/modules/fb_apache/configuration"}
[--30T08::,][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/root/logstash-5.6.3/modules/netflow/configuration"}
[--30T08::,][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>, "pipeline.batch.size"=>, "pipeline.batch.delay"=>, "pipeline.max_inflight"=>}
The stdin plugin is now waiting for input:
[--30T08::,][INFO ][logstash.pipeline ] Pipeline main started
[--30T08::,][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>}
55.3.244.1 GET /index.html 0.043
{
"duration" => "0.043",
"request" => "/index.html",
"@timestamp" => --30T15::.912Z,
"method" => "GET",
"bytes" => "",
"@version" => "",
"host" => "localhost.localdomain",
"client" => "55.3.244.1",
"message" => "55.3.244.1 GET /index.html 15824 0.043"
}
输入的内容被匹配到相应的名字中。
实战ELK(5) Logstash 入门的更多相关文章
- ElasticSearch实战系列六: Logstash快速入门和实战
前言 本文主要介绍的是ELK日志系统中的Logstash快速入门和实战 ELK介绍 ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是 ...
- ElasticSearch实战系列七: Logstash实战使用-图文讲解
前言 在上一篇中我们介绍了Logstash快速入门,本文主要介绍的是ELK日志系统中的Logstash的实战使用.实战使用我打算从以下的几个场景来进行讲解. 时区问题解决方案 在我们使用logstas ...
- K8S(15)监控实战-ELK收集K8S内应用日志
K8S监控实战-ELK收集K8S内应用日志 目录 K8S监控实战-ELK收集K8S内应用日志 1 收集K8S日志方案 1.1 传统ELk模型缺点: 1.2 K8s容器日志收集模型 2 制作tomcat ...
- ELK技术-Logstash
1.背景 1.1 简介 Logstash 是一个功能强大的工具,可与各种部署集成. 它提供了大量插件,可帮助业务做解析,丰富,转换和缓冲来自各种来源的数据. Logstash 是一个数据流引擎 它是用 ...
- 使用ELK(Elasticsearch + Logstash + Kibana) 搭建日志集中分析平台实践--转载
原文地址:https://wsgzao.github.io/post/elk/ 另外可以参考:https://www.digitalocean.com/community/tutorials/how- ...
- maven3实战之maven使用入门(使用archetype生成项目骨架)
maven3实战之maven使用入门(使用archetype生成项目骨架) ---------- maven提供了archetype以帮助我们快速勾勒出项目骨架.以Hello World为例,我们使用 ...
- ELk(Elasticsearch, Logstash, Kibana)的安装配置
目录 ELk(Elasticsearch, Logstash, Kibana)的安装配置 1. Elasticsearch的安装-官网 2. Kibana的安装配置-官网 3. Logstash的安装 ...
- [转] ELK 之 Logstash
[From] https://blog.csdn.net/iguyue/article/details/77006201 ELK 之 Logstash 简介: ELK 之 LogstashLogsta ...
- CentOS 6.x ELK(Elasticsearch+Logstash+Kibana)
CentOS 6.x ELK(Elasticsearch+Logstash+Kibana) 前言 Elasticsearch + Logstash + Kibana(ELK)是一套开源的日志管理方案, ...
- 基于CentOS6.5或Ubuntu14.04下Suricata里搭配安装 ELK (elasticsearch, logstash, kibana)(图文详解)
前期博客 基于CentOS6.5下Suricata(一款高性能的网络IDS.IPS和网络安全监控引擎)的搭建(图文详解)(博主推荐) 基于Ubuntu14.04下Suricata(一款高性能的网络ID ...
随机推荐
- PHP socket服务端与客户端的简易通信
今天学习socket通信的同时,顺便整理了下以前初识socket的知识. 现在关于php的socket通信,有些框架已经十分成熟了,比如 swoole 和 workerman,这两个大家可以学习学习 ...
- Django学习教程
教程link:https://code.ziqiangxuetang.com/django/django-install.html 最好用虚拟环境学习django,用pycharm时要注意所选的pyt ...
- ubuntu下安装php7
apt-cache pkgnames | grep php7.0 sudo apt-get install -y php7.0 libapache2-mod-php7.0 php7.0-cli php ...
- Java实现数据库与eclipse的连接
JavaBean:用于传递数据,拥有与数据相关的逻辑处理 JSP:从Model接收数据并生成HTML Servlet:接收HTTP请求并控制Model和View jdbc:用于驱动连接 一.[建立数据 ...
- Ubuntu Server 16.04设置WiFi
wifi :http://www.cnblogs.com/joeyupdo/p/3350463.html http://blog.csdn.net/meic51/article/details/173 ...
- 直接借鉴的 ids拼接
function _getIds(selectedIds, targetType){ var ids = ""; var $box = targetType == "di ...
- linux基础之bash特性
linux基础之bash特性 1.命令历史 命令历史包含的环境变量 $HISTSIZE:命令历史记录的条数 $HISTFILE:命令历史文件~/.bash_history $HISTFILESIZE: ...
- RabbitMQ安装记录(windows10)
RabbitMQ安装记录(windows10) 一.安装包准备 otp_win64_R16B03.exe(这里使用该版本,不支持ssl) otp_win64_19.0.exe(如果要开启ssl,请 ...
- zombodb 几点说明
内容来自官方文档,截取部分 默认es 索引的副本为0 这个参考可以通过修改索引,或者在创建的时候通过with 参数指定,或者通过pg 的配置文件中指定 索引更多的列以为这使用了更多的es 能力 索引的 ...
- 一 Struts框架(下)
1 struts FORM 标签 与jstl标准标签库类似的,struts有专属标签库 form标签用于提交数据 修改addProduct.jsp <%@ page contentType=&q ...