python动态爬取网页
简介
有时候,我们天真无邪的使用urllib库或Scrapy下载HTML网页时会发现,我们要提取的网页元素并不在我们下载到的HTML之中,尽管它们在浏览器里看起来唾手可得。
这说明我们想要的元素是在我们的某些操作下通过js事件动态生成的。举个例子,我们在刷QQ空间或者微博评论的时候,一直往下刷,网页越来越长,内容越来越多,就是这个让人又爱又恨的动态加载。
爬取动态页面目前来说有两种方法
- 分析页面请求
- selenium模拟浏览器行为
1.分析页面请求
键盘F12打开开发者工具,选择Network选项卡,选择JS(除JS选项卡还有可能在XHR选项卡中,当然也可以通过其它抓包工具),如下图
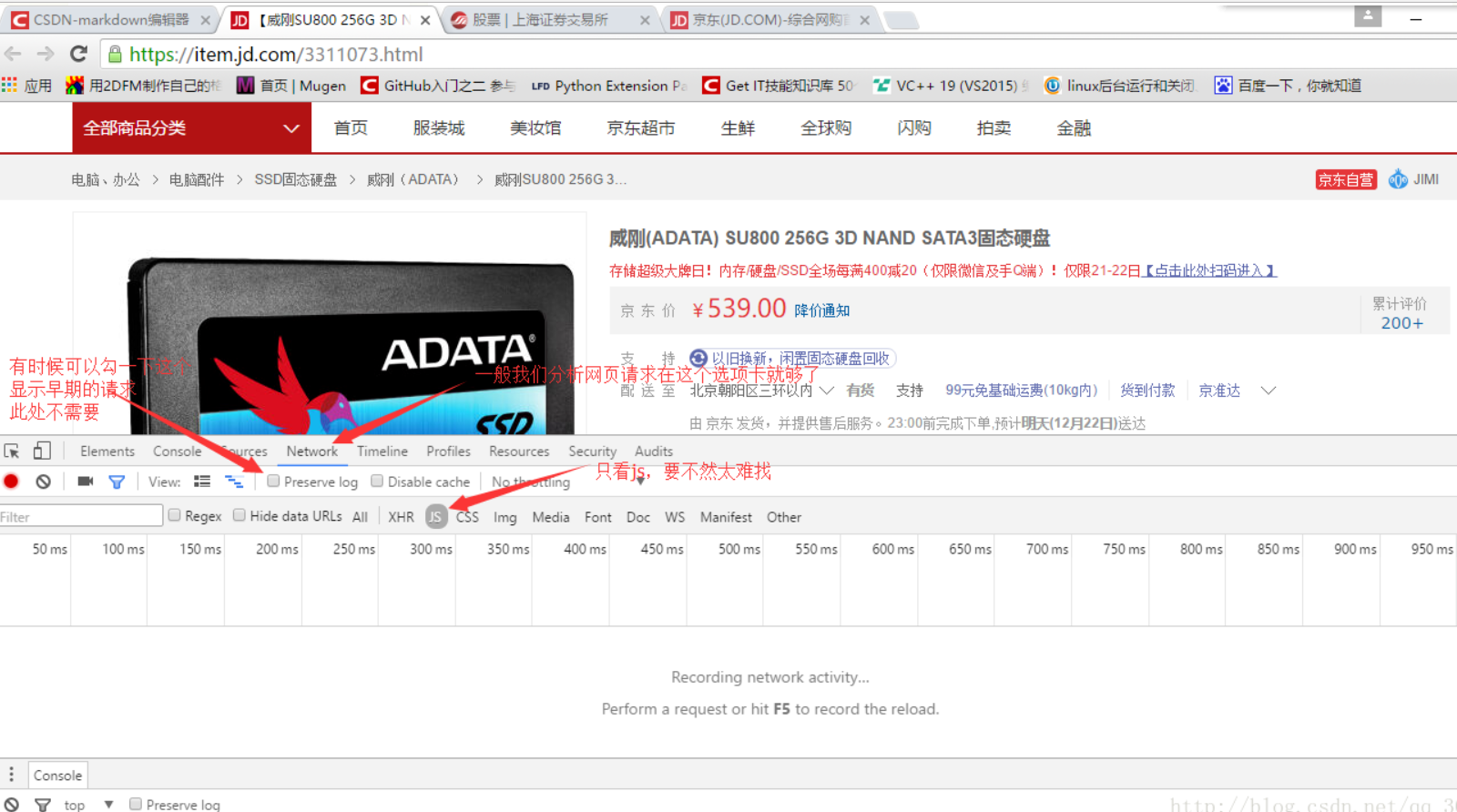
然后,我们来拖动右侧的滚动条,这时就会发现,开发者工具里出现了新的js请求(还挺多的),不过草草翻译一下,很容易就能看出来哪个是取评论的,如下图
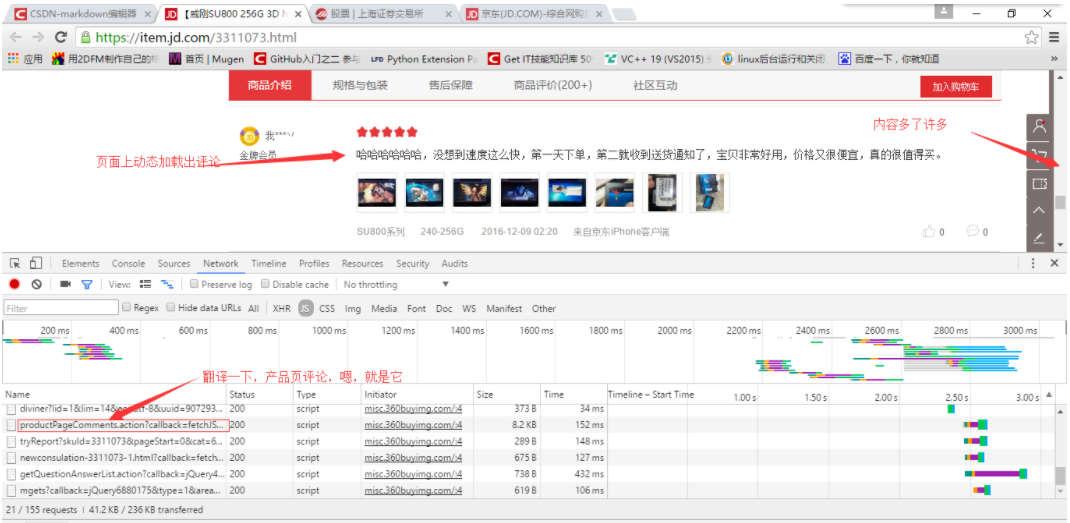
好,复制出js请求的目标url

在浏览器中打开,发现我们想要的数据就在这里,如下图
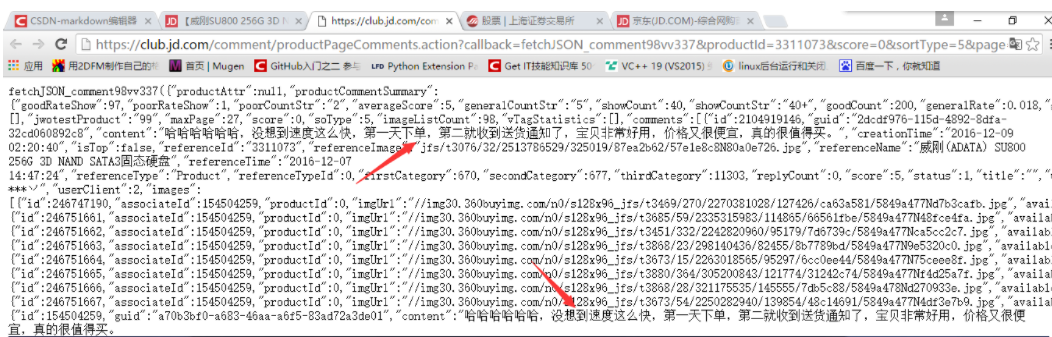
这整个页面是一个json格式的数据,对于京东来说,当用户下拉页面时,触发一个js事件,向服务器发送上面的请求取数据,然后通过一定的js逻辑把取到的这些json数据填充到HTML页面当中。对于我们Spider来说,我们要做的就是把这些json数据整理提取。
在实际应用中,当然我们不可能去每个页面里找出来这个js发起的请求目标地址,所以我们需要分析这个请求地址的规律,一般情况下规律是比较好找的,因为规律太复杂服务方维护也难。
2.selenium模拟浏览器行为
对于动态加载,能看到Selenium+Phantomjs的强大。打开网页查看网页源码(注意不是检查元素)会发现要爬取的信息并不在源码里面。也就是说,从网页源码无法通过解析得到数据。Selenium+Phantomjs的强大一方面就在于能将完整的源码抓取到
例子:在豆瓣电影上根据给出的名字搜索对应的信息
#-*- coding:utf-8 -*-
import sys
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup reload(sys)
