Tensorflow-hub[例子解析1]
0. 引言
Tensorflow于1.7之后推出了tensorflow hub,其是一个适合于迁移学习的部分,主要通过将tensorflow的训练好的模型进行模块划分,并可以再次加以利用。不过介于推出不久,目前只有图像的分类和文本的分类以及少量其他模型
这里先通过几个简单的例子,来展示该hub的使用流程。
1. 一个超简单例子
1.1 创建一个Module
#该文件名为half_plus_two.py
'''1 - 导入模块 '''
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import tensorflow as tf
import tensorflow_hub as hub
'''2 - 建立一个网络结构,并基于该网络结构建立一个Module '''
def half_plus_two():
'''该函数主要是创建一个简单的模型,其网络结构就是y = a*x + b '''
# 创建两个变量,a和b,如网络的权重和偏置
a = tf.get_variable('a', shape=[])
b = tf.get_variable('b', shape=[])
# 创建一个占位变量,为后面graph的输入提供准备
x = tf.placeholder(tf.float32)
# 创建一个完整的graph
y = a*x + b
# 通过hub的add_signature,建立hub需要的网络
hub.add_signature(inputs=x, outputs=y)
def export_module(path):
'''该函数用于调用创建api进行module创建,然后进行网络的权重赋值,最后通过session进行运行权重初始化,并最后输出该module'''
# 通过hub的create_module_spec,接收函数建立一个Module
spec = hub.create_module_spec(half_plus_two)
# 防止串graph,将当期的操作放入同一个graph中
with tf.Graph().as_default():
# 通过hub的Module读取一个模块,该模块可以是url链接,表示从tensorflow hub去拉取,
# 或者接收上述创建好的module
module = hub.Module(spec)
# 这里演示如何将权重值赋予到graph中的变量,如从checkpoint中进行变量恢复等
init_a = tf.assign(module.variable_map['a'], 0.5)
init_b = tf.assign(module.variable_map['b'], 2.0)
init_vars = tf.group([init_a, init_b])
with tf.Session() as sess:
# 运行初始化,为了将其中变量的值设置为赋予的值
sess.run(init_vars)
# 将模型导出到指定路径
module.export(path,sess)
def main(argv):
try:
_, export_path = argv
except ValueError:
raise ValueError('Usage: %s <export-path>'%argv[0])
if tf.gfile.Exists(export_path):
raise RuntimeError('Path %s already exists.'%export_path)
export_module(export_path)
if __name__ == '__main__':
tf.app.run(main)
上述代码编写完毕后,可运行
CUDA_VISIBLE_DEVICES='1' python half_plus_two.py
会生成如下形式:
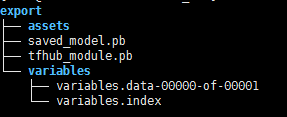
可以看出,该例子中,生成一个Module是
- 1 - 先通过自定义网络,然后通过 hub.add_signature(inputs=x, outputs=y) 进行类似注册的操作
- 2 - 再通过hub.create_module_spec(half_plus_two)进行生成ModuleSpec对象
- 3 - 创建一个独立的tf.Graph(),通过module = hub.Module(spec)进行装载该Module,然后进行权重赋值,初始化等操作
- 4 - 最后通过module.export(path,sess)导出该Module
1.2 调用一个存在的Module
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import subprocess
import tensorflow as tf
import tensorflow_hub as hub
class HalfPlusTwoTests(tf.test.TestCase):
def testExportTool(self):
# 指定module的文件夹位置,这里是export
module_path = os.path.join('.','export')
with tf.Graph().as_default():
# 读取当前存在的一个module
m = hub.Module(module_path)
# 如直接采用y=f(x) 一样进行调用,
output= m([10,3,4])
with tf.Session() as sess:
# 惯例进行全局变量初始化
sess.run(tf.initializers.global_variables())
# 观察生成的值是否与预定义值一致,即prediction是否与label一致
self.assertAllEqual(sess.run(output), [7, 3.5, 4])
if __name__ == '__main__':
tf.test.main()
对于调用来说,就十分简单了
- 1 - 创建一个tf.Graph(),然后通过m = hub.Module(module_path)进行装载已存在的Module
- 2 - 如y=f(x)一样进行调用
- 3 - sess.run一下即可。
2 图像分类的retrain
这里的例子展示了,更细节的操作,这里没使用module.export()接口,而是通过之前版本提供的如tf.train.Saver()去保存checkpoint,tf.graph_util.convert_variables_to_constants()去保存成pb,tf.saved_model.builder. SavedModelBuilder()等接口去保存成tensorflow serving的saved_model。所以相对繁琐很多
该工作是基于tensorflow/examples/image_retraining,这里只是将其修改为使用hub模块的形式(详细信息可参考:image)。该例子展示了如何使用基于tensorflow hub的模型来进行图像分类器的再训练,这里使用的是在ImageNet上训练的Inception v3模型,并且输出就是softmax之前的那个2048维度的特征,说白了就是将inception v3作为一个特征提取器(如sift一样),通过增加一个softmax分类器达到不同类别个数的图像分类任务的retrian。该模型针对每个图片的参数量有2048*N+N个(权重和偏置,N表示图片类别)。
假设训练集的结构如下:
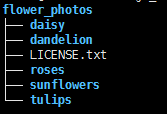
~/flower_photos/daisy/photo1.jpg
~/flower_photos/daisy/photo2.jpg
...
~/flower_photos/rose/anotherphoto77.jpg
...
~/flower_photos/sunflower/somepicture.jpg
其中主要是子文件夹以图像类别命名,每个子文件夹中都存放了当前类别的图像样本,如可以下载tensorflow的例子样本。一旦准备好了训练集,可运行如下命令:
python retrain.py --image_dir ~/flower_photos
这里默认是采用inceptionv3,如果你资源有限,可以采用如Mobilenet,只要运行如下命令:
python retrain.py --image_dir ~/flower_photos \
--tfhub_module https://tfhub.dev/google/imagenet/mobilenet_v1_100_224/feature_vector/1
当然针对Mobilenet也有一些不同的参数用于选择不同的网络结构,mobilenet_v1_100_224:
- 第一个100还能取值[100,075,050,025],表示神经元个数(隐藏层激活单元),对应的权重个数也是以平方级别不断的减少;
- 第二个224表示输入图片的size,还能取值[224,192,160,128],当然更小的图片输入,网络的运行速度也会更快
默认情况下,该脚本的日志写在/tmp/retrain_logs路径下,所以可以:
tensorboard --logdir /tmp/retrain_logs
进行实时观察。如果想要使用tensorflow serving,可以如下运行
python retrain.py (... other args as before ...) \
--saved_model_dir=/tmp/saved_models/$(date +%s)/ \
tensorflow_model_server --port=9000 --model_name=my_image_classifier \
--model_base_path=/tmp/saved_models/
为了更好的理解该例子,可以先看main函数,先了解整个过程的操作流程,待需要详细了解某个点时,再去观察上面的函数。
''' 本文件为retrain.py'''
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import collections
from datetime import datetime
import hashlib
import os.path
import random
import re
import sys
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
FLAGS = None
MAX_NUM_IMAGES_PER_CLASS = 2 ** 27 - 1 # ~134M
# The location where variable checkpoints will be stored.
CHECKPOINT_NAME = '/tmp/_retrain_checkpoint'
# 当一个module包含如下ops时,该module会被理解为通过TF-lite进行量化过的模型
FAKE_QUANT_OPS = ('FakeQuantWithMinMaxVars',
'FakeQuantWithMinMaxVarsPerChannel')
def create_image_lists(image_dir, testing_percentage, validation_percentage):
""" 分析用户按照预定格式准备的图片数据集,提取其中的子文件夹作为图片的标签,并将所有数据集分成训练集,验证集,测试集
Args:
image_dir: 按照预定格式准备的数据集路径,其中子文件夹表示类别,子文件夹中图片表示类别对应样本.
testing_percentage: 用于做测试的比例.
validation_percentage: 用于做验证的比例.
