GridSearchCV交叉验证
代码实现(基于逻辑回归算法):
# -*- coding: utf-8 -*-
"""
Created on Sat Sep 1 11:54:48 2018 @author: zhen 交叉验证
"""
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt iris = datasets.load_iris()
x = iris['data'][:, 3:]
y = iris['target'] def report(results, n_top=3):
for i in range(1, n_top + 1):
candidates = np.flatnonzero(results['rank_test_score'] == i)
for candidate in candidates:
print("Model with rank: {0}".format(i))
print("Mean validation score: {0:.3f} (std: {1:.3f})".format(
results['mean_test_score'][candidate],
results['std_test_score'][candidate]))
print("Parameters: {0}".format(results['params'][candidate]))
print("") param_grid = {"tol":[1e-4, 1e-3,1e-2], "C":[0.4, 0.6, 0.8]} log_reg = LogisticRegression(multi_class='ovr', solver='sag')
# 采用3折交叉验证
grid_search = GridSearchCV(log_reg, param_grid=param_grid, cv=3)
grid_search.fit(x, y) report(grid_search.cv_results_) x_new = np.linspace(0, 3, 1000).reshape(-1, 1)
y_proba = grid_search.predict_proba(x_new)
y_hat = grid_search.predict(x_new) plt.plot(x_new, y_proba[:, 2], 'g-', label='Iris-Virginica')
plt.plot(x_new, y_proba[:, 1], 'r-', label='Iris-Versicolour')
plt.plot(x_new, y_proba[:, 0], 'b-', label='Iris-Setosa')
plt.show() print(grid_search.predict([[1.7], [1.5]]))
结果:
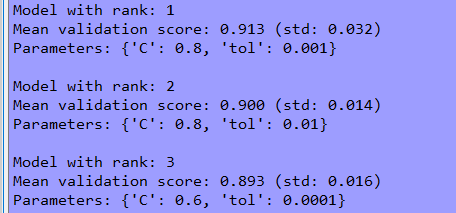
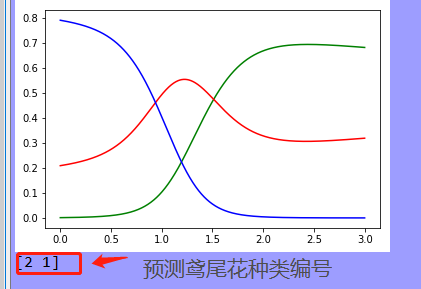
总结:使用交叉验证可以实现代码自动对设定范围参数的模型进行分别训练,最后选出效果最好的参数所训练出的模型进行预测,以求达到最好的预测效果!
GridSearchCV交叉验证的更多相关文章
- 机器学习——交叉验证,GridSearchCV,岭回归
0.交叉验证 交叉验证的基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set) ...
- 支持向量机(SVM)利用网格搜索和交叉验证进行参数选择
上一回有个读者问我:回归模型与分类模型的区别在哪?有什么不同,我在这里给他回答一下 : : : : 回归问题通常是用来预测一个值,如预测房价.未来的天气情况等等,例如一个产品的实际价格为500元,通过 ...
- 什么是机器学习的分类算法?【K-近邻算法(KNN)、交叉验证、朴素贝叶斯算法、决策树、随机森林】
1.K-近邻算法(KNN) 1.1 定义 (KNN,K-NearestNeighbor) 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类 ...
- 多项式回归 & pipeline & 学习曲线 & 交叉验证
多项式回归就是数据的分布不满足线性关系,而是二次曲线或者更高维度的曲线.此时只能使用多项式回归来拟合曲线.比如如下数据,使用线性函数来拟合就明显不合适了. 接下来要做的就是升维,上面的真实函数是:$ ...
- MATLAB曲面插值及交叉验证
在离散数据的基础上补插连续函数,使得这条连续曲线通过全部给定的离散数据点.插值是离散函数逼近的重要方法,利用它可通过函数在有限个点处的取值状况,估算出函数在其他点处的近似值.曲面插值是对三维数据进行离 ...
- 交叉验证(Cross Validation)原理小结
交叉验证是在机器学习建立模型和验证模型参数时常用的办法.交叉验证,顾名思义,就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏. ...
- scikit-learn一般实例之一:绘制交叉验证预测
本实例展示怎样使用cross_val_predict来可视化预测错误: # coding:utf-8 from pylab import * from sklearn import datasets ...
- oracle ebs应用产品安全性-交叉验证规则
转自: http://blog.itpub.net/298600/viewspace-625138/ 定义: Oracle键弹性域可以根据自定义键弹性域时所定义的规则,执行段值组合的自动交叉验证.使用 ...
- SVM学习笔记(二):什么是交叉验证
交叉验证:拟合的好,同时预测也要准确 我们以K折交叉验证(k-folded cross validation)来说明它的具体步骤.{A1,A2,A3,A4,A5,A6,A7,A8,A9} 为了简化,取 ...
随机推荐
- Liferay7 BPM门户开发之8: Activiti实用问题集合
1.如何实现审核的上级获取(任务逐级审批) 这个是必备功能,通过Spring的注入+Activiti表达式可以很容易解决. 可参考: http://blog.csdn.net/sunxing007/a ...
- POJ 2895
#include <iostream> #include <string> #define MAXN 27 using namespace std; short map[MAX ...
- BF算法(模式匹配)
BF算法 (Brute-Force算法) 一种简单的模式匹配算法,目的是寻找模式串p是否在目标串s中有出现. 思想:先从第一个字符开始匹配,如果p[j]==s[i],那么继续向下比较,一旦不相等,即回 ...
- UNPIVOT
UNPIVOT UNPIVOT则相反,把数据从列旋转到行 SELECT * INTO product_vlues FROM ( SELECT NAME , ...
- SSM整合(四)-整合后配置文件汇总
1.新建Maven项目创建pom.xml pom.xml内容如下 <project xmlns="http://maven.apache.org/POM/4.0.0" xml ...
- 私服仓库 nexus 环境搭建(win10)
1.1 简介: Nexus 是Maven仓库管理器,如果你使用Maven,你可以从Maven中央仓库 下载所需要的构件(artifact),但这通常不是一个好的做法,你应该在本地架设一个Maven仓库 ...
- 出现 The processing instruction target matching "[xX][mM][lL]" is not allowed错误
错误原因与解决办法: 这个错误的原因是因为xml的开始有多余的空格造成的,只要把多余的空格删除就没有问题了. xml开始部分写注释也会出现此问题. 本文出自:艺意
- 以ActiveMQ为例JAVA消息中间件学习【3】——SpringBoot中使用ActiveMQ
前言 首先我们在java环境中使用了ActiveMQ,然后我们又在Spring中使用了ActiveMQ 本来这样已经可以了,但是最近SpringBoot也来了.所以在其中也需要使用试试. 可以提前透露 ...
- tf.estimator.Estimator类的用法
官网链接:https://www.tensorflow.org/api_docs/python/tf/estimator/Estimator Estimator - 一种可极大地简化机器学习编程的高阶 ...
- SQL优化原则(转)
一.问题的提出 在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的的编写等体会不出SQL语句各种写法的性能优劣,但是如果将应用系统提交实际应用后,随着数据库中数据的增加,系统 ...