Python自然语言处理笔记【一】文本分类之监督式分类
一、分类问题
分类是为了给那些已经给定的输入选择正确的标签。
在基本的分类任务中,每个输入都被认为与其他的输入是隔离的。每个类别的标签集是预先定义好的(只有把类别划分好了,才能给输入划分类别)。
分类任务举例:
- 判断电子是否是垃圾邮件
- 从一个固定的主题领域列表里,比如有‘体育’、‘技术’、‘政治’等,来判断新闻报道的主题
- 判断给定词‘bank’的意思是指河的坡岸、金融机构、还是金融机构里的存储行为
基本分类任务:
- 多样分类:每个实例可以分配多个标签
- 开放性分类:标签集没有事先定义
- 序列分类:输入链表作为整体分类
建立在训练语料(包含了每个输入的正确标签)基础之上的分类,叫做监督式分类。
二、监督式分类
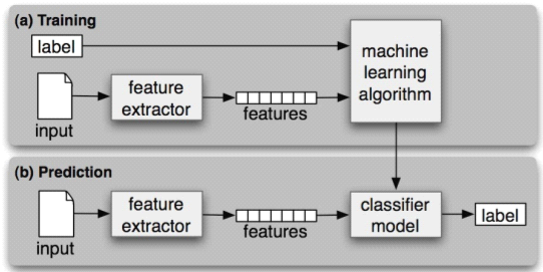
( a )在训练过程(Training)中,特征提取器(feature extractor)用来将每一个输入值(input)转换为特征集(features)。 这些特征集捕捉每个输入中应被用于对其分类的基本信息 。特征 集与标签(label)的配对被送入机器学习算法(machine learning algorithm) ,生成模型(classifier model) 。
( b )在预测过程(Prediction)中 ,相同的特征提取器被用来将未见过的输入转换为特征集。之后,这些特征集被送入模型产生预测标签。
三、分类实例(创建一个分类器)——性别鉴定
step1:决定哪些输入特征是相关的,并为这些特征编码。书中例子是通过判断名字最后一个字母,来推测性别,所以特征就在最后一个字母上。
>>> def gender_features(word):
... return {'last_letter': word[-1]}
>>> gender_features('Shrek')
{'last_letter': 'k'}
step2:利用特征提取器函数建立特征集(字典类型,关于特征名称和它们对应值的映射)
>>> from nltk.corpus import names
>>> import random
>>> names = ([(name, 'male') for name in names.words('male.txt')] +
... [(name, 'female') for name in names.words('female.txt')])
>>> random.shuffle(names)
step3:用特征提取器处理数据(文中用的是names数据),并把特征集的结果链表,划分为训练集和测试集。(训练集用于训练新的朴素贝叶斯分类器)
>>> featuresets = [(gender_features(n), g) for (n,g) in names]
>>> train_set, test_set = featuresets[500:], featuresets[:500]
>>> classifier = nltk.NaiveBayesClassifier.train(train_set)
step4:测试,检查
#利用大量未见过的数据来评估这个分类器
>>> print nltk.classify.accuracy(classifier, test_set)
#检查分类器,确定哪些特征对于区分名字的性别是最有效的。
>>> classifier.show_most_informative_features(5)
Python自然语言处理笔记【一】文本分类之监督式分类的更多相关文章
- Python自然语言处理笔记【二】文本分类之监督式分类的细节问题
一.选择正确的特征 1.建立分类器的工作中如何选择相关特征,并且为其编码来表示这些特征是首要问题. 2.特征提取,要避免过拟合或者欠拟合 过拟合,是提供的特征太多,使得算法高度依赖训练数据的特性,而对 ...
- Python 自然语言处理笔记(一)
一. NLTK的几个常用函数 1. Concordance 实例如下: >>> text1.concordance("monstrous") Displaying ...
- 《Python自然语言处理》
<Python自然语言处理> 基本信息 作者: (美)Steven Bird Ewan Klein Edward Loper 出版社:人民邮电出版社 ISBN:97871153 ...
