极易扩展:1、基于上层处理能力的扩展(横向添加RegionServer机器,进行水平扩展,提升上层处理能力) 2、基于存储的扩展(HDFS ,横向添加datanode机器,进行存储层扩容)
Rowkey
Hbase表中的行键,和关系型数据库中的主键一样,用来区分某一行数据。Hbase根据RowKey检索,只支持3中方式:
(1)根据RowKey检索一条数据(2)根据RowKey进行range检索(3)全表检索
Column Family
列族,Hbase根据列族存储,在创建表的时候必须声明列族,列族中可以有很多列,实现数据的灵活存储
Region
Region的概念和关系型数据库中分区分片一样。Hbase将一个大表根据RowKey的不同范围分配到不同的Region当中,这样即使是一张大表,由于分割到不同的Region当中,访问的延迟也很低
TimeStamp
TimeStamp是Hbase实现多版本的关键所在,不同的TimeStamp来标记相同的RowKey的不同版本 。在不指定TimeStamp的情况下,Hbase会默认自动添加一个TimeStamp(服务器的当前时间),在Hbase中,相同的RowKey按照TimeStamp降序排列,最新版本的在最上面,Hbase默认读取最新版本
Cell
由{row key, columnFamily, version} 唯一确定的单元。cell中 的数据是没有类型的,全部是字节码形式存储。
2、HBase架构
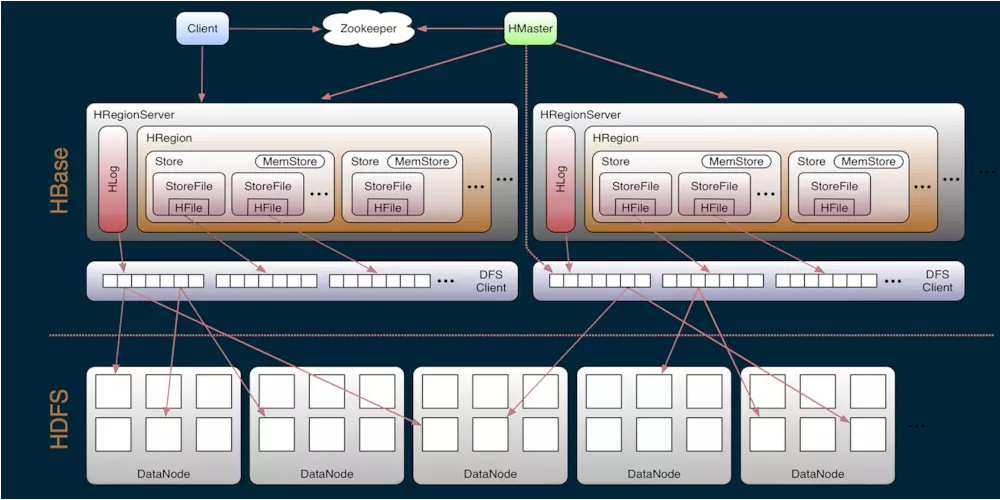
Hbase 由 Client 、Zookeeper、 HMaster、HRegionServer、HDFS等组件构成。
Client
访问Hbase的客户端,包括了访问接口(另外Client维护了cache来加速Hbase的访问)
Zookeeper
Hbase使用Zookeeper来做HMaster的高可用、RegionServer的监控、元数据的入口、集群的配置的维护工作
- Zookeeper保证Hbase集群中只有一个master在运行,如果master发生异常,则会通过竞争机制产生新的master节点
- Zookeeper监控RegionServer的状态,RegionServer发生异常时候,Zookeeper通过回调的方式通知HMaster RegionServer上下限的信息
- 通过Zookeeper作为元数据的统一入口地址
HMaster
- 为RegionServer分配HRegion(RegionServer上有多个Region),另外当RegionServer失效时候,协调HLog拆分(数据恢复)
- 维护集群的负载均衡,维护集群的元数据
- 发现失效的Region,并将失效的Region分配到正常的RegionServer上
HRegionServer
HRegionServer直接负责用户的读写请求,是真正干活的节点
- 直接和HDFS交互,存储数据到HDFS
- 负责Region变大以后的拆分和StoreFile的合并
- 管理Region,直接负责客户端的读写请求
HDFS
为Hbase提供最终的底层数据存储服务,同时为Hbase提供高可用(Hlog存储在HDFS)的支持,具体功能概括如下:
提供元数据和表数据的底层分布式存储服务,数据多副本,保证的高可靠和高可用性
说明:
1、HBase内部是通过DFS Client把数据写入到HDFS
2、每个HRegionServer有多个HRegion,每个HRegion有多个Store(每个Store对应一个列族)