Returns:
一个OrderedDict数据结构,其中包含了 containing an entry for each label subfolder, with images
split into training, testing, and validation sets within each label.
The order of items defines the class indices.
"""
if not tf.gfile.Exists(image_dir):
tf.logging.error("Image directory '" + image_dir + "' not found.")
return None
result = collections.OrderedDict()
# 读取子文件夹名称并排序,过滤掉image_dir这个路径,保留其中的子文件夹路径
sub_dirs = sorted(x[0] for x in tf.gfile.Walk(image_dir))
sub_dirs= list(filter(lambda sub_dir: sub_dir != image_dir, sub_dirs))
for sub_dir in sub_dirs:
extensions = ['jpg', 'jpeg', 'JPG', 'JPEG']
file_list = []
dir_name = os.path.basename(sub_dir)
tf.logging.info("Looking for images in '" + dir_name + "'")
[ file_list.extend(tf.gfile.Glob(f'{image_dir}/{sub_dir}/*.{extension}')) for extension in extensions ]
if not file_list:
tf.logging.warning('No files found')
continue
if len(file_list) < 20:
tf.logging.warning(
'WARNING: 该文件夹内少于 20 张图片, 这会引发某些问题.')
elif len(file_list) > MAX_NUM_IMAGES_PER_CLASS:
tf.logging.warning(
f'WARNING: 文件夹 {dir_name} 超过预定最大值 {MAX_NUM_IMAGES_PER_CLASS} 张图片. 其中一些图片将会被忽略'
label_name = re.sub(r'[^a-z0-9]+', ' ', dir_name.lower())
training_images = []
testing_images = []
validation_images = []
for file_name in file_list:
base_name = os.path.basename(file_name)
# We want to ignore anything after '_nohash_' in the file name when
# deciding which set to put an image in, the data set creator has a way of
# grouping photos that are close variations of each other. For example
# this is used in the plant disease data set to group multiple pictures of
# the same leaf.
hash_name = re.sub(r'_nohash_.*$', '', file_name)
# This looks a bit magical, but we need to decide whether this file should
# go into the training, testing, or validation sets, and we want to keep
# existing files in the same set even if more files are subsequently
# added.
# To do that, we need a stable way of deciding based on just the file name
# itself, so we do a hash of that and then use that to generate a
# probability value that we use to assign it.
hash_name_hashed = hashlib.sha1(tf.compat.as_bytes(hash_name)).hexdigest()
percentage_hash = ((int(hash_name_hashed, 16) %
(MAX_NUM_IMAGES_PER_CLASS + 1)) *
(100.0 / MAX_NUM_IMAGES_PER_CLASS))
if percentage_hash < validation_percentage:
validation_images.append(base_name)
elif percentage_hash < (testing_percentage + validation_percentage):
testing_images.append(base_name)
else:
training_images.append(base_name)
result[label_name] = {
'dir': dir_name,
'training': training_images,
'testing': testing_images,
'validation': validation_images,
}
return result
def get_image_path(image_lists, label_name, index, image_dir, category):
"""就为了得到图片的完整路径
Args:
image_lists: OrderedDict of training images for each label.
label_name: Label string we want to get an image for.
index: Int offset of the image we want. This will be moduloed by the
available number of images for the label, so it can be arbitrarily large.
image_dir: Root folder string of the subfolders containing the training
images.
category: Name string of set to pull images from - training, testing, or
validation.
Returns:
File system path string to an image that meets the requested parameters.
"""
if label_name not in image_lists:
tf.logging.fatal('Label does not exist %s.', label_name)
label_lists = image_lists[label_name]
if category not in label_lists:
tf.logging.fatal('Category does not exist %s.', category)
category_list = label_lists[category]
if not category_list:
tf.logging.fatal('Label %s has no images in the category %s.',
label_name, category)
mod_index = index % len(category_list)
base_name = category_list[mod_index]
sub_dir = label_lists['dir']
full_path = os.path.join(image_dir, sub_dir, base_name)
return full_path
def get_bottleneck_path(image_lists, label_name, index, bottleneck_dir,
category, module_name):
"""Returns a path to a bottleneck file for a label at the given index.
Args:
image_lists: OrderedDict of training images for each label.
label_name: Label string we want to get an image for.
index: Integer offset of the image we want. This will be moduloed by the
available number of images for the label, so it can be arbitrarily large.
bottleneck_dir: Folder string holding cached files of bottleneck values.
category: Name string of set to pull images from - training, testing, or
validation.
module_name: The name of the image module being used.
Returns:
File system path string to an image that meets the requested parameters.
"""
module_name = (module_name.replace('://', '~') # URL scheme.
.replace('/', '~') # URL and Unix paths.
.replace(':', '~').replace('\\', '~')) # Windows paths.
return get_image_path(image_lists, label_name, index, bottleneck_dir,
category) + '_' + module_name + '.txt'
def create_module_graph(module_spec):
"""创建一个graph,然后将hub module塞进去.
Args:
module_spec: the hub.ModuleSpec for the image module being used.
Returns:
graph: the tf.Graph that was created.
bottleneck_tensor: the bottleneck values output by the module.
resized_input_tensor: the input images, resized as expected by the module.
wants_quantization: a boolean, whether the module has been instrumented
with fake quantization ops.
"""
'''通过指定的module_spec,得到输入端要求的图像size '''
height, width = hub.get_expected_image_size(module_spec)
''' 创建一个graph'''
with tf.Graph().as_default() as graph:
resized_input_tensor = tf.placeholder(tf.float32, [None, height, width, 3])
m = hub.Module(module_spec)
'''通过如y=f(x)计算得到输入图片的bottleneck张量,这里就是一个矩阵,表示一个样本,列表示样本特征维度 '''
bottleneck_tensor = m(resized_input_tensor)
'''通过图中节点是否包含某些特定操作来判断该图是否是通过tf.lite进行量化过的 '''
wants_quantization = any(node.op in FAKE_QUANT_OPS
for node in graph.as_graph_def().node)
# 返回graph,模型bottleneck节点,输入端占位节点,是否是tf.lite量化的bool值
return graph, bottleneck_tensor, resized_input_tensor, wants_quantization
def run_bottleneck_on_image(sess, image_data, image_data_tensor,
decoded_image_tensor, resized_input_tensor,
bottleneck_tensor):
"""该函数用于
1 - 将磁盘上图片二进制读取,解析成tf结构图片(顺带做预处理)
2 - 将上述预处理的图片转换成numpy形式,然后过一遍网络,得到该图片的最后一层的特征向量
Runs inference on an image to extract the 'bottleneck' summary layer.
