机器学习(Machine Learning)算法总结-决策树
一、机器学习基本概念总结
分类(classification):目标标记为类别型的数据(离散型数据)
回归(regression):目标标记为连续型数据
有监督学习(supervised learning):训练集有类别标记
无监督学习(unsupervised learning):训练集无类别标记
半监督学习(semi-supervised learning):有类别标记的训练集+无类别标记的训练集
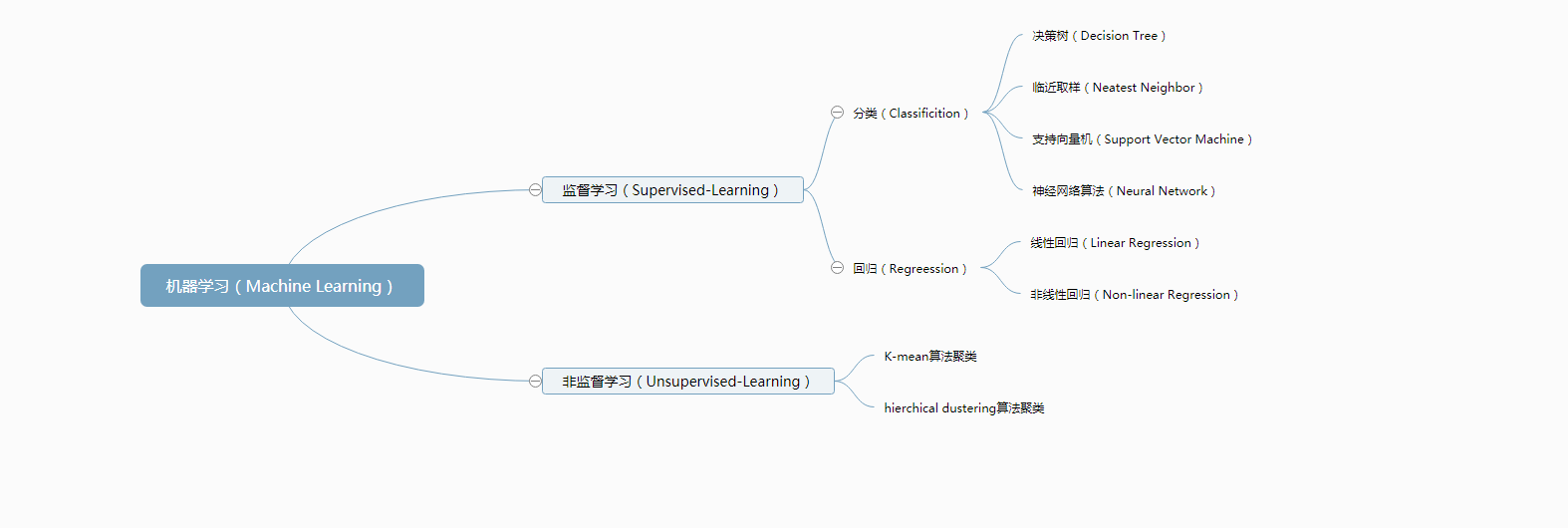
机器学习步骤的框架:
- step1:把数据拆分为训练集和测试集
- step2:用训练集和特征集的特征向量来训练算法
- step3:用学习来的算法(进行训练的模型)运用在测试集上来评估算法
机器学习中分类和预测算法的评估:
- 准确率
- 速度
- 强壮性(当数据缺失情况下,算法的准确性)
- 可规模性(当数据变大时,算法的准确性)
- 可解释性(算法的结果是否可以解释该种现象)
二、决策树
1.决策树基本概念:
- 是一个类似于流程图的树结构(可以是二叉树或非二叉树)
- 其每个非叶节点表示一个特征属性上的测试
- 每个分支代表这个特征属性在某个值域上的输出
- 而每个叶节点存放一个类别
- 使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果的过程
2.决策树构造的关键
决策树最重要的是决策树的构造。所谓决策树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结构。
构造决策树的关键步骤是分裂属性。
所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。
分裂属性分为三种不同的情况:
- 属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
- 属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
- 属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
3.决策树ID3算法(通过信息增益来构建决策树)
熵(entropy):表示状态的混乱程度,熵越大越混乱。
熵的变化可以看做是信息增益,决策树ID3算法的核心思想是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
设D为用(输出)类别对训练元组进行的划分,则D的熵表示为:
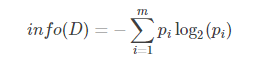
如果将训练元组D按属性A进行划分,则A对D划分的期望信息为:
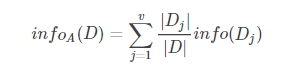
于是,信息增益就是两者的差值:
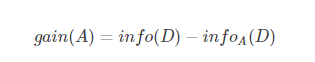
通过举例来理解ID3算法决策树的构造:
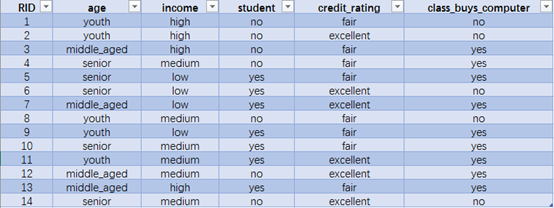
信息增益的计算过程如下图所示:
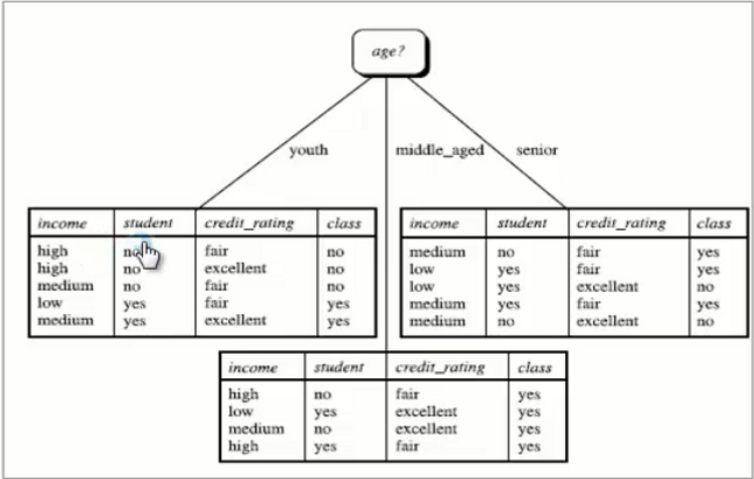

4.决策树C4.5算法(通过信息增益率来构建决策树)
ID3有一些缺陷,就是选择的时候容易选择一些比较容易分纯净的属性,尤其在具有像ID值这样的属性,因为每个ID都对应一个类别,所以分的很纯净
ID3比较倾向找到这样的属性做分裂。
