KMP算法细讲(豁然开朗)
一.KMP算法是如何针对传统算法修改的
用模式串P去匹配字符串S,在i=6,j=4时发生失配:
---------------------------------------------------------------------
i=6
S: a b a b c a d c a c b a b
P: a b c a c
j=4
---------------------------------------------------------------------
此时,按照传统算法,应当将P的第 1 个字符 a(j=0) 滑动到与S中第4个字符 b(i=3) 对齐再进行匹配:
---------------------------------------------------------------------
i=3
S: a b a b c a a d a c b a b
P: a b c a c
j=0
---------------------------------------------------------------------
这个过程中,对字符串S的访问发生了“回朔”(从 i=6 移回到 i=3)。
我们不希望发生这样的回朔,而是试图通过尽可能的“向右滑动”模式串P,让P中index为 j 的字符对齐到S中 i=5 的字符,然后试图匹配S中 i=6 的字符与P中index为 j+1 的字符。
在这个测试用例中,我们直接将P向右滑动3个字符,使S中 i=5 的字符与P中 j=0 的字符对齐,再匹配S中 i=6 的字符与P中 j=1 的字符。
---------------------------------------------------------------------
i=6
S: a b a b c a d c a c b a b
P: a b c a c
j=0
---------------------------------------------------------------------
二.求KMP算法中的next

举例说明:
按上述定义给出next数组的一个例子:
j 0 1 2 3 4 5 6 7
P a b a a b c a c
next[j] -1 0 0 1 1 2 0 1
查找对称串
申明一下:下面说的对称不是中心对称,而是中心字符块对称,比如不是abccba,而是abcabc这种对称。
详解:
将j导入next函数,即可求得, j=0时,next[]=-1; j=1时,k的取值为(,1)的开区间,所以整数k是不存在的,那就是第三种情况,next[]=; j=2时,k的取值为(,)的开区间,k从最大的开始取值,然后带入含p的式子中验证等式是否成立,不成立k取第二大的值。现在是k=,将k导入p的式子中得,p0=p1,即“a”=“b”,
显然不成立,舍去。k再取值就超出范围了,所以next[]不属于第二种情况,那就是第三种了,即next[]=; j=3时,k的取值为(,)的开区间,先取k=,将k导入p的式子中得,p0p1=p1p2,不成立。 再取k=,得p0=p2,成立。所以next[]=; j=4时,k的取值为(,)的开区间,先取k=,将k导入p的式子中得,p0p1p2=p1p2p3,不成立。 再取k=,得p0p1=p2p3,不成立。 再取k=,得p0=p3,成立。所以next[]=;
……
在已知next数组的前提下,字符串匹配的步骤如下:
i 和 j 分别表示在主串S和模式串P中当前正待比较的字符
在匹配过程中的每一次循环,若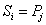 ,i 和 j 分别增 1,
,i 和 j 分别增 1,
else,j 退回到 next[j]的位置,此时下一次循环是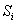 与
与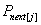 相比较。
相比较。
void getnext(int *next, char *p)
{
int j = , k = -;
next[] = -;
while(j < lenp-1)//-1
{
if(k == - || p[j] == p[k])
{
j++;
k++;
next[j] = k;//当j==0时,已经求出了next[1]的值,所以j<lenp-1
}
else
k = next[k];
}
}
三.getNext函数的进一步优化
注意到,上面的getNext函数还存在可以优化的地方,比如:
i=3
S: a a a b a a a a b
P: a a a a b
j=3
此时,i=3、j=3时发生失配,next[3]=2,此时还需要进行 3 次比较:
i=3, j=2;
i=3, j=1;
i=3, j=0。
而实际上,因为i=3, j=3时就已经知道a!=b,而之后的三次依旧是拿 a 和 b 比较,因此这三次比较都是多余的。
此时应当直接将P向右滑动4个字符,进行 i=4, j=0的比较。
一般而言,在getNext函数中,next[i]=j,也就是说当p[i]与S中某个字符匹配失败的时候,用p[j]继续与S中的这个字符比较。
如果p[i]==p[j],那么这次比较是多余的(如同上面的例子),此时应该直接使next[i]=next[j]。
void getNextUpdate(const std::string& p, std::vector<int>& next)
{
next.resize(p.size());
next[] = -; int i = , j = -; while (i != p.size() - )
{
//这里注意,i==0的时候实际上求的是nextVector[1]的值,以此类推
if (j == - || p[i] == p[j])
{
++i;
++j;
//update
//next[i] = j;
//注意这里是++i和++j之后的p[i]、p[j]
next[i] = p[i] != p[j] ? j : next[j];
}
else
{
j = next[j];
}
}
}
假定p.size()为m,分析其时间复杂度的困惑在于,在while里面不是每次循环都执行 ++i 操作,所以整个while的执行次数不一定为m。
换个角度,注意到在每次循环中,无论 if 还是 else 都会修改 j 的值且每次循环仅对 j 进行一次修改,所以在整个while中 j 被修改的次数即为getNext函数的时间复杂度。
每次成功匹配时,++i; ++j; , 由于 ++i 最多执行 m-1 次,故++j也最多执行 m-1 次,即 j 最多增加m-1次;
对应的,只有在 j=next[j]; 处 j 的值一定会变小,由于 j 最多增加m-1次,故 j 最多减小m-1次。
综上所述,getNext函数的时间复杂度为O(m),
若带匹配串S的长度为n,则kmp函数的时间复杂度为O(m+n)。(有待验证)
四、kmp的应用优势
①快,O(m+n)的线性最坏时间复杂度;
②无需回朔访问待匹配字符串S,所以对处理从外设输入的庞大文件很有效,可以边读入边匹配。
大部分转自GoAgent
http://www.cnblogs.com/goagent/archive/2013/05/16/3068442.html
KMP算法细讲(豁然开朗)的更多相关文章
- KMP算法的理解
---恢复内容开始--- 在看数据结构的串的讲解的时候,讲到了KMP算法——一个经典的字符串匹配的算法,具体背景自行百度之,是一个很牛的图灵奖得主和他的学生提出的. 一开始看算法的时候很困惑,但是算法 ...