Args:
sess: Current active TensorFlow Session.
image_data: String of raw JPEG data.
image_data_tensor: Input data layer in the graph.
decoded_image_tensor: Output of initial image resizing and preprocessing.
resized_input_tensor: The input node of the recognition graph.
bottleneck_tensor: Layer before the final softmax.
Returns:
Numpy array of bottleneck values.
"""
# 先解码JPEG图像(以二进制字符串输入),然后resize,然后进行rescale像素值.,生成numpy形式
resized_input_values = sess.run(decoded_image_tensor,
{image_data_tensor: image_data})
# 将上述预处理的后的numpy形式图片输入到网络中,获取该batch图片的bottleneck 张量.
bottleneck_values = sess.run(bottleneck_tensor,
{resized_input_tensor: resized_input_values})
bottleneck_values = np.squeeze(bottleneck_values)
return bottleneck_values
def ensure_dir_exists(dir_name):
"""保证该文件夹存在于磁盘上,如果没有,则建立一个空文件夹.
Args:
dir_name: Path string to the folder we want to create.
"""
if not os.path.exists(dir_name):
os.makedirs(dir_name)
def create_bottleneck_file(bottleneck_path, image_lists, label_name, index,
image_dir, category, sess, jpeg_data_tensor,
decoded_image_tensor, resized_input_tensor,
bottleneck_tensor):
"""Create a single bottleneck file."""
tf.logging.info('Creating bottleneck at ' + bottleneck_path)
image_path = get_image_path(image_lists, label_name, index,
image_dir, category)
if not tf.gfile.Exists(image_path):
tf.logging.fatal('File does not exist %s', image_path)
image_data = tf.gfile.FastGFile(image_path, 'rb').read()
try:
bottleneck_values = run_bottleneck_on_image(
sess, image_data, jpeg_data_tensor, decoded_image_tensor,
resized_input_tensor, bottleneck_tensor)
except Exception as e:
raise RuntimeError('Error during processing file %s (%s)' % (image_path,
str(e)))
bottleneck_string = ','.join(str(x) for x in bottleneck_values)
with open(bottleneck_path, 'w') as bottleneck_file:
bottleneck_file.write(bottleneck_string)
def get_or_create_bottleneck(sess, image_lists, label_name, index, image_dir,
category, bottleneck_dir, jpeg_data_tensor,
decoded_image_tensor, resized_input_tensor,
bottleneck_tensor, module_name):
"""Retrieves or calculates bottleneck values for an image.
If a cached version of the bottleneck data exists on-disk, return that,
otherwise calculate the data and save it to disk for future use.
Args:
sess: The current active TensorFlow Session.
image_lists: OrderedDict of training images for each label.
label_name: Label string we want to get an image for.
index: Integer offset of the image we want. This will be modulo-ed by the
available number of images for the label, so it can be arbitrarily large.
image_dir: Root folder string of the subfolders containing the training
images.
category: Name string of which set to pull images from - training, testing,
or validation.
bottleneck_dir: Folder string holding cached files of bottleneck values.
jpeg_data_tensor: The tensor to feed loaded jpeg data into.
decoded_image_tensor: The output of decoding and resizing the image.
resized_input_tensor: The input node of the recognition graph.
bottleneck_tensor: The output tensor for the bottleneck values.
module_name: The name of the image module being used.
Returns:
Numpy array of values produced by the bottleneck layer for the image.
"""
label_lists = image_lists[label_name]
sub_dir = label_lists['dir']
sub_dir_path = os.path.join(bottleneck_dir, sub_dir)
ensure_dir_exists(sub_dir_path)
bottleneck_path = get_bottleneck_path(image_lists, label_name, index,
bottleneck_dir, category, module_name)
if not os.path.exists(bottleneck_path):
create_bottleneck_file(bottleneck_path, image_lists, label_name, index,
image_dir, category, sess, jpeg_data_tensor,
decoded_image_tensor, resized_input_tensor,
bottleneck_tensor)
with open(bottleneck_path, 'r') as bottleneck_file:
bottleneck_string = bottleneck_file.read()
did_hit_error = False
try:
bottleneck_values = [float(x) for x in bottleneck_string.split(',')]
except ValueError:
tf.logging.warning('Invalid float found, recreating bottleneck')
did_hit_error = True
if did_hit_error:
create_bottleneck_file(bottleneck_path, image_lists, label_name, index,
image_dir, category, sess, jpeg_data_tensor,
decoded_image_tensor, resized_input_tensor,
bottleneck_tensor)
with open(bottleneck_path, 'r') as bottleneck_file:
bottleneck_string = bottleneck_file.read()
# Allow exceptions to propagate here, since they shouldn't happen after a
# fresh creation
bottleneck_values = [float(x) for x in bottleneck_string.split(',')]
return bottleneck_values
def cache_bottlenecks(sess, image_lists, image_dir, bottleneck_dir,
jpeg_data_tensor, decoded_image_tensor,
resized_input_tensor, bottleneck_tensor, module_name):
"""Ensures all the training, testing, and validation bottlenecks are cached.
Because we're likely to read the same image multiple times (if there are no
distortions applied during training) it can speed things up a lot if we
calculate the bottleneck layer values once for each image during
preprocessing, and then just read those cached values repeatedly during
training. Here we go through all the images we've found, calculate those
values, and save them off.
Args:
sess: The current active TensorFlow Session.
image_lists: OrderedDict of training images for each label.
image_dir: Root folder string of the subfolders containing the training
images.
bottleneck_dir: Folder string holding cached files of bottleneck values.
jpeg_data_tensor: Input tensor for jpeg data from file.
decoded_image_tensor: The output of decoding and resizing the image.
resized_input_tensor: The input node of the recognition graph.
bottleneck_tensor: The penultimate output layer of the graph.
module_name: The name of the image module being used.
Returns:
Nothing.
"""
how_many_bottlenecks = 0
ensure_dir_exists(bottleneck_dir)
for label_name, label_lists in image_lists.items():
for category in ['training', 'testing', 'validation']:
category_list = label_lists[category]
for index, unused_base_name in enumerate(category_list):
get_or_create_bottleneck(
sess, image_lists, label_name, index, image_dir, category,
bottleneck_dir, jpeg_data_tensor, decoded_image_tensor,
resized_input_tensor, bottleneck_tensor, module_name)
how_many_bottlenecks += 1
if how_many_bottlenecks % 100 == 0:
tf.logging.info(
str(how_many_bottlenecks) + ' bottleneck files created.')
def get_random_cached_bottlenecks(sess, image_lists, how_many, category,
bottleneck_dir, image_dir, jpeg_data_tensor,
decoded_image_tensor, resized_input_tensor,
bottleneck_tensor, module_name):
"""Retrieves bottleneck values for cached images.
If no distortions are being applied, this function can retrieve the cached
bottleneck values directly from disk for images. It picks a random set of
images from the specified category.
Args:
sess: Current TensorFlow Session.
image_lists: OrderedDict of training images for each label.
how_many: If positive, a random sample of this size will be chosen.
If negative, all bottlenecks will be retrieved.
category: Name string of which set to pull from - training, testing, or
validation.
bottleneck_dir: Folder string holding cached files of bottleneck values.
image_dir: Root folder string of the subfolders containing the training
images.
jpeg_data_tensor: The layer to feed jpeg image data into.
decoded_image_tensor: The output of decoding and resizing the image.
resized_input_tensor: The input node of the recognition graph.
bottleneck_tensor: The bottleneck output layer of the CNN graph.
module_name: The name of the image module being used.