C4.5算法定义了分裂信息,表示为:
信息增益率:
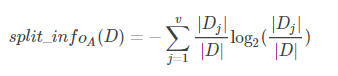
C4.5就是选择最大增益率的属性来分裂,其他类似ID3算法。
5.停止条件
决策树的构建过程是一个递归的过程,所以需要确定停止条件,否则过程将不会结束。
一种最直观的方式是当每个子节点只有一种类型的记录时停止,但是这样往往会使得树的节点过多,导致过拟合问题(Overfitting)。
另一种可行的方法是当前节点中的记录数低于一个最小的阀值,那么就停止分割,将max(P(i))对应的分类作为当前叶节点的分类。
6.过渡拟合
采用上面算法生成的决策树在事件中往往会导致过滤拟合。也就是该决策树对训练数据可以得到很低的错误率,但是运用到测试数据上却得到非常高的错误率。
过渡拟合的原因有以下几点:
- 噪音数据:
训练数据中存在噪音数据,决策树的某些节点有噪音数据作为分割标准,导致决策树无法代表真实数据。
- 缺少代表性数据:
训练数据没有包含所有具有代表性的数据,导致某一类数据无法很好的匹配,这一点可以通过观察混淆矩阵(Confusion Matrix)分析得出。
- 多重比较(Mulitple Comparition):
举个列子,股票分析师预测股票涨或跌。
假设分析师都是靠随机猜测,也就是他们正确的概率是0.5。每一个人预测10次,那么预测正确的次数在8次或8次以上的概率为 image,只有5%左右,比较低。
但是如果50个分析师,每个人预测10次,选择至少一个人得到8次或以上的人作为代表,那么概率为 image,概率十分大,随着分析师人数的增加,概率无限接近1。
但是,选出来的分析师其实是打酱油的,他对未来的预测不能做任何保证。
上面这个例子就是多重比较。这一情况和决策树选取分割点类似,需要在每个变量的每一个值中选取一个作为分割的代表,所以选出一个噪音分割标准的概率是很大的。
优化方案1:修剪枝叶
决策树过渡拟合往往是因为太过“茂盛”,也就是节点过多,所以需要裁剪(Prune Tree)枝叶。
裁剪枝叶的策略对决策树正确率的影响很大。主要有两种裁剪策略。
- 前置裁剪
在构建决策树的过程时,提前停止。
那么,会将切分节点的条件设置的很苛刻,导致决策树很短小。
结果就是决策树无法达到最优。实践证明这中策略无法得到较好的结果。
- 后置裁剪
决策树构建好后,然后才开始裁剪。
采用两种方法:
- 1)用单一叶节点代替整个子树,叶节点的分类采用子树中最主要的分类;
- 2)将一个字树完全替代另外一颗子树。后置裁剪有个问题就是计算效率,有些节点计算后就被裁剪了,导致有点浪费。
优化方案2:K-Fold Cross Validation(K-Fold交叉验证)
首先计算出整体的决策树T,叶节点个数记作N,设i属于[1,N]。
对每个i,使用K-Fold Validataion方法计算决策树,并裁剪到i个节点,计算错误率,最后求出平均错误率
这样可以用具有最小错误率对应的i作为最终决策树的大小,对原始决策树进行裁剪,得到最优决策树。
优化方案3:Random Forest(随机森林)
Random Forest是用训练数据随机的计算出许多决策树,形成了一个森林。
然后用这个森林对未知数据进行预测,选取投票最多的分类。
实践证明,此算法的错误率得到了进一步的降低。这种方法背后的原理可以用“三个臭皮匠定一个诸葛亮”这句谚语来概括。
一颗树预测正确的概率可能不高,但是集体预测正确的概率却很高。
备注:5,6内容摘自http://www.cnblogs.com/bourneli/archive/2013/03/15/2961568.html