3、Store是由MemStore(内存)和StoreFile(HDFS)组成
4、HFile是HBase中key/value的数据存储格式(HFile是Hadoop的二进制格式文件),StoreFile是对HFile的封装,进行数据的存储
5、HLog记录所有数据的变更,可以用来恢复数据
6、hdfs对应的目录结构:namespace/table/列族/列/单元格
3、HBase读写流程
3.1 HBase写流程

- Zookeeper中存储着meta表的信息,从meta表中找出相应的region信息,根据namespace、表名、RowKey,从meta表中的数据找到写入数据对应的region信息,找到该Region所在的HRegionServer
- 找到所在的HRegionServer之后,把数据写到HLog和MemStore上
- MemStore达到一个阈值之后则把数据刷成一个StoreFile文件(若MemStore数据丢失,可以从HLog中恢复)
- 当StoreFile达到一定大小之后,会触发Compact合并操作(合并操作是为了整合成最终的数据,去除重复性的更新操作等),合并为一个StoreFile(这里有Store的合并和数据的删除)
- 当compact之后,逐渐形成越来越大的StoreFile,会触发split(拆分)操作,把当前的StoreFile分成两个StoreFile(相当于将一个Region分成两个),拆分后的StoreFile文件分别会写入到另外的RegionServer上(对应的映射信息回写入到meta表中,方便以后的查找)
如下图:

3.2 HBase的读流程
- zookeeper中存储了meta表的region信息,所以先从zookeeper中找到meta表region的位置,然后读取meta表中的数据。meta中又存储了用户表的region信息。
- 根据namespace、表名和rowkey在meta表中找到对应的region信息
- 找到这个region对应的regionserver
- 查找对应的region
- 先从MemStore找数据,如果没有,再到StoreFile上读(为了读取的效率,所有Hbase写慢读快)
3.3 MemStore刷盘
在写数据过程中,MemStore达到一定的阈值之后,后续会逐渐的刷入到HDFS中,为了提高HBase的性能,HBase不会立刻刷盘,而是等到一定时候或者满足一定条件之后进行刷盘
(1)全局内存控制
这个全局的参数是控制内存整体的使用情况,当所有memstore占整个heap的最大比例的时候,会触发刷盘的操作。这个参数是hbase.regionserver.global.memstore.upperLimit,默认为整个heap内存的40%。但这 并不意味着全局内存触发的刷盘操作会将所有的MemStore都进行刷盘,而是通过另外一个参数hbase.regionserver.global.memstore.lowerLimit来控制,默认是整个heap内存的35%。当flush到所有memstore占整个heap内存的比率为35%的时候,就停止刷盘。这么做主要是为了减少刷盘对业务带来的影响,实现平滑系统负载的目的
(2)MemStore达到上限
当MemStore的大小达到hbase.hregion.memstore.flush.size大小的时候会触发刷盘,默认128M大小
(3)RegionServer的HLog数量达到上限