Returns:
List of bottleneck arrays, their corresponding ground truths, and the
relevant filenames.
"""
class_count = len(image_lists.keys())
bottlenecks = []
ground_truths = []
filenames = []
if how_many >= 0:
# Retrieve a random sample of bottlenecks.
for unused_i in range(how_many):
label_index = random.randrange(class_count)
label_name = list(image_lists.keys())[label_index]
image_index = random.randrange(MAX_NUM_IMAGES_PER_CLASS + 1)
image_name = get_image_path(image_lists, label_name, image_index,
image_dir, category)
bottleneck = get_or_create_bottleneck(
sess, image_lists, label_name, image_index, image_dir, category,
bottleneck_dir, jpeg_data_tensor, decoded_image_tensor,
resized_input_tensor, bottleneck_tensor, module_name)
bottlenecks.append(bottleneck)
ground_truths.append(label_index)
filenames.append(image_name)
else:
# Retrieve all bottlenecks.
for label_index, label_name in enumerate(image_lists.keys()):
for image_index, image_name in enumerate(
image_lists[label_name][category]):
image_name = get_image_path(image_lists, label_name, image_index,
image_dir, category)
bottleneck = get_or_create_bottleneck(
sess, image_lists, label_name, image_index, image_dir, category,
bottleneck_dir, jpeg_data_tensor, decoded_image_tensor,
resized_input_tensor, bottleneck_tensor, module_name)
bottlenecks.append(bottleneck)
ground_truths.append(label_index)
filenames.append(image_name)
return bottlenecks, ground_truths, filenames
def get_random_distorted_bottlenecks(
sess, image_lists, how_many, category, image_dir, input_jpeg_tensor,
distorted_image, resized_input_tensor, bottleneck_tensor):
"""Retrieves bottleneck values for training images, after distortions.
If we're training with distortions like crops, scales, or flips, we have to
recalculate the full model for every image, and so we can't use cached
bottleneck values. Instead we find random images for the requested category,
run them through the distortion graph, and then the full graph to get the
bottleneck results for each.
Args:
sess: Current TensorFlow Session.
image_lists: OrderedDict of training images for each label.
how_many: The integer number of bottleneck values to return.
category: Name string of which set of images to fetch - training, testing,
or validation.
image_dir: Root folder string of the subfolders containing the training
images.
input_jpeg_tensor: The input layer we feed the image data to.
distorted_image: The output node of the distortion graph.
resized_input_tensor: The input node of the recognition graph.
bottleneck_tensor: The bottleneck output layer of the CNN graph.
Returns:
List of bottleneck arrays and their corresponding ground truths.
"""
class_count = len(image_lists.keys())
bottlenecks = []
ground_truths = []
for unused_i in range(how_many):
label_index = random.randrange(class_count)
label_name = list(image_lists.keys())[label_index]
image_index = random.randrange(MAX_NUM_IMAGES_PER_CLASS + 1)
image_path = get_image_path(image_lists, label_name, image_index, image_dir,
category)
if not tf.gfile.Exists(image_path):
tf.logging.fatal('File does not exist %s', image_path)
jpeg_data = tf.gfile.FastGFile(image_path, 'rb').read()
# Note that we materialize the distorted_image_data as a numpy array before
# sending running inference on the image. This involves 2 memory copies and
# might be optimized in other implementations.
distorted_image_data = sess.run(distorted_image,
{input_jpeg_tensor: jpeg_data})
bottleneck_values = sess.run(bottleneck_tensor,
{resized_input_tensor: distorted_image_data})
bottleneck_values = np.squeeze(bottleneck_values)
bottlenecks.append(bottleneck_values)
ground_truths.append(label_index)
return bottlenecks, ground_truths
def should_distort_images(flip_left_right, random_crop, random_scale,
random_brightness):
"""是否需要对输入图片进行增强.
Args:
flip_left_right: Boolean whether to randomly mirror images horizontally.
random_crop: Integer percentage setting the total margin used around the
crop box.
random_scale: Integer percentage of how much to vary the scale by.
random_brightness: Integer range to randomly multiply the pixel values by.
Returns:
一旦有任何相关的图像增强(如左右反转,裁剪,缩放,亮度变化等),则返回真。
"""
return (flip_left_right or (random_crop != 0) or (random_scale != 0) or
(random_brightness != 0))
def add_input_distortions(flip_left_right, random_crop, random_scale,
random_brightness, module_spec):
"""Creates the operations to apply the specified distortions.
During training it can help to improve the results if we run the images
through simple distortions like crops, scales, and flips. These reflect the
kind of variations we expect in the real world, and so can help train the
model to cope with natural data more effectively. Here we take the supplied
parameters and construct a network of operations to apply them to an image.
Cropping
~~~~~~~~
Cropping is done by placing a bounding box at a random position in the full
image. The cropping parameter controls the size of that box relative to the
input image. If it's zero, then the box is the same size as the input and no
cropping is performed. If the value is 50%, then the crop box will be half the
width and height of the input. In a diagram it looks like this:
< width >
+---------------------+
| |
| width - crop% |
| < > |
| +------+ |
| | | |
| | | |
| | | |
| +------+ |
| |
| |
+---------------------+
Scaling
~~~~~~~
Scaling is a lot like cropping, except that the bounding box is always
centered and its size varies randomly within the given range. For example if
the scale percentage is zero, then the bounding box is the same size as the
input and no scaling is applied. If it's 50%, then the bounding box will be in
a random range between half the width and height and full size.
Args:
flip_left_right: Boolean whether to randomly mirror images horizontally.
random_crop: Integer percentage setting the total margin used around the
crop box.
random_scale: Integer percentage of how much to vary the scale by.
random_brightness: Integer range to randomly multiply the pixel values by.
graph.
module_spec: The hub.ModuleSpec for the image module being used.
Returns:
The jpeg input layer and the distorted result tensor.
"""
''' 得到该module期望输入图片的size和channel '''
input_height, input_width = hub.get_expected_image_size(module_spec)
input_depth = hub.get_num_image_channels(module_spec)
'''建立输入节点 '''
jpeg_data = tf.placeholder(tf.string, name='DistortJPGInput')
decoded_image = tf.image.decode_jpeg(jpeg_data, channels=input_depth)
# Convert from full range of uint8 to range [0,1] of float32.
decoded_image_as_float = tf.image.convert_image_dtype(decoded_image,
tf.float32)
decoded_image_4d = tf.expand_dims(decoded_image_as_float, 0)
margin_scale = 1.0 + (random_crop / 100.0)
resize_scale = 1.0 + (random_scale / 100.0)
margin_scale_value = tf.constant(margin_scale)
resize_scale_value = tf.random_uniform(shape=[],
minval=1.0,
maxval=resize_scale)
scale_value = tf.multiply(margin_scale_value, resize_scale_value)
precrop_width = tf.multiply(scale_value, input_width)
precrop_height = tf.multiply(scale_value, input_height)
precrop_shape = tf.stack([precrop_height, precrop_width])
precrop_shape_as_int = tf.cast(precrop_shape, dtype=tf.int32)
precropped_image = tf.image.resize_bilinear(decoded_image_4d,
precrop_shape_as_int)
precropped_image_3d = tf.squeeze(precropped_image, axis=[0])
cropped_image = tf.random_crop(precropped_image_3d,
[input_height, input_width, input_depth])
if flip_left_right:
flipped_image = tf.image.random_flip_left_right(cropped_image)
else:
flipped_image = cropped_image
brightness_min = 1.0 - (random_brightness / 100.0)
brightness_max = 1.0 + (random_brightness / 100.0)
brightness_value = tf.random_uniform(shape=[],
minval=brightness_min,
maxval=brightness_max)
brightened_image = tf.multiply(flipped_image, brightness_value)
distort_result = tf.expand_dims(brightened_image, 0, name='DistortResult')
return jpeg_data, distort_result
def variable_summaries(var):
"""Attach a lot of summaries to a Tensor (for TensorBoard visualization)."""