- Python 1行代码实现文本分类(实战笔记),含代码详细说明及运行结果
Python 1行代码实现文本分类(实战笔记),含代码详细说明及运行结果 一.详细说明及代码 tc.py =============================================== ...
- python自然语言处理学习笔记1
1.搭建环境 下载anaconda并安装,(其自带python2.7和一些常用包,NumPy,Matplotlib),第一次启动使用spyder 2.下载nltk import nltk nltk.d ...
- Python自然语言处理工具小结
Python自然语言处理工具小结 作者:白宁超 2016年11月21日21:45:26 目录 [Python NLP]干货!详述Python NLTK下如何使用stanford NLP工具包(1) [ ...
- python核心编程--笔记
python核心编程--笔记 的解释器options: 1.1 –d 提供调试输出 1.2 –O 生成优化的字节码(生成.pyo文件) 1.3 –S 不导入site模块以在启动时查找pyt ...
- Python人工智能学习笔记
Python教程 Python 教程 Python 简介 Python 环境搭建 Python 中文编码 Python 基础语法 Python 变量类型 Python 运算符 Python 条件语句 ...
- 转-Python自然语言处理入门
Python自然语言处理入门 原文链接:http://python.jobbole.com/85094/ 分享到:20 本文由 伯乐在线 - Ree Ray 翻译,renlytime 校稿.未经许 ...
随机推荐
- React Native Android原生模块开发实战|教程|心得|怎样创建React Native Android原生模块
尊重版权,未经授权不得转载 本文出自:贾鹏辉的技术博客(http://blog.csdn.net/fengyuzhengfan/article/details/54691503) 告诉大家一个好消息. ...
- iOS - 记住用户登录状态保存用户名密码
我们在使用APP时常用的一个功能:用户第一次进入APP时自动进入登录注册页,提示用户注册登录,用户登录成功后才进入主页,再次进入APP时,不用再次登录就直接进到主页了,就算杀掉该APP进程再次进入,依 ...
- E - Heavy Transportation
来源poj1797 Background Hugo Heavy is happy. After the breakdown of the Cargolifter project he can now ...
- 最短路问题(Bellman/Dijkstra/Floyd)
最短路问题(Bellman/Dijkstra/Floyd) 寒假了,继续学习停滞了许久的算法.接着从图论开始看起,之前觉得超级难的最短路问题,经过两天的苦读,终于算是有所收获.把自己的理解记录下来,可 ...
- js中 函数声明/函数表达式/匿名函数/箭头函数/立即执行函数
函数声明: function add(a, b) { // ... } 1.顾名思义,声明一个函数, 用关键字 “function” 来告诉,这是一个函数. 2.任何地方,想用就可以拿过来使用 函数表 ...
- Mysql 数据库开发规范
设计范式参看,DDL与DDL 库表基础规范 1.注释 每个表要添加注释,对 status 型需指明主要值的含义,如”0-离线,1-在线” 2.表的字段数量 单表字段数一般考虑上限为 30左右,再多的话 ...
- 网页分帧操作<frameset>,<iframe>标签
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding= ...
- css的position,float属性的理解
我们知道,html是按照普通流来加载的,这个时候我们有些需求就不好实现.因此出现了非普通流: 1.普通流:按照顺序正常的排列,长度或不够就往下挤.position默认的static 2.非普通流:脱离 ...
- python语法_字符串拼接
+号可以用来做字符串拼接 print("abc"+"efg"+"def") abcefgdef 字符串(str)与数字(int)不能使用+进 ...
- Ubuntu 14.04循环登录问题(密码正确,无法登录)
今天遇到了ubuntu 的循环登录问题,即使输入的密码是正确的,也无法成功登录.查询资料,发现有各种问题引起的循环登录问题,比如安装了jdk,或者安装了驱动. 最后找到了问题的原由:我的电脑是双显卡, ...