前面说到Hlog为了保证Hbase数据的一致性,那么如果Hlog太多的话,会导致故障恢复的时间太长,因此Hbase会对Hlog的最大个数做限制。当达到Hlog的最大个数的时候,会强制刷盘。这个参数是hase.regionserver.max.logs,默认是32个。
(4)手工触发
可以通过hbase shell或者java api手工触发flush的操作。
(5)关闭RegionServer触发
在正常关闭RegionServer会触发刷盘的操作,全部数据刷盘后就不需要再使用Hlog恢复数据。
(6)Region使用HLOG恢复完数据后触发
当RegionServer出现故障的时候,其上面的Region会迁移到其他正常的RegionServer上,在恢复完Region的数据后,会触发刷盘,当刷盘完成后才会提供给业务访问。
4、Region深入了解
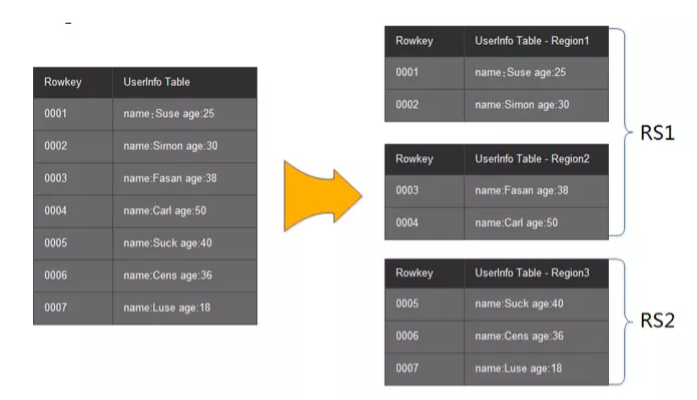
4.1 Region实例
Region是HBase中类似关系型数据库中分区和分片的概念,一个Region负责一小部分RowKey范围的读写。HMaster将对应的Region分配到不同的HRegionServer中。有HRegionServer来提供Region的读写和 相关的管理工作。
下图简单描述:
 4.2 Region的寻址方式
4.2 Region的寻址方式HBase的读写的第一步都需要在Meta表中找到所读写的数据所在RegionServer,Region的寻址方式具体是?
(1)旧的寻址方式
在Hbase0.96版本之前,Hbase有两个特殊的表 -ROOT-(-ROOT-表只有一个Region) 和 .META.(.META.表可被切分多个Region) ,-ROOT-的位置信息存储在Zookeeper中,.META表的Region地址信息存储在 -ROOT-表中

寻址步骤:
- Client请求Zookeeper,获得-ROOT-表所在的RegionServer地址
- Client请求-ROOT-所在的RegionServer,获取到.META表所在的RegionServer地址,Client会将-ROOT-相关的信息cache下来,以便下一次快速访问
- Client请求.META.所在RegionServer,获取到数据所在的RegionServer地址,Client会将.META相关的信息cache下来,以便下一次快速访问
- Client请求数据所在RegionServer,获取数据
(2)新的寻址方式
新的寻址方式去掉了-ROOT-表
去掉-ROOT-表的原因:2层结构足够满足集群的需求,提高性能

寻址步骤:
- Client请求Zookeeper,获取到.META.表所在的RegionServer地址,Client会将 .META相关的信息cache下来,以便下一次快速访问
- Client请求.META所在RegionServer,获取到数据所在的RegionServer地址,Client会将.META相关的信息cache下来,以便下一次快速访问
- Client请求数据所在RegionServer,获取数据
Client cache更新问题
这里还有一个问题需要说明,那就是Client会缓存.META.的数据,用来加快访问,既然有缓存,那它什么时候更新?如果.META.更新了,比如Region1不在RerverServer2上了,被转移到了RerverServer3上。client的缓存没有更新会有什么情况?