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var)
def add_final_retrain_ops(class_count, final_tensor_name, bottleneck_tensor,
quantize_layer, is_training):
"""增加一个新的softmax和全连接层.
The set up for the softmax and fully-connected layers is based on:
https://www.tensorflow.org/tutorials/mnist/beginners/index.html
Args:
class_count: Integer of how many categories of things we're trying to
recognize.
final_tensor_name: Name string for the new final node that produces results.
bottleneck_tensor: 此retrain中,是通过先将所有图片过一遍CNN网络,
然后将顶层的特征向量保存下来,
即所谓retrain,其实就是训练新增的这一层而已
quantize_layer: 布尔值,通过之前读取Module时,网络中是否包含特殊的ops来确定当前网络是否是通过tf.lite进行量化过的,这里确保增加的层与之前的层保持一致.
is_training: Boolean, specifying whether the newly add layer is for training
or eval.
Returns:
The tensors for the training and cross entropy results, and tensors for the
bottleneck input and ground truth input.
"""
''' 获取网络输出的bottleneck部分batch_size 和对应的维度'''
batch_size, bottleneck_tensor_size = bottleneck_tensor.get_shape().as_list()
assert batch_size is None, 'We want to work with arbitrary batch size.'
with tf.name_scope('input'):
''' 将特征提取器的bottleneck部分作为另一个小网络的输入端'''
bottleneck_input = tf.placeholder_with_default(
bottleneck_tensor,
shape=[batch_size, bottleneck_tensor_size],
name='BottleneckInputPlaceholder')
''' 建立ground truth端'''
ground_truth_input = tf.placeholder(
tf.int64, [batch_size], name='GroundTruthInput')
# Organizing the following ops so they are easier to see in TensorBoard.
layer_name = 'final_retrain_ops'
with tf.name_scope(layer_name):
# 建立连接到softmax层的权重
with tf.name_scope('weights'):
initial_value = tf.truncated_normal(
[bottleneck_tensor_size, class_count], stddev=0.001)
layer_weights = tf.Variable(initial_value, name='final_weights')
variable_summaries(layer_weights)
# 建立连接到softmax层的偏置
with tf.name_scope('biases'):
layer_biases = tf.Variable(tf.zeros([class_count]), name='final_biases')
variable_summaries(layer_biases)
# bottleneck_input*layer_weights + layer_biases
with tf.name_scope('Wx_plus_b'):
logits = tf.matmul(bottleneck_input, layer_weights) + layer_biases
tf.summary.histogram('pre_activations', logits)
# 加一个softmax函数操作
final_tensor = tf.nn.softmax(logits, name=final_tensor_name)
# The tf.contrib.quantize functions rewrite the graph in place for
# quantization. The imported model graph has already been rewritten, so upon
# calling these rewrites, only the newly added final layer will be
# transformed.
# 如果读取的不是tf.lite量化过的,则新增的层也不需要通过tf.contrib.quantize进行量化,则quantize_layer为False
if quantize_layer:
if is_training:
tf.contrib.quantize.create_training_graph()
else:
tf.contrib.quantize.create_eval_graph()
tf.summary.histogram('activations', final_tensor)
# If this is an eval graph, we don't need to add loss ops or an optimizer.
if not is_training:
return None, None, bottleneck_input, ground_truth_input, final_tensor
with tf.name_scope('cross_entropy'):
cross_entropy_mean = tf.losses.sparse_softmax_cross_entropy(
labels=ground_truth_input, logits=logits)
tf.summary.scalar('cross_entropy', cross_entropy_mean)
with tf.name_scope('train'):
optimizer = tf.train.GradientDescentOptimizer(FLAGS.learning_rate)
train_step = optimizer.minimize(cross_entropy_mean)
return (train_step, cross_entropy_mean, bottleneck_input, ground_truth_input,
final_tensor)
def add_evaluation_step(result_tensor, ground_truth_tensor):
"""Inserts the operations we need to evaluate the accuracy of our results.
Args:
result_tensor: The new final node that produces results.
ground_truth_tensor: The node we feed ground truth data
into.
Returns:
Tuple of (evaluation step, prediction).
"""
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
prediction = tf.argmax(result_tensor, 1)
correct_prediction = tf.equal(prediction, ground_truth_tensor)
with tf.name_scope('accuracy'):
evaluation_step = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', evaluation_step)
return evaluation_step, prediction
def run_final_eval(train_session, module_spec, class_count, image_lists,
jpeg_data_tensor, decoded_image_tensor,
resized_image_tensor, bottleneck_tensor):
"""基于测试集,运行一次验证操作.
Args:
train_session: Session for the train graph with the tensors below.
module_spec: The hub.ModuleSpec for the image module being used.
class_count: Number of classes
image_lists: OrderedDict of training images for each label.
jpeg_data_tensor: The layer to feed jpeg image data into.
decoded_image_tensor: The output of decoding and resizing the image.
resized_image_tensor: The input node of the recognition graph.
bottleneck_tensor: The bottleneck output layer of the CNN graph.
"""
test_bottlenecks, test_ground_truth, test_filenames = (
get_random_cached_bottlenecks(train_session, image_lists,
FLAGS.test_batch_size,
'testing', FLAGS.bottleneck_dir,
FLAGS.image_dir, jpeg_data_tensor,
decoded_image_tensor, resized_image_tensor,
bottleneck_tensor, FLAGS.tfhub_module))
(eval_session, _, bottleneck_input, ground_truth_input, evaluation_step,
prediction) = build_eval_session(module_spec, class_count)
test_accuracy, predictions = eval_session.run(
[evaluation_step, prediction],
feed_dict={
bottleneck_input: test_bottlenecks,
ground_truth_input: test_ground_truth
})
tf.logging.info('Final test accuracy = %.1f%% (N=%d)' %
(test_accuracy * 100, len(test_bottlenecks)))
if FLAGS.print_misclassified_test_images:
tf.logging.info('=== MISCLASSIFIED TEST IMAGES ===')
for i, test_filename in enumerate(test_filenames):
if predictions[i] != test_ground_truth[i]:
tf.logging.info('%70s %s' % (test_filename,
list(image_lists.keys())[predictions[i]]))
def build_eval_session(module_spec, class_count):
"""Builds an restored eval session without train operations for exporting.
Args:
module_spec: The hub.ModuleSpec for the image module being used.
class_count: Number of classes
Returns:
Eval session containing the restored eval graph.