三、Python程序实现
就是上面的那个例子的程序实现
#DictVectorizer:字典特征提取器(将字典类型数据结构的样本,抽取特征,转化成向量形式,通常用来对数据进行预处理)
from sklearn.feature_extraction import DictVectorizer
#csv文件处理模块(CSV(Comma-Separated Values)即逗号分隔值,纯文本文件,以,作为分隔符,分隔两个单元格,值没有类型,所有值都是字符串,使用专门的模块进行处理)
import csv
from sklearn import tree
#sklearn数据预处理模块
from sklearn import preprocessing
from sklearn.externals.six import StringIO # 读取csv文件的数据,并进行预处理
allElectronicsData = open('AllElectronics.csv', 'r')
reader = csv.reader(allElectronicsData)
# 读取csv文件中第一行内容,即表头内容。reader只能被遍历一次。由于reader是可迭代对象,可以使用next方法一次获取一行(),所以经过next方法后的reader中已经没有第一行
headers = next(reader) featureList = [] #定义特征空列表
labelList = [] #定义标签空列表 for row in reader:
labelList.append(row[len(row)-1]) #读取每一行的最后一个数据(即为标签向量)
rowDict = {}
for i in range(1, len(row)-1): #遍历每一行数据中的第二元素到倒数第二个元素(即为特征向量)
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
# 将字典类型数据结构的样本,抽取特征,转化成向量形式,并打印
#处理特征向量
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList) .toarray()
print("featureList:"+ "\n" + str(vec.get_feature_names()))
print("dummyX: " + "\n" + str(dummyX))
#处理标签向量
print("labelList: " + "\n" + str(labelList))
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: " + "\n" + str(dummyY)) # 利用决策树进行分类
# clf = tree.DecisionTreeClassifier()
clf = tree.DecisionTreeClassifier(criterion='entropy') #criterion='entropy'该参数为特征选择标准,默认为‘gini’,为基尼系数,'entropy'为信息熵
clf = clf.fit(dummyX, dummyY)
print("clf: " + str(clf)) # 可视化模型的建立
with open("allElectronicInformationGainOri.dot", 'w') as f:
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f) #生成的dot文件内有生成决策树的相关信息,可以通过Graphviz,将doc文件至pdf,可视化决策树 #取已有数据第一行,进行数据修改后,实现预测
oneRowX = dummyX[0, :]
print("oneRowX: " + str(oneRowX)) newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX: " + str(newRowX)) predictedY = clf.predict(newRowX)
print("predictedY: " + str(predictedY))
四、可视化工具 graphviz下载
Windows下载地址:https://graphviz.gitlab.io/_pages/Download/Download_windows.html

双击msi文件,然后一直next(记住安装路径,后面配置环境变量会用到路径信息),安装完成之后,会在windows开始菜单创建快捷信息,默认快捷方式不放在桌面。
配置环境变量
将graphviz安装目录下的bin文件夹添加到Path环境变量中:
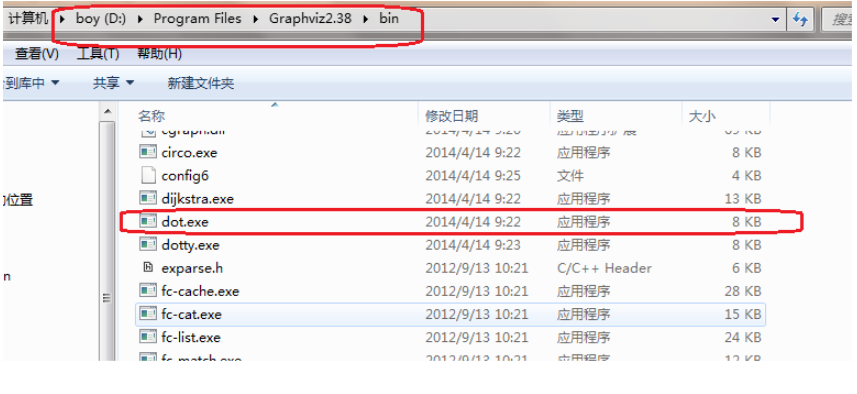
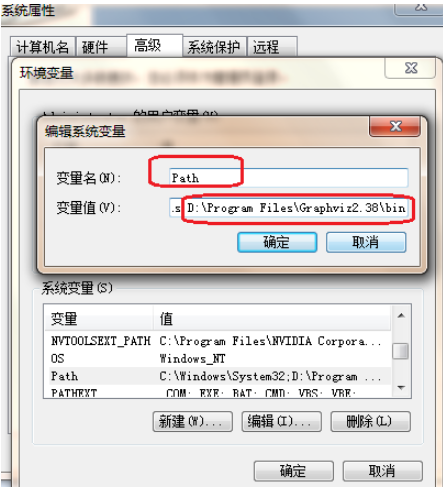
验证
进入windows命令行界面,输入dot -version,然后按回车,如果显示graphviz的相关版本信息,则安装配置成功。
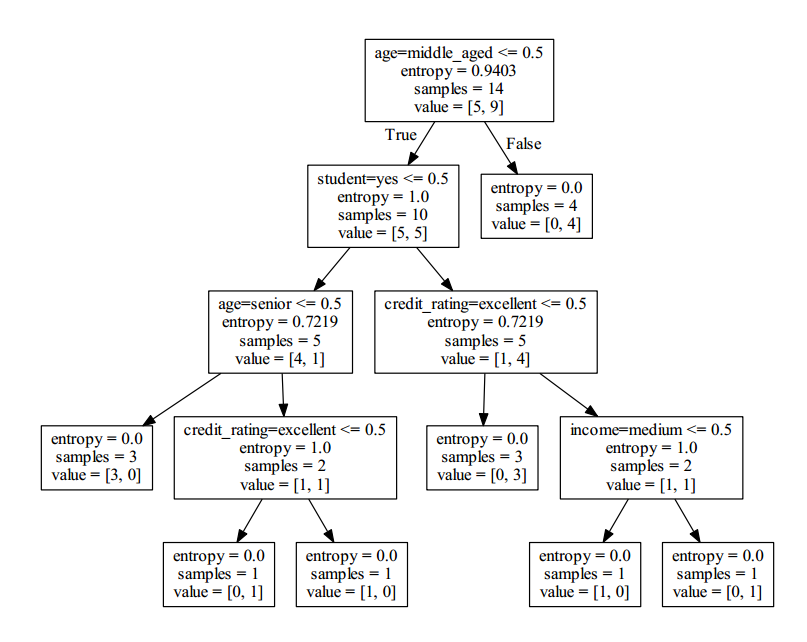
将dot文件转换为pdf文件
dot -Tpdf tree.dot -o tree.pdf
将上面写的程序的dot文件转换为pdf
机器学习(Machine Learning)算法总结-决策树的更多相关文章
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料
机器学习(Machine Learning)&深度学习(Deep Learning)资料 機器學習.深度學習方面不錯的資料,轉載. 原作:https://github.com/ty4z2008 ...
- 数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)的区别是什么? 数据科学(data science)和商业分析(business analytics)之间有什么关系?
本来我以为不需要解释这个问题的,到底数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)有什么区别,但是前几天因为有个学弟问我,我想了想发现我竟然也回答 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)---#####注:机器学习资料[篇目一](https://github.co ...
- 【重磅干货整理】机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总
[重磅干货整理]机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总 .
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- 机器学习(Machine Learning)&深入学习(Deep Learning)资料