其实,Client的元数据缓存不更新,当.META.的数据发生更新。如上面的例子,由于Region1的位置发生了变化,Client再次根据缓存去访问的时候,会出现错误,当出现异常达到重试次数后就会去.META.所在的RegionServer获取最新的数据,如果.META.所在的RegionServer也变了,Client就会去ZK上获取.META.所在的RegionServer的最新地址。
4.3 Region的拆分和合并
4.3.1 Region的拆分
Hbase Region的拆分策略
Hbase Region的拆分策略有比较多,比如除了3种默认过的策略,还有DelimitedKeyPrefixRegionSplitPolicy、KeyPrefixRegionSplitPolicy、DisableSplitPolicy等策略,这里只介绍3种默认的策略。分别是ConstantSizeRegionSplitPolicy策略、IncreasingToUpperBoundRegionSplitPolicy策略和SteppingSplitPolicy策略。
ConstantSizeRegionSplitPolicy
ConstantSizeRegionSplitPolicy策略是0.94版本之前的默认拆分策略,这个策略的拆分规则是:当region大小达到hbase.hregion.max.filesize(默认10G)后拆分。这种拆分策略对于小表不太友好,按照默认的设置,如果1个表的Hfile小于10G就一直不会拆分。注意10G是压缩后的大小,如果使用了压缩的话。如果1个表一直不拆分,访问量小也不会有问题,但是如果这个表访问量比较大的话,就比较容易出现性能问题。这个时候只能手工进行拆分。还是很不方便。
IncreasingToUpperBoundRegionSplitPolicy
IncreasingToUpperBoundRegionSplitPolicy策略是Hbase的0.94~2.0版本默认的拆分策略,这个策略相较于ConstantSizeRegionSplitPolicy策略做了一些优化,该策略的算法为:min(r^2*flushSize,maxFileSize ),最大为maxFileSize 。
从这个算是我们可以得出flushsize为128M、maxFileSize为10G的情况下,可以计算出Region的分裂情况如下:
第一次拆分大小为:min(10G,1*1*128M)=128M
第二次拆分大小为:min(10G,3*3*128M)=1152M
第三次拆分大小为:min(10G,5*5*128M)=3200M
第四次拆分大小为:min(10G,7*7*128M)=6272M
第五次拆分大小为:min(10G,9*9*128M)=10G
第五次拆分大小为:min(10G,11*11*128M)=10G
从上面的计算我们可以看到这种策略能够自适应大表和小表,但是这种策略会导致小表产生比较多的小region,对于小表还是不是很完美。
SteppingSplitPolicy
SteppingSplitPolicy是在Hbase 2.0版本后的默认策略,拆分规则为:If region=1 then: flush size * 2 else: MaxRegionFileSize。
还是以flushsize为128M、maxFileSize为10G场景为列,计算出Region的分裂情况如下:
第一次拆分大小为:2*128M=256M
第二次拆分大小为:10G
从上面的计算我们可以看出,这种策略兼顾了ConstantSizeRegionSplitPolicy策略和IncreasingToUpperBoundRegionSplitPolicy策略,对于小表也肯呢个比较好的适配。
Region的拆分流程
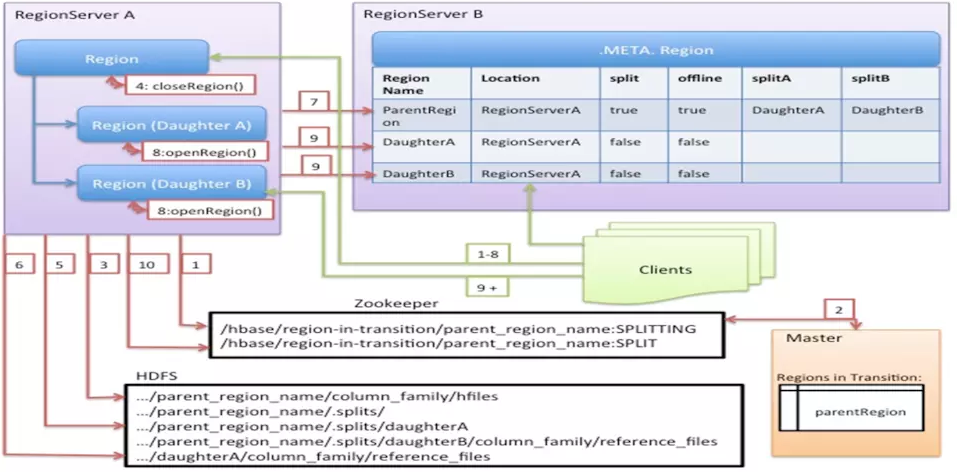