The bottleneck input, ground truth, eval step, and prediction tensors.
"""
# If quantized, we need to create the correct eval graph for exporting.
eval_graph, bottleneck_tensor, resized_input_tensor, wants_quantization = (
create_module_graph(module_spec))
eval_sess = tf.Session(graph=eval_graph)
with eval_graph.as_default():
# Add the new layer for exporting.
(_, _, bottleneck_input,
ground_truth_input, final_tensor) = add_final_retrain_ops(
class_count, FLAGS.final_tensor_name, bottleneck_tensor,
wants_quantization, is_training=False)
# Now we need to restore the values from the training graph to the eval
# graph.
tf.train.Saver().restore(eval_sess, CHECKPOINT_NAME)
evaluation_step, prediction = add_evaluation_step(final_tensor,
ground_truth_input)
return (eval_sess, resized_input_tensor, bottleneck_input, ground_truth_input,
evaluation_step, prediction)
def save_graph_to_file(graph, graph_file_name, module_spec, class_count):
"""Saves an graph to file, creating a valid quantized one if necessary."""
sess, _, _, _, _, _ = build_eval_session(module_spec, class_count)
graph = sess.graph
output_graph_def = tf.graph_util.convert_variables_to_constants(
sess, graph.as_graph_def(), [FLAGS.final_tensor_name])
with tf.gfile.FastGFile(graph_file_name, 'wb') as f:
f.write(output_graph_def.SerializeToString())
def prepare_file_system():
# 准备summaries_dir文件夹,如果存在则先删除再建立
if tf.gfile.Exists(FLAGS.summaries_dir):
tf.gfile.DeleteRecursively(FLAGS.summaries_dir)
tf.gfile.MakeDirs(FLAGS.summaries_dir)
if FLAGS.intermediate_store_frequency > 0:
ensure_dir_exists(FLAGS.intermediate_output_graphs_dir)
return
def add_jpeg_decoding(module_spec):
"""执行JPEG解码,并进行resize.
Args:
module_spec: The hub.ModuleSpec for the image module being used.
Returns:
Tensors for the node to feed JPEG data into, and the output of the
preprocessing steps.
"""
''' 将encode成字符串的图片输入到jpeg_data节点上,
然后进行解码,进行resize,归一化等等,生成resized_image ,
简单将该函数看成是网络最开始的预处理节点 '''
input_height, input_width = hub.get_expected_image_size(module_spec)
input_depth = hub.get_num_image_channels(module_spec)
jpeg_data = tf.placeholder(tf.string, name='DecodeJPGInput')
decoded_image = tf.image.decode_jpeg(jpeg_data, channels=input_depth)
# Convert from full range of uint8 to range [0,1] of float32.
decoded_image_as_float = tf.image.convert_image_dtype(decoded_image,
tf.float32)
decoded_image_4d = tf.expand_dims(decoded_image_as_float, 0)
resize_shape = tf.stack([input_height, input_width])
resize_shape_as_int = tf.cast(resize_shape, dtype=tf.int32)
resized_image = tf.image.resize_bilinear(decoded_image_4d,
resize_shape_as_int)
return jpeg_data, resized_image
def export_model(module_spec, class_count, saved_model_dir):
"""导出模型,用于serving.
Args:
module_spec: The hub.ModuleSpec for the image module being used.
class_count: The number of classes.
saved_model_dir: Directory in which to save exported model and variables.
"""
# The SavedModel should hold the eval graph.
sess, in_image, _, _, _, _ = build_eval_session(module_spec, class_count)
graph = sess.graph
with graph.as_default():
inputs = {'image': tf.saved_model.utils.build_tensor_info(in_image)}
out_classes = sess.graph.get_tensor_by_name('final_result:0')
outputs = {
'prediction': tf.saved_model.utils.build_tensor_info(out_classes)
}
signature = tf.saved_model.signature_def_utils.build_signature_def(
inputs=inputs,
outputs=outputs,
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME)
legacy_init_op = tf.group(tf.tables_initializer(), name='legacy_init_op')
# Save out the SavedModel.
builder = tf.saved_model.builder.SavedModelBuilder(saved_model_dir)
builder.add_meta_graph_and_variables(
sess, [tf.saved_model.tag_constants.SERVING],
signature_def_map={
tf.saved_model.signature_constants.
DEFAULT_SERVING_SIGNATURE_DEF_KEY:
signature
},
legacy_init_op=legacy_init_op)
builder.save()
def main(_):
# 先确定日志输出是正常的
# See https://github.com/tensorflow/tensorflow/issues/3047
tf.logging.set_verbosity(tf.logging.INFO)
if not FLAGS.image_dir:
tf.logging.error('Must set flag --image_dir.')
return -1
# 准备训练过程中保存中间值,结果值等必要的文件夹:如果检测到存在,则删除,再创建空的
prepare_file_system()
# 通过预先定义的训练集文件夹结构,进行类别读取等操作
image_lists = create_image_lists(FLAGS.image_dir, FLAGS.testing_percentage,
FLAGS.validation_percentage)
class_count = len(image_lists.keys())
if class_count == 0:
tf.logging.error('No valid folders of images found at ' + FLAGS.image_dir)
return -1
if class_count == 1:
tf.logging.error('Only one valid folder of images found at ' +
FLAGS.image_dir +
' - multiple classes are needed for classification.')
return -1
# 通过读取命令行的参数,确定是否需要启用图像增强,这是一个bool值
do_distort_images = should_distort_images(
FLAGS.flip_left_right, FLAGS.random_crop, FLAGS.random_scale,
FLAGS.random_brightness)
# 1 - 建立预训练的模块
'''hub.Module(spec)中如果spec是str(url,或者path),内部也是通过hub.load_module_spec进行读取的 '''
module_spec = hub.load_module_spec(FLAGS.tfhub_module)
graph, bottleneck_tensor, resized_image_tensor, wants_quantization = (
create_module_graph(module_spec))
# 2 - 基于上述module恢复的graph基础上,增加需要retrain的层,即最后一层
with graph.as_default():
(train_step, cross_entropy, bottleneck_input,
ground_truth_input, final_tensor) = add_final_retrain_ops(
class_count, FLAGS.final_tensor_name, bottleneck_tensor,
wants_quantization, is_training=True)
with tf.Session(graph=graph) as sess:
# 新的graph已经完全建立,按照逻辑,就是先初始化
# 初始化所有权重:将预训练的网络中的权重赋值到网络上;
# 对新增的层,进行随机初始化
init = tf.global_variables_initializer()
sess.run(init)
''' 3 - 建立2条分支,1条对应非图像增强的;另一条对应图像增强的;
因为图像增强是基于数据集进行多种策略的增强,需要在线计算得出;
而非图像增强的,因当前是retrain任务,所以可以直接将特征提取到的bottleneck存储在磁盘上 '''
# 在模型的最前面增加数据输入的部分:
# 建立一个sub-graph, 该sub-graph接收encode成字符串的图片(graph的输入),输出tf格式的图片.将图片扩展成tf的4d张量
jpeg_data_tensor, decoded_image_tensor = add_jpeg_decoding(module_spec)
# 如果需要输入的图片进行增强,则新增一个op,这里的add_input_distortions与add_jpeg_decoding是对立操作
if do_distort_images:
# 如add_jpeg_decoding 一样,是将encode成字符串的图片(graph的输入),进行解码,然后相比增加了一些图像增强的方法,输出成4d的tf格式
(distorted_jpeg_data_tensor,
distorted_image_tensor) = add_input_distortions(
FLAGS.flip_left_right, FLAGS.random_crop, FLAGS.random_scale,
FLAGS.random_brightness, module_spec)
else:
# 计算图像的bottleneck,即图像的特征向量,然后将其缓存到磁盘上.
cache_bottlenecks(sess, image_lists, FLAGS.image_dir,
FLAGS.bottleneck_dir, jpeg_data_tensor,
decoded_image_tensor, resized_image_tensor,
bottleneck_tensor, FLAGS.tfhub_module)
# 基于新增层基础上进行训练结果的准确度评估.
evaluation_step, _ = add_evaluation_step(final_tensor, ground_truth_input)
# 将所有需要打印的辅助信息进行融合,并将其写入到summaries_dir中,以供tensorboard展示
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(FLAGS.summaries_dir + '/train',
sess.graph)
validation_writer = tf.summary.FileWriter(
FLAGS.summaries_dir + '/validation')
# 创建一个train saver用于存储变量的值(即权重)到一个checkpoint文件.
train_saver = tf.train.Saver()
''' 4 - 用户给定的steps值作为训练的次数. '''
for i in range(FLAGS.how_many_training_steps):
''' 4.1 准备读取输入数据 '''
# 基于采用的输入图像增强策略,计算输入图像的bottleneck值(即2048维度的特征向量);
# 或者是读取以及存放在磁盘上的图像的bottleneck值.
if do_distort_images:
(train_bottlenecks,
train_ground_truth) = get_random_distorted_bottlenecks(
sess, image_lists, FLAGS.train_batch_size, 'training',
FLAGS.image_dir, distorted_jpeg_data_tensor,
distorted_image_tensor, resized_image_tensor, bottleneck_tensor)
else:
(train_bottlenecks,
train_ground_truth, _) = get_random_cached_bottlenecks(
sess, image_lists, FLAGS.train_batch_size, 'training',
FLAGS.bottleneck_dir, FLAGS.image_dir, jpeg_data_tensor,
decoded_image_tensor, resized_image_tensor, bottleneck_tensor,
FLAGS.tfhub_module)
''' 4.2 喂数据,并迭代训练模型 '''
# 将bottlenecks值和图像的ground truth 输入到graph中,
# 然后通过run一个merged节点操作,进行training阶段的信息收集
train_summary, _ = sess.run(
[merged, train_step],
feed_dict={bottleneck_input: train_bottlenecks,
ground_truth_input: train_ground_truth})
train_writer.add_summary(train_summary, i)
# 打印出该graph的训练过程.
is_last_step = (i + 1 == FLAGS.how_many_training_steps)
if (i % FLAGS.eval_step_interval) == 0 or is_last_step:
train_accuracy, cross_entropy_value = sess.run(
[evaluation_step, cross_entropy],
feed_dict={bottleneck_input: train_bottlenecks,
ground_truth_input: train_ground_truth})
tf.logging.info('%s: Step %d: Train accuracy = %.1f%%' %
(datetime.now(), i, train_accuracy * 100))
tf.logging.info('%s: Step %d: Cross entropy = %f' %
(datetime.now(), i, cross_entropy_value))
# TODO: Make this use an eval graph, to avoid quantization
# moving averages being updated by the validation set, though in
# practice this makes a negligable difference.
validation_bottlenecks, validation_ground_truth, _ = (
get_random_cached_bottlenecks(
sess, image_lists, FLAGS.validation_batch_size, 'validation',
FLAGS.bottleneck_dir, FLAGS.image_dir, jpeg_data_tensor,
decoded_image_tensor, resized_image_tensor, bottleneck_tensor,
FLAGS.tfhub_module))
# 运行一次验证操作,并如训练阶段一样,通过merged节点操作获取其中的信息,以供tensorboard展示.
validation_summary, validation_accuracy = sess.run(
[merged, evaluation_step],
feed_dict={bottleneck_input: validation_bottlenecks,
ground_truth_input: validation_ground_truth})
validation_writer.add_summary(validation_summary, i)
tf.logging.info('%s: Step %d: Validation accuracy = %.1f%% (N=%d)' %
(datetime.now(), i, validation_accuracy * 100,
len(validation_bottlenecks)))
''' 5 - 存储中间结果的频率 '''
intermediate_frequency = FLAGS.intermediate_store_frequency
if (intermediate_frequency > 0 and (i % intermediate_frequency == 0)
and i > 0):
''' 5.1 将train的中间值存入一个checkpoint中 '''
train_saver.save(sess, CHECKPOINT_NAME)
intermediate_file_name = (FLAGS.intermediate_output_graphs_dir +
'intermediate_' + str(i) + '.pb')
tf.logging.info('Save intermediate result to : ' +
intermediate_file_name)
''' 5.2 将图存入一个pb文件中 '''
save_graph_to_file(graph, intermediate_file_name, module_spec,
class_count)
# 训练完成时,将最后一次训练结果再存入到checkpoint中.
train_saver.save(sess, CHECKPOINT_NAME)
# 在结束训练的时候,基于测试集,运行一次测试过程.
run_final_eval(sess, module_spec, class_count, image_lists,
jpeg_data_tensor, decoded_image_tensor, resized_image_tensor,
bottleneck_tensor)
''' 5.3 将训练好的graph和labels以及weights转化为常量. '''
tf.logging.info('Save final result to : ' + FLAGS.output_graph)
if wants_quantization:
tf.logging.info('The model is instrumented for quantization with TF-Lite')
# 将图存入到pb中
save_graph_to_file(graph, FLAGS.output_graph, module_spec, class_count)
with tf.gfile.FastGFile(FLAGS.output_labels, 'w') as f:
f.write('\n'.join(image_lists.keys()) + '\n')
''' 6 - 基于是否需要提供tensorflow serving,进行导出graph到saved_model文件夹中 '''
if FLAGS.saved_model_dir:
export_model(module_spec, class_count, FLAGS.saved_model_dir)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'--image_dir',
type=str,
default='',
help='Path to folders of labeled images.'
)
parser.add_argument(
'--output_graph',
type=str,
default='/tmp/output_graph.pb',
help='Where to save the trained graph.'
)
parser.add_argument(
'--intermediate_output_graphs_dir',
type=str,
default='/tmp/intermediate_graph/',
help='Where to save the intermediate graphs.'
)
parser.add_argument(
'--intermediate_store_frequency',
type=int,
default=0,
help="""\
How many steps to store intermediate graph. If "0" then will not
store.\
"""
)
parser.add_argument(
'--output_labels',
type=str,
default='/tmp/output_labels.txt',
help='Where to save the trained graph\'s labels.'
)
parser.add_argument(
'--summaries_dir',
type=str,
default='/tmp/retrain_logs',
help='Where to save summary logs for TensorBoard.'
)
parser.add_argument(
'--how_many_training_steps',
type=int,
default=4000,
help='How many training steps to run before ending.'
)
parser.add_argument(
'--learning_rate',
type=float,
default=0.01,
help='How large a learning rate to use when training.'
)
parser.add_argument(
'--testing_percentage',
type=int,
default=10,
help='What percentage of images to use as a test set.'