sys.setdefaultencoding('utf-8') url = 'https://movie.douban.com/'
#这个路径就是你添加到PATH的路径
driver = webdriver.PhantomJS(executable_path='C:/Python27/Scripts/phantomjs-2.1.1-windows/bin/phantomjs.exe')
driver.get(url)
#在搜索框上模拟输入信息并点击
elem = driver.find_element_by_name("search_text")
elem.send_keys("crazy")
elem.send_keys(Keys.RETURN)
#得到动态加载的网页
data = driver.page_source
soup = BeautifulSoup(data, "lxml")
# 进行匹配
for i in soup.select("div[class='item-root']"):
name = i.find("a", class_="title-text").text
pic = i.find("img").get('src')
url = i.find("a").get('href')
rate = ""
num = ""
if i.find("span", class_="rating_nums") is None:
print name.encode("gbk", "ignore"), pic, url
else:
rate = i.find("span", class_="rating_nums").text
num = i.find("span", class_="pl").text
print name.encode("gbk", "ignore"),pic,url,rate.encode("gbk", "ignore"),num.encode("gbk", "ignore")
python动态爬取网页的更多相关文章
- python之爬取网页数据总结(一)
今天尝试使用python,爬取网页数据.因为python是新安装好的,所以要正常运行爬取数据的代码需要提前安装插件.分别为requests Beautifulsoup4 lxml 三个插件 ...