第1步会ZK的/hbase/region-in-transition/region-name下创建一个znode,并设置状态为SPLITTING
第2步master通过watch节点检测到Region状态的变化,并修改内存中Region状态的变化
第3步RegionServer在父Region的目录下创建一个名称为.splits的子目录
第4步RegionServer关闭父Region,强制将数据刷新到磁盘,并这个Region标记为offline的状态。此时,落到这个Region的请求都会返回NotServingRegionException这个错误
第5步RegionServer在.splits创建daughterA和daughterB,并在文件夹中创建对应的reference文件,指向父Region的Region文件
第6步RegionServer在HDFS中创建daughterA和daughterB的Region目录,并将reference文件移动到对应的Region目录中
第7步在.META.表中设置父Region为offline状态,不再提供服务,并将父Region的daughterA和daughterB的Region添加到.META.表中,已表名父Region被拆分成了daughterA和daughterB两个Region
第8步RegionServer并行开启两个子Region,并正式提供对外写服务
第9步RegionSever将daughterA和daughterB添加到.META.表中,这样就可以从.META.找到子Region,并可以对子Region进行访问了
第10步RegionServr修改/hbase/region-in-transition/region-name的znode的状态为SPLIT
备注:为了减少对业务的影响,Region的拆分并不涉及到数据迁移的操作,而只是创建了对父Region的指向。只有在做大合并的时候,才会将数据进行迁移。
通过reference文件如何才能查找到对应的数据
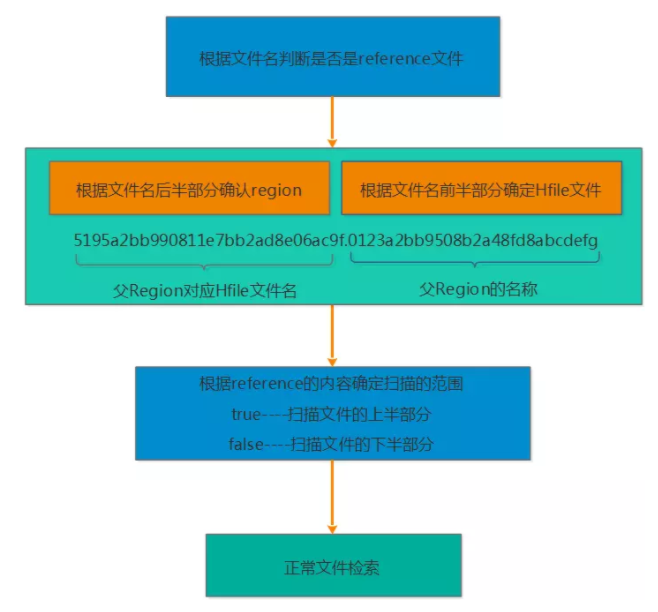
根据文件名来判断是否是reference文件
由于reference文件的命名规则为前半部分为父Region对应的File的文件名,后半部分是父Region的名称,因此读取的时候也根据前半部分和后半部分来识别
根据reference文件的内容来确定扫描的范围,reference的内容包含两部分,一部分是切分点splitkey,另一部分是boolean类型的变量(true或者false)。如果为true则扫描文件的上半部分,false则扫描文件的下半部分
接下来确定了扫描的文件,以及文件的扫描范围,那就按照正常的文件检索了
4.3.2 Region的合并
1、小合并(MinorCompaction)
由前面的刷盘部分的介绍,我们知道当MemStore达到hbase.hregion.memstore.flush.size大小的时候会将数据刷到磁盘,生产StoreFile,因此势必产生很多的小问题,对于Hbase的读取,如果要扫描大量的小文件,会导致性能很差,因此需要将这些小文件合并成大一点的文件。因此所谓的小合并,就是把多个小的StoreFile组合在一起,形成一个较大的StoreFile,通常是累积到3个Store File后执行。通过参数hbase.hstore,compactionThreadhold配置。小合并的大致步骤为:
分别读取出待合并的StoreFile文件的KeyValues,并顺序地写入到位于./tmp目录下的临时文件中
将临时文件移动到对应的Region目录中
将合并的输入文件路径和输出路径封装成KeyValues写入WAL日志,并打上compaction标记,最后强制自行sync
将对应region数据目录下的合并的输入文件全部删除,合并完成
这种小合并一般速度很快,对业务的影响也比较小。本质上,小合并就是使用短时间的IO消耗以及带宽消耗换取后续查询的低延迟。