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost 到随机森林. ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料汇总 (上)
转载:http://dataunion.org/8463.html?utm_source=tuicool&utm_medium=referral <Brief History of Ma ...
- 机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
随机推荐
- 4、python常用基础类型介绍
1.字符串 str 描述性质的一种表示状态的例如名字 word='helloworld' print(type(word),word) <class 'str'> helloworld2. ...
- as3.0 嵌入字体的用法
var txt:TextField = new TextField();//创建文本 txt.embedFonts=true;//确定嵌入字体 var font:Font=new MyFont();/ ...
- 287. Find the Duplicate Number 找出数组中的重复数字
[抄题]: Given an array nums containing n + 1 integers where each integer is between 1 and n (inclusive ...
- js string to date
Date.prototype.pattern=function(fmt) { //alert(this.getFullYear()); fmt=fmt.toUpperCase(); var o = { ...
- 【Spark2.0源码学习】-8.SparkContext与Application介绍
在前面的内容,我们针对于RpcEndpoint启动以及RpcEndpoint消息处理机制进行了详细的介绍,在我们的大脑里,基本上可以构建Spark各节点的模样.接下来的章节将会从Sp ...
- 将小程序的logo换成属于自己的头像
$logo = file_get_contents(IMG_URL.$logo); //根据头像的路径 $logo = yuanImg1($logo); //将头像改为圆形 $data = file_ ...
- C# Form Chart X刻度左右多余一格怎么去掉
如上图所示:形成的chart,1和8时y没有值,我实际给的也是2~7的数,可视1和8的刻度却在,怎么去掉,谢谢. 解决方法:chart1.ChartAreas[0].AxisX.IsMarginVis ...
- springboot项目新功能开发
在原有的springboot项目上,复制了一个,然后将其中的src下的所有java文件都删除,gradle下把中间件都删除,直流springframework的,重新启动,发现 错误Failed to ...
- python中for循环的三种遍历方式
#!/usr/bin/env python# -*- coding: utf-8 -*-if __name__ == '__main__': list = ['A', 'B', 'C', 'D'] # ...
- spring-boot json数据交互
SpringBoot学习之Json数据交互 最近在弄监控主机项目,对javaweb又再努力学习.实际的项目场景中,前后分离几乎是所以项目的标配,全栈的时代的逐渐远去,后端负责业务逻辑处理,前端负责数据 ...