)
parser.add_argument(
'--validation_percentage',
type=int,
default=10,
help='What percentage of images to use as a validation set.'
)
parser.add_argument(
'--eval_step_interval',
type=int,
default=10,
help='How often to evaluate the training results.'
)
parser.add_argument(
'--train_batch_size',
type=int,
default=100,
help='How many images to train on at a time.'
)
parser.add_argument(
'--test_batch_size',
type=int,
default=-1,
help="""\
How many images to test on. This test set is only used once, to evaluate
the final accuracy of the model after training completes.
A value of -1 causes the entire test set to be used, which leads to more
stable results across runs.\
"""
)
parser.add_argument(
'--validation_batch_size',
type=int,
default=100,
help="""\
How many images to use in an evaluation batch. This validation set is
used much more often than the test set, and is an early indicator of how
accurate the model is during training.
A value of -1 causes the entire validation set to be used, which leads to
more stable results across training iterations, but may be slower on large
training sets.\
"""
)
parser.add_argument(
'--print_misclassified_test_images',
default=False,
help="""\
Whether to print out a list of all misclassified test images.\
""",
action='store_true'
)
parser.add_argument(
'--bottleneck_dir',
type=str,
default='/tmp/bottleneck',
help='Path to cache bottleneck layer values as files.'
)
parser.add_argument(
'--final_tensor_name',
type=str,
default='final_result',
help="""\
The name of the output classification layer in the retrained graph.\
"""
)
parser.add_argument(
'--flip_left_right',
default=False,
help="""\
Whether to randomly flip half of the training images horizontally.\
""",
action='store_true'
)
parser.add_argument(
'--random_crop',
type=int,
default=0,
help="""\
A percentage determining how much of a margin to randomly crop off the
training images.\
"""
)
parser.add_argument(
'--random_scale',
type=int,
default=0,
help="""\
A percentage determining how much to randomly scale up the size of the
training images by.\
"""
)
parser.add_argument(
'--random_brightness',
type=int,
default=0,
help="""\
A percentage determining how much to randomly multiply the training image
input pixels up or down by.\
"""
)
parser.add_argument(
'--tfhub_module',
type=str,
default=(
'https://tfhub.dev/google/imagenet/inception_v3/feature_vector/1'),
help="""\
Which TensorFlow Hub module to use.
See https://github.com/tensorflow/hub/blob/master/docs/modules/image.md
for some publicly available ones.\
""")
parser.add_argument(
'--saved_model_dir',
type=str,
default='',
help='Where to save the exported graph.')
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
Tensorflow-hub[例子解析1]的更多相关文章
- Tensorflow-hub[例子解析2]
接Tensorflow-hub[例子解析1]. 3 基于文本词向量的例子 3.1 创建Module 可以从Tensorflow-hub[例子解析1].中看出,hub相对之前减少了更多的工作量. 首先, ...
- Poco库网络模块例子解析1-------字典查询
Poco的网络模块在Poco::Net名字空间下定义 下面是字典例子解析 #include "Poco/Net/StreamSocket.h" //流式套接字 #include ...
- 如何使用TensorFlow Hub和代码示例
任何深度学习框架,为了获得成功,必须提供一系列最先进的模型,以及在流行和广泛接受的数据集上训练的权重,即与训练模型. TensorFlow现在已经提出了一个更好的框架,称为TensorFlow Hub ...
- Java字节码例子解析
举个简单的例子: public class Hello { public static void main(String[] args) { String string1 = ...
- Tensorflow之MNIST解析
要说2017年什么技术最火爆,无疑是google领衔的深度学习开源框架Tensorflow.本文简述一下深度学习的入门例子MNIST. 深度学习简单介绍 首先要简单区别几个概念:人工智能,机器学习,深 ...
- tensorflow源码解析之distributed_runtime
本篇主要介绍TF的分布式运行时的基本概念.为了对TF的分布式运行机制有一个大致的了解,我们先结合/tensorflow/core/protobuf中的文件给出对TF分布式集群的初步理解,然后介绍/te ...
- Poco C++库网络模块例子解析2-------HttpServer
//下面程序取自 Poco 库的Net模块例子----HTTPServer 下面开始解析代码 #include "Poco/Net/HTTPServer.h" //继承自TCPSe ...
- Tensorflow ActiveFunction激活函数解析
Active Function 激活函数 原创文章,请勿转载哦~!! 觉得有用的话,欢迎一起讨论相互学习~Follow Me Tensorflow提供了多种激活函数,在CNN中,人们主要是用tf.nn ...
- tensorflow finuetuning 例子
最近研究了下如何使用tensorflow进行finetuning,相比于caffe,tensorflow的finetuning麻烦一些,记录如下: 1.原理 finetuning原理很简单,利用一个在 ...
随机推荐
- vue-cli脚手架之webpack.prod.conf.js
webpack.prod.conf.js 生产环境配置文件: 'use strict'//js严格模式执行 const path = require('path')//这个模块是发布到NPM注册中心的 ...
- docker-使用Dockerfile制作镜像
最近项目中有使用docker,组内做了关于docker的培训,然后自己跟着研究了一下,大概了解如何使用.我是基于tomcat镜像制作(不需要安装jdk,配置环境变量),基于centos镜像制作需要安装 ...
- Android Studio列表用法之一:ListView图文列表显示(实例)
前言: ListView这个列表控件在Android中是最常用的控件之一,几乎在所有的应用程序中都会使用到它. 目前正在做的一个记账本APP中就用到了它,主要是用它来呈现收支明细,是一个图文列表的呈现 ...
- Linux下内存查看命令
在Linux下面,我们常用top命令来查看系统进程,top也能显示系统内存.我们常用的Linux下查看内容的专用工具是free命令. Linux下内存查看命令free详解: 在Linux下查看内存我们 ...
- 【转】handbrake使用教程
原文地址http://tieba.baidu.com/p/2399590151?pn=1 现在的很多压制教程基本都是使用megui或者mediacoder的,这两个软件使 ...
- Python3编写网络爬虫05-基本解析库XPath的使用
一.XPath 全称 XML Path Language 是一门在XML文档中 查找信息的语言 最初是用来搜寻XML文档的 但是它同样适用于HTML文档的搜索 XPath 的选择功能十分强大,它提供了 ...
- CSS Hack的一些知识
测试环境:Windows7 主要测试:IE6.IE7.IE8.Fire Fox3.5.6 次要测试:Chrome4.0.Opera10.10.Safari4.04.360浏览器3.1 为了能够让多个H ...
- 【转】URL编码(encodeURIComponent和decodeURIComponent)
转自http://blog.jhonse.com/archives/2032.jhonse 最近在用CI框架的时候,发现一个问题,URL的GET方式链接时,如果用中文字符的话,就会出现问题,提示:链接 ...
- 使用POI读写word docx文件
目录 1 读docx文件 1.1 通过XWPFWordExtractor读 1.2 通过XWPFDocument读 2 写docx文件 2.1 直接通过XWPF ...
- Axure RP Pro7.0的key注册码加汉化非破解
上次我们刚分享过Axure RP Pro6.5 key注册码加汉化非破解,我还要分享一个Axure RP Pro7.0的key注册码加汉化,非破解哦. 当然方法还是不变,先用下面的密钥激活.用户名就是 ...