深度学习基础(一)LeNet_Gradient-Based Learning Applied to Document Recognition
作者:Yann LeCun,Leon Botton, Yoshua Bengio,and Patrick Haffner
这篇论文内容较多,这里只对部分内容进行记录:
以下是对论文原文的翻译:
在传统的模式识别模型中,往往会使用手动设计的特征提取器从输入中提取相关信息并去除不相关的可变性,然后一个可训练的分类器对这些提取到的特征进行分类。在本论文的方案中,标准的全连接多层网络就相当于分类器,并且该方案尽可能多地依赖特征提取器本身的学习。在字符识别任务中,一个网络可以将几乎未经过处理的数据作为输入。虽然任意一个全连接前向网络在字符识别等任务中能够取得不错的效果,但是仍然有不少问题存在。
首先,输入的图像一般都很大,经常有几百个变量(即像素)。如果采用全连接网络的话,即使第一个隐含层仅有100个神经元,那前两层之间的权重参数也会有几万个。数量如此大的参数会增加系统的容量,但也因此需要更大的训练集。而且,在某些硬件设备上实现时由于需要存储的参数如此多,可能会带来内存不足的问题。但是,用于图像或语音的非结构化网络的主要缺陷是,对于转换或输入的局部失真没有内在的不变性。在被提供给神经网络固定大小的输入层之前,字符图像或其他2D或1D信号必须近似地标准化并居于输入域的中心。不幸的是,没有这样完美的预处理:手写体通常在单词级别标准化,这可能导致单个字符的大小、倾斜和位置变化。这一点,再加上书写风格的多样性,会导致输入对象中不同特征的位置发生变化。原则上,一个足够大的全连接网络可以学习产生与这种变化不同的产出。然而,学习这样一项任务可能会导致在输入中不同位置具有相似权重模式的多个单元,从而在输入中不同特征出现的任何地方检测到这些特征。学习这些权重参数需要数目巨大的训练样本来覆盖可能的变化空间。
其次,全连接结构忽略了输入的整体结构。输入变量可以以任何不影响训练输出的顺序给定。与变量不同的是,图像有很强的2D局部结构:像素在空间上是高度相关的。
卷积神经网络结合了三种结构的思想以确保一定程度的平移、缩放和畸变不变性:局部感受野(local receptive fields)、权值共享(shared weights )或权值复制(weights replication)和时间或空间子采样(sub-sampling)。图中展示的LeNet-5是一种用于识别字符的典型卷积神经网络。网络中输入平面接收尺寸统一且中心对齐后的字符图像。
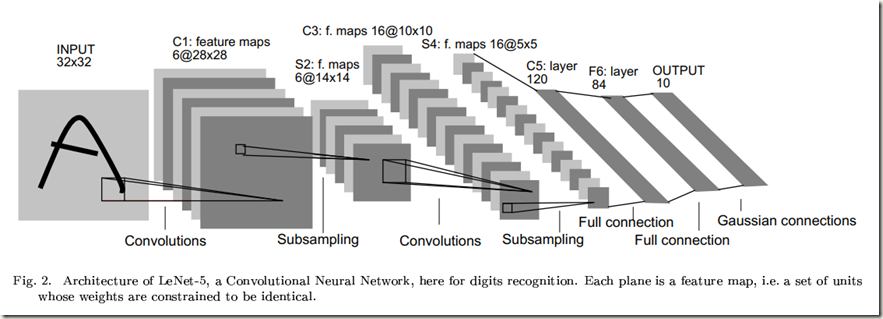
LeNet-5结构描述:
不加输入层的话,该网络共有7层权重层。
输入是一个32*32的像素图像。该尺寸比数据集中最大的字符要大得多(最多20*20个像素位于28*28的中心区域),这是为了确保潜在的显著特征比如笔画终点和拐角能够位于高层特征检测算子的感受野中。在LeNet-5中,最后一层卷积层的感受野的中心点集在32*32输入的中心形成一个20*20的区域。输入的像素值会先标准化以便于背景(white)与-0.1对应,前景(black)与1.175对应。该操作使得输入的平均值大概为0,并且方差为1,这样有助于加速学习。
卷积层(C1)有6个特征图(feature map)。特征图中的每个神经元与输入中的一个5*5邻域相连接。特征图的尺寸是28*28,相较于前一层有所缩小,这是因为进行卷积操作时仅在图像内部进行卷积,而没有对边缘进行padding。C1层包含有156个可训练参数和122,304个连接。