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
- python 嵌套爬取网页信息
当需要的信息要经过两个链接才能打开的时候,就需要用到嵌套爬取. 比如要爬取起点中文网排行榜的小说简介,找到榜单网址:https://www.qidian.com/all?orderId=&st ...
- Python爬虫爬取网页图片
没想到python是如此强大,令人着迷,以前看见图片总是一张一张复制粘贴,现在好了,学会python就可以用程序将一张张图片,保存下来. 今天逛贴吧看见好多美图,可是图片有点多,不想一张一张地复制粘贴 ...
- 1.记我的第一次python爬虫爬取网页视频
It is my first time to public some notes on this platform, and I just want to improve myself by reco ...
- Python:爬取网站图片并保存至本地
Python:爬取网页图片并保存至本地 python3爬取网页中的图片到本地的过程如下: 1.爬取网页 2.获取图片地址 3.爬取图片内容并保存到本地 实例:爬取百度贴吧首页图片. 代码如下: imp ...
- 如何使用python爬取网页动态数据
我们在使用python爬取网页数据的时候,会遇到页面的数据是通过js脚本动态加载的情况,这时候我们就得模拟接口请求信息,根据接口返回结果来获取我们想要的数据. 以某电影网站为例:我们要获取到电影名称以 ...
- Python+Selenium爬取动态加载页面(2)
注: 上一篇<Python+Selenium爬取动态加载页面(1)>讲了基本地如何获取动态页面的数据,这里再讲一个稍微复杂一点的数据获取全国水雨情网.数据的获取过程跟人手动获取过程类似,所 ...
- Python+Selenium爬取动态加载页面(1)
注: 最近有一小任务,需要收集水质和水雨信息,找了两个网站:国家地表水水质自动监测实时数据发布系统和全国水雨情网.由于这两个网站的数据都是动态加载出来的,所以我用了Selenium来完成我的数据获取. ...
随机推荐
- canvas 绘制坐标轴
结果: 代码: <!DOCTYPE html> <html> <head lang="en"> <meta charset="U ...
- 【Java 并发】Executor框架机制与线程池配置使用
[Java 并发]Executor框架机制与线程池配置使用 一,Executor框架Executor框架便是Java 5中引入的,其内部使用了线程池机制,在java.util.cocurrent 包下 ...
- php项目,cpu暴增问题查找
背景: 前几天通过WordPress上线一个应用(前后台部署分离,后台走内网内部使用,前台做了全站缓存对外使用). 今天访问后台应用发现开始报504,一段时间后全部504. 解决方案: 登录容器发现容 ...
- Reinforcement Learning Q-learning 算法学习-4
Q-learning 相关的资料 https://www.youtube.com/watch?v=V1eYniJ0Rnk google deepmind 的Q-learning 算法打游戏的一个很酷的 ...
- CF632E: Thief in a Shop(快速幂+NTT)(存疑)
A thief made his way to a shop. As usual he has his lucky knapsack with him. The knapsack can contai ...
- HDU - 6231:K-th Number (不错的二分)
Alice are given an array A[1..N]A[1..N] with NN numbers. Now Alice want to build an array BB by a pa ...
- Robot Framework接口测试(3)--http请求之post
http请求更多的是post请求,我们可以:查看说明:很多网站在登录的时候需要加上头部信息即headers,这个信息可以通过抓包工具获得——fiddler,一个轻量级的抓包工具,大神用了都说好~这里模 ...
- 【Spring】Junit加载Spring容器作单元测试(整理)
[Spring]Junit加载Spring容器作单元测试 阅读目录 >引入相关Jar包 > 配置文件加载方式 > 原始的用法 > 常见的用法 > 引入相关Jar包 一.均 ...
- Java开发过程中乱码问题理解
1.Java编译器(即编译成class文件时) 用的是unicode字符集.2.乱码主要是由于不同的字符集相互转换导致的,理论上各个字符的编码规则是不同的,是不能相互转换的,所以根本解决乱码的方法就是 ...
- php通过时间戳处理时间!
1.获取当前时间方法date() 很简单,这就是获取时间的方法,格式为:date(format,format,timestamp),format为格式.timestamp为时间戳–可填参数. 2.获取 ...