2、大合并(MajorCompaction)
所谓的大合并,就是将一个Region下的所有StoreFile合并成一个StoreFile文件,在大合并的过程中,之前删除的行和过期的版本都会被删除,拆分的母Region的数据也会迁移到拆分后的子Region上。大合并一般一周做一次,控制参数为hbase.hregion.majorcompaction。大合并的影响一般比较大,尽量避免统一时间多个Region进行合并,因此Hbase通过一些参数来进行控制,用于防止多个Region同时进行大合并。该参数为:hbase.hregion.majorcompaction.jitter
具体算法为:
hbase.hregion.majorcompaction参数的值乘于一个随机分数,这个随机分数不能超过hbase.hregion.majorcompaction.jitter的值。hbase.hregion.majorcompaction.jitter的值默认为0.5。
通过hbase.hregion.majorcompaction参数的值加上或减去hbase.hregion.majorcompaction参数的值乘于一个随机分数的值就确定下一次大合并的时间区间。
用户如果想禁用major compaction,只需要将参数hbase.hregion.majorcompaction设为0。建议禁用。
5、HLog深入了解
HLog的功能就是保证数据的安全性,在RegionServer发生异常的时候,可以根据HLog来恢复数据。(HLog存储在HDFS上)
HLog是一个实现了WAL(Write ahead Log)的方式产生日志信息,内部是一个简单的顺序日志。每个RegionServer对应一个HLog(1.x版本可以开启MultiWAL功能,允许多个HLog)
所有对于该RegionServer的写入操作都会记录的到HLog中,Hbase为了保证恢复的效率,会限制HLog的数量,默认是32个,通过参数( hase.regionserver.max.logs)控制,达到最大数据之后会强制刷盘。
已经刷盘过得数据,对应的HLog有过期的概念,HLog过期后会被监控线程移动到.oldlogs( hbase.master.logcleaner.ttl 设置保留的最长时间),然后会自动删除掉。
5.1 HLog结构

(1)多个Region共享一个HLog,单个Region的日志记录在HLog是顺序的,但是多个Region之间的是没有顺序
(2)HLog的最小单元由 HLogKey 和 WALEdit构成。
HLogKey组成部分:sequenceid、write time、cluster ids、region name、table name
WALEdit组成部分:是由一系列的KeyValue组成,是一行上所有列的更新操作。
sequenceid
sequenceid是store级别的自增序列号,是利用HLog进行数据恢复和HLog定期删除的重要部分,MemStore达到一定条件之后进行刷盘操作,刷盘的时候会获取到刷新到最新的sequenceid的下一个sequenceid,并将新的sequenceid赋值给oldestUnflushedSequeuedid,并刷新到Ffile中。(oldestUnflushedSequeuedid 和 HLog最大的sequenceid进行比较判断是否过期,以及判断sequenceid小于oldestUnflushedSequeuedid的数据需要恢复)
5.1 HLog生命周期
- 产生
- 滚动
- 过期
- 删除
产生:Hbase的所有写入(更新)操作都会产生HLog,除非关闭了HLog
滚动:为了控制单个HLog文件过大,方便后续的过期和删除,Hbase实现HLog滚动, hbase.regionserver.logroll.period参数设置滚动周期,默认是1小时,达到设置的时间时,会创建一个新的HLog日志, hbase.regionserver.max.logs 参数控制HLog的最大个数