子采样层(S2)含有6个特征图,每个特征图的尺寸是14*14。特征图的每个单元与C1层中相应的特征图的2*2邻域相连(核是单通道单feature map)。计算过程是:先将邻域内输入的四个单元相加,然后乘上一个可训练系数,再加上一个可训练偏置,计算结果会经过sigmoid函数作用。该层中2*2的感受野不重叠,因此S2中特征图的尺寸是C1中特征图的一半。S2层有12个可训练参数和5,880个连接。(我看有的代码中将该层当做MaxPooling层)
卷积层(C3)有16个特征图,每个特征图的尺寸是10*10。特征图的每个神经元与S2层中几个特征图相同位置的5*5的邻域相连(卷积核是单通道多feature map的)(有的代码中将该层当做有16个滤波器的卷积层,即正常的卷积层)。下表展示了S2中特征图与C3中特征图的对应情况:

至于为什么C3中的特征图不与S2的所有特征图均相连,论文中是这样解释的:首先,不完全连接能够保证连接的数量在一个合理的范围内,也就是说保证连接的数量不会太多。更重要的是,这样安排打破了对称,不同的特征图可以提取不同的特征,因为它们被分配的输入集不同。
上面表格中贴出的连接关系有如下特点:C3中前6个特征图分别从S2中连续的3个特征图获取输入;C3中接下来6个特征图分别从S2中连续的4个特征图获取输入;接下来3个特征图分别从S2中4个不连续的特征图获取输入;最后一个特征图从S2中的所有特征图获取输入。
C3层有1,516(60*25+16)个训练参数和151,600个连接。同样没有padding。在权重分配上值得注意的是:C3层中某个特征图从S2中部分的特征图获取输入时,它们共享偏置,但是每个卷积核的权重不同。比如,C3中第一个feature map从S2中前三个feature map获取输入,在计算时一共有三个卷积核(5*5*3=75个可训练参数)和一个共享的偏置(1个可训练参数),所以一共76个trainable parameters.
子采样层(S4)有16个尺寸为5*5的特征图。特征图的每个神经元从C3层中与之对应的特征图中的2*2邻域获取输入。S4层有32个可训练参数和2,000个连接(当做MaxPooling层120)
卷积层(C5)有120个特征图。特征图的每个神经元从S4层的所有特征图的5*5邻域获取输入。因为S4层的特征图的尺寸也为5*5,所以C5特征图的尺寸为1*1,这就相当于S4与C5之间存在一个全连接层。但是C5被称作卷积层而不是全连接层,这是因为如果LeNet-5的输入变得更大,那么特征图的维度会超过1*1。卷积网络的尺寸可以动态递增,这个过程会在论文的后面介绍。该层一共有48,120个训练参数,计算方法与C3层相同。
全连接层(F6)包含84个神经元,与C5层全连接。该层神经元数目是根据输出层设定的,在后面会解释。层中一共有10,164个训练参数
最后,输出层由欧氏径向基函数单元(RBF)组成,每个类一个,每个输入84个。
关于径向基函数的详细信息可以参考这里
深度学习基础(一)LeNet_Gradient-Based Learning Applied to Document Recognition的更多相关文章
- Gradient-Based Learning Applied to Document Recognition 部分阅读
卷积网络 卷积网络用三种结构来确保移位.尺度和旋转不变:局部感知野.权值共享和时间或空间降采样.典型的leNet-5如下图所示: C1中每个特征图的每个单元和输入的25个点相连,这个5* ...