- 【讲●解】KMP算法
KMP算法 我们小组负责讲这个... 术语与规定 为了待会方便,所以不得不做一些看起来很拖沓的术语,但这些规定能让我们更好地理解\(KMP\)甚至\(AC\)自动机. 字符串匹配形式化定义如下: 假设 ...
- 讲不明白自杀系列:KMP算法
算法:KMP排序 算法分析 KMP算法是一种快速的模式匹配算法.KMP是三位大师:D.E.Knuth.J.H.Morris和V.R.Pratt同时发现的,所以取首字母组成KMP. 少部分图片来自孤~影 ...
- 详讲KMP算法
两个字符串: 模式串:ababcaba 文本串:ababcabcbababcabacaba KMP算法作用:快速在文本串中匹配到模式串 如果是穷举法的方式: 大家有发现,这样比效率很低的. 所以就需要 ...
- Python 细聊从暴力(BF)字符串匹配算法到 KMP 算法之间的精妙变化
1. 字符串匹配算法 所谓字符串匹配算法,简单地说就是在一个目标字符串中查找是否存在另一个模式字符串.如在字符串 "ABCDEFG" 中查找是否存在 "EF" ...
- KMP算法
KMP算法是字符串模式匹配当中最经典的算法,原来大二学数据结构的有讲,但是当时只是记住了原理,但不知道代码实现,今天终于是完成了KMP的代码实现.原理KMP的原理其实很简单,给定一个字符串和一个模式串 ...
- Java数据结构之字符串模式匹配算法---KMP算法
本文主要的思路都是参考http://kb.cnblogs.com/page/176818/ 如有冒犯请告知,多谢. 一.KMP算法 KMP算法可以在O(n+m)的时间数量级上完成串的模式匹配操作,其基 ...
- KMP 算法
KMP 是一个字符串匹配算法.之所以称之为KMP 是因为这个算法是由Knuth.Morris.Pratt三个提出来的. 这个算法能干什么呢 ? 我想到的有三个: 1. 告诉你一个串是否是另外一个串的子 ...
- (原创)详解KMP算法
KMP算法应该是每一本<数据结构>书都会讲的,算是知名度最高的算法之一了,但很可惜,我大二那年压根就没看懂过~~~ 之后也在很多地方也都经常看到讲解KMP算法的文章,看久了好像也知道是怎么 ...
随机推荐
- hadoop复合键排序使用方法
在hadoop中处理复杂业务时,需要用到复合键,复合不同于单纯的继承Writable接口,而是继承了 WritableComparable<T>接口,而实际上,WritableCompar ...
- 你知道PING功能是怎么实现的吗
以太网的协议有层,而每层都包含有更多的协议.所谓协议,通俗的讲就是通信双方约定的规则. 今天我们介绍一些一个听起来陌生却有很常用的协议,ICMP协议. ICMP是(Internet Control ...
- shell编程中变量的运算 (shell 06)
主要包括以下3种 字符串操作数学运算浮点运算 一.字符串操作 字符串的连接 连接字2个字符串不需要任何连接符,挨着写即可 长度获取 expr length "hello" expr ...
- PTA 银行排队问题之单队列多窗口服务(25 分)
银行排队问题之单队列多窗口服务(25 分) 假设银行有K个窗口提供服务,窗口前设一条黄线,所有顾客按到达时间在黄线后排成一条长龙.当有窗口空闲时,下一位顾客即去该窗口处理事务.当有多个窗口可选择时,假 ...
- Sql Server优化之路
本文只限coder级别层次上对Sql Server的优化处理简结,为防止专业DB人士有恶心.反胃等现象,请提前关闭此页面. 首先得有一个测试库,使用数据生成计划生成测试数据库(参考:http://de ...
- requests的响应返回值显示content和text方法的区别
requests的get或者post请求,返回的响应response获取方法:content和text content用于获取图片,返回二进制数据 text用于获取内容,返回的是unicode解码字符 ...
- adb正常,手机启动usb调试,adb devices下没有改设备
手机开启开发者模式,adb正常时adb devices下没有设备: 1.进入设备管理器--查找adb的硬件id
- java - 只输出中文,(不包含标点)
String a ="12dss显示,‘:()中文只"; StringBuffer b = new StringBuffer(); for(int i = 0;i<a.len ...
- 【树莓派】RASPBIAN镜像初始化配置
[树莓派]如何烧录镜像详细版 接上一节,系统已经烧录完毕了,将其放置于树莓派然后运行起来 我是直接接显示器了,若有需要转接头的自行淘宝搜索购买~~电源使用的是5V 2.5A的 首次开机会时间较长 且有 ...
- 请求时控制器的返回结果view()怎么会默认调到某个页面的?
请求时控制器的返回结果view()怎么会默认调到某个页面的? (1)请求时会拿方法行为的名字去和视图的名字对应,会默认去views视图下的与控制器名称一样的文件夹下名字与方法对应的视图文件匹配对应,然 ...