过期:Hlog的过期依赖于对sequenceid的判断。Hbase会将Hlog的sequenceid和Hfile最大的sequenceid(刷新到的最新位置)进行比较,如果该Hlog文件中的sequenceid比刷新的最新位置的sequenceid都要 小,那么这个Hlog就过期了,过期了以后,对应Hlog会被移动到.oldlogs目录
删除:如果Hbase开启了replication,当replication执行完一个Hlog的时候,会删除Zoopkeeper上的对应Hlog节点。在Hlog被移动到.oldlogs目录后,Hbase每隔hbase.master.cleaner.interval(默认60秒)时间会去检查.oldlogs目录下的所有Hlog,确认对应的Zookeeper的Hlog节点是否被删除,如果Zookeeper 上不存在对应的Hlog节点,那么就直接删除对应的Hlog。hbase.master.logcleaner.ttl(默认10分钟)这个参数设置Hlog在.oldlogs目录保留的最长时间
6、RegionServer的故障恢复
RegionServer的相关信息保存在Zookeeper中,当RegionServer启动的时候,会在Zookeeper中创建一个临时节点,RegionServer通过Socket与Zookeeper建立session会话,RegionServer会定期的向Zookeeper发送ping消息包,说明自己还处于存活状态,Zookeeper接收ping包后,更新对应的session的过期时间。当Zookeeper在超过session过期时间还未接收到RegionServer的过期时间,则会认为RegionServer发生了故障,Zookeeper会删除该RegionServer的临时节点,并且通知HMaster,HMaster接收到消息后启动数据恢复过程。
恢复流程:
RegionServer发生故障 -> Zookeeper检测到RegionServer异常(删除临时节点并且通知HMaster) -> Master启动数据恢复 -> HLog切分 -> RegionServer重新分配(Master重新分配)-> HLog重放 -> 恢复完成并提供服务
故障恢复的模式有三种:
- Log Splitting
- Distributed Log Splitting
- Distributed Log Replay
Log Splitting
Log切分是有Master来执行
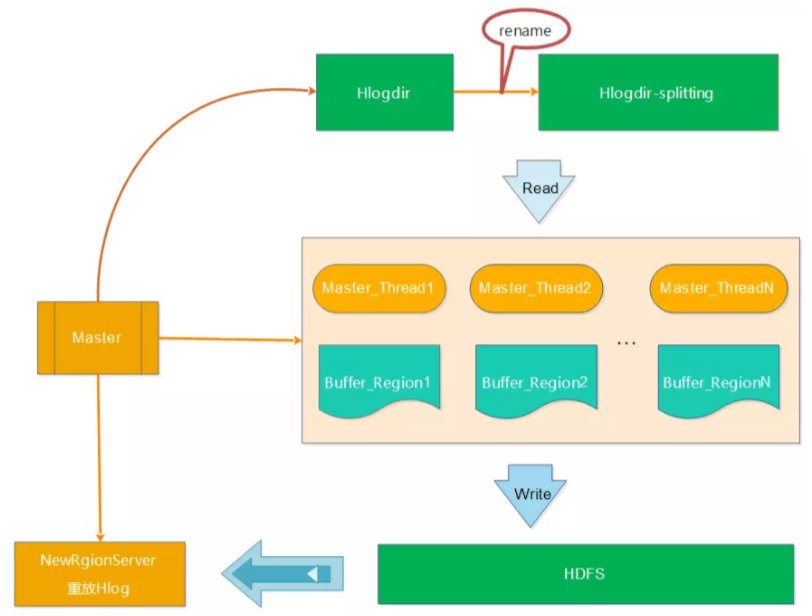
步骤:
(1)将带切分的HLog文件重命名,防止RegionServer未真正宕机而持续写入HLog
(2)HMaster启动读取线程读取Hlog,将RegionServer的日志写入到不同的内存Buffer中
(3)HMaster启动写入线程,将不同的内存Buffer中的日志写入到HDFS中(路径 /hbase/table_name/region/recoverd.edits/.tmp)
(4)HMaster重新将宕机的RegionServer中的Region重新分配到新的RegionServer中,新的RegionServer读取Region的数据 ( 会发现该region目录下的recoverd.edits目录以及相关的日志,然后RegionServer重放对应的Hlog日志,从而实现对应Region数据的恢复)
缺点:HLog切分只有Master节点在执行,效率比较低
Distributed Log Splitting
分布式Hlog切分,分布式切分是充分利用RegionServer的各个资源,利用多个RegionServer来切分HLog文件

步骤:
(1)Master将要切分