【Spark-SQL学习之一】 SparkSQL
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
一、Shark
Shark是基于Spark计算框架之上且兼容Hive语法的SQL执行引擎,由于底层的计算采用了Spark,性能比MapReduce的Hive普遍快2倍以上,当数据全部load在内存的话,将快10倍以上,因此Shark可以作为交互式查询应用服务来使用。除了基于Spark的特性外,Shark是完全兼容Hive的语法,表结构以及UDF函数等,已有的HiveSql可以直接进行迁移至Shark上Shark底层依赖于Hive的解析器,查询优化器,但正是由于SHark的整体设计架构对Hive的依赖性太强,难以支持其长远发展,比如不能和Spark的其他组件进行很好的集成,无法满足Spark的一栈式解决大数据处理的需求。
二、SparkSQL
1、SparkSQL介绍
Hive是Shark的前身,Shark是SparkSQL的前身。
(1)SparkSQL产生的根本原因是其完全脱离了Hive的限制。
(2)SparkSQL支持查询原生的RDD,RDD是Spark平台的核心概念,是Spark能够高效的处理大数据的各种场景的基础。
(3)能够在Scala中写SQL语句,支持简单的SQL语法检查,能够在Scala中写Hive语句访问Hive数据,并将结果取回作为RDD使用。
2、Spark on Hive和Hive on Spark
Spark on Hive: Hive只作为储存角色,Spark负责sql解析优化,执行。
Hive on Spark:Hive即作为存储又负责sql的解析优化,Spark负责执行。
3、DataFrame(SparkSQL的最佳搭档)
DataFrame也是一个分布式数据容器。
与RDD类似,然而DataFrame更像传统数据库的二维表格,除了数据以外,还掌握数据的结构信息,即schema。
同时与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。
从API易用性的角度上看, DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。
DataFrame的底层封装的是RDD,只不过RDD的泛型是Row类型。
4. SparkSQL的数据源
SparkSQL的数据源可以是JSON类型的字符串,也可以是JDBC,Parquent,Hive,HDFS等。

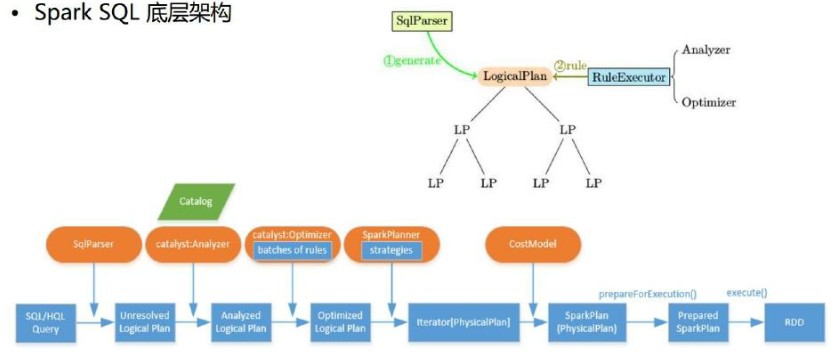
5. SparkSQL底层架构
首先拿到sql后解析一批未被解决的逻辑计划,
-->再经过分析得到分析后的逻辑计划,
-->再经过一批优化规则转换成一批最佳优化的逻辑计划,
-->再经过SparkPlanner的策略转化成一批物理计划,
-->随后经过消费模型转换成一个个的Spark任务执行。
6. 谓词下推(predicate Pushdown)

参考:
【Spark-SQL学习之一】 SparkSQL的更多相关文章
- spark SQL学习(综合案例-日志分析)
日志分析 scala> import org.apache.spark.sql.types._ scala> import org.apache.spark.sql.Row scala&g ...
- spark SQL学习(认识spark SQL)
spark SQL初步认识 spark SQL是spark的一个模块,主要用于进行结构化数据的处理.它提供的最核心的编程抽象就是DataFrame. DataFrame:它可以根据很多源进行构建,包括 ...
- spark SQL学习(案例-统计每日销售)
需求:统计每日销售额 package wujiadong_sparkSQL import org.apache.spark.sql.types._ import org.apache.spark.sq ...
- spark SQL学习(案例-统计每日uv)
需求:统计每日uv package wujiadong_sparkSQL import org.apache.spark.sql.{Row, SQLContext} import org.apache ...
- spark SQL学习(spark连接 mysql)
spark连接mysql(打jar包方式) package wujiadong_sparkSQL import java.util.Properties import org.apache.spark ...
- spark SQL学习(spark连接hive)
spark 读取hive中的数据 scala> import org.apache.spark.sql.hive.HiveContext import org.apache.spark.sql. ...
- spark SQL学习(数据源之json)
准备工作 数据文件students.json {"id":1, "name":"leo", "age":18} {&qu ...
- spark SQL学习(数据源之parquet)
Parquet是面向分析型业务得列式存储格式 编程方式加载数据 代码示例 package wujiadong_sparkSQL import org.apache.spark.sql.SQLConte ...
- spark SQL学习(load和save操作)
load操作:主要用于加载数据,创建出DataFrame save操作:主要用于将DataFrame中的数据保存到文件中 代码示例(默认为parquet数据源类型) package wujiadong ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
随机推荐
- 视频编码---mjpeg
http://www.eepw.com.cn/article/201612/333063.htm https://www.cnblogs.com/ikaka/p/4860858.html https: ...
- Gephi学习笔记
使用gephi对图数据进行可视化操作,下面网址是gephi的说明文档 https://seinecle.github.io/gephi-tutorials/generated-pdf/semantic ...
- linux 安装svn客户端
安装命令:yum install -y subversion 客户端使用命令: svn help 帮助命令 svn checkout --help 子帮助命令
- Linux下常见命令
=============挂载和登陆命令======================================== Mount:挂载命令. 比方挂载光驱mount /dev/cdrom /mnt ...
- python 检测字符串编码类型是什么
for index,value in enumerate(listvalue): adchar=chardet.detect(value) print adchar if adchar['encodi ...
- iOS - User Agent 的应用和设置
UA在项目中的应用 给项目的webview或项目中的接口请求加一个区分,用来区别是iOS端访问.android访问还是在浏览器访问的,这时需要添加User Agent (http请求 header中的 ...
- C#队列Queue实现一个简单的电商网站秒杀程序
电商的秒杀和抢购,对程序员来说,都不是一个陌生的东西.然而,从技术的角度来说,这对于Web系统是一个巨大的考验.当一个Web系统,在一秒钟内收到数以万计甚至更多请求时,系统的优化和稳定至关重要. 我们 ...
- Hadoop 跨集群访问
[原文地址] 跨集群访问 发表于 2015-06-01 | 简单总结下跨集群访问的多种方式. 跨集群访问HDFS 直接给出HDFS URI 我们平常执行hadoop fs -ls /之类的操作 ...
- python使用matplotlib绘制折线图教程
Matplotlib是一个Python工具箱,用于科学计算的数据可视化.借助它,Python可以绘制如Matlab和Octave多种多样的数据图形.下面这篇文章主要介绍了python使用matplot ...
- Ubuntu 16.04 Java8 安装
添加ppa apt-get update apt install software-properties-common add-apt-repository ppa:webupd8team/java ...