- 算法工程师<深度学习基础>
<深度学习基础> 卷积神经网络,循环神经网络,LSTM与GRU,梯度消失与梯度爆炸,激活函数,防止过拟合的方法,dropout,batch normalization,各类经典的网络结构, ...
- [笔记] 基于nvidia/cuda的深度学习基础镜像构建流程 V0.2
之前的[笔记] 基于nvidia/cuda的深度学习基础镜像构建流程已经Out了,以这篇为准. 基于NVidia官方的nvidia/cuda image,构建适用于Deep Learning的基础im ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- TensorFlow深度学习基础与应用实战高清视频教程
TensorFlow深度学习基础与应用实战高清视频教程,适合Python C++ C#视觉应用开发者,基于TensorFlow深度学习框架,讲解TensorFlow基础.图像分类.目标检测训练与测试以 ...
- 深度学习编译与优化Deep Learning Compiler and Optimizer
深度学习编译与优化Deep Learning Compiler and Optimizer
- 深度学习基础(五)ResNet_Deep Residual Learning for Image Recognition
ResNet可以说是在过去几年中计算机视觉和深度学习领域最具开创性的工作.在其面世以后,目标检测.图像分割等任务中著名的网络模型纷纷借鉴其思想,进一步提升了各自的性能,比如yolo,Inception ...
- 机器学习&深度学习基础(tensorflow版本实现的算法概述0)
tensorflow集成和实现了各种机器学习基础的算法,可以直接调用. 代码集:https://github.com/ageron/handson-ml 监督学习 1)决策树(Decision Tre ...
随机推荐
- hadoop HA (no zkfc to stop) DFSZKFailoverController进程没有启动
这个bug确实恶心的不要不要的.我一开始以为是我自己打开方式(毕竟不熟悉搭建流程,别人怎么做,我照着做) 我照着视频或者博客编写hdfs-site.xml(dfs.ha.fencing.methods ...
- atitit r9 doc on home ntpc .docx
卷 p2soft 的文件夹 PATH 列表 卷序列号为 9AD0-D3C8 D:. │ Aittit pato 面对拒绝 的回应.docx │ Atitit 中国明星数量统计 attilax. ...
- MySQL主从复制作用和原理
一.什么是主从复制?主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库:主数据库一般是准实时的业务数据库. 二.主从复制的作用1.做数据的热备,作为后备数据库,主数据库服务器故障后, ...
- kali 安装google chrome浏览器(离线手动)
一.官网下载安装包 需要在google官网下载chrome安装包,安装时请仔细选择安装包,.deb的安装包适用于Debian/Ubuntu系统,.rpm适用于 Fedora/openSUSE系统. k ...
- 使用ffmpeg搭建HLS直播系统
[时间:2018-04] [状态:Open] [关键词:流媒体,stream,HLS, ffmpeg,live,直播,点播, nginx, ssegment] 0 引言 本文作为HLS综述的后续文章. ...
- C++ 函数模板的返回类型如何确定?
函数模板 #include <iostream> // 多个参数的函数木板 template<typename T1, typename T2> T2 max(T1 a, T2 ...
- fastDFS 命令笔记
端口开放 这是命令运行的前提 iptables -I INPUT -p tcp -m state –state NEW -m tcp –dport 22 -j ACCEPT iptables -I I ...
- JSON API免费接口(转)
电商接口 京东获取单个商品价格接口: http://p.3.cn/prices/mgets?skuIds=J_商品ID&type=1 用例 ps:商品ID这么获取:http://item.jd ...
- 【QT】文件读写操作
读取输出: QFile file("D:/Englishpath/QTprojects/1.dat"); if(!file.open(QIODevice::ReadOnly)) { ...
- Tensorflow1.4 高级接口使用(estimator, data, keras, layers)
TensorFlow 高级接口使用简介(estimator, keras, data, experiment) TensorFlow 1.4正式添加了keras和data作为其核心代码(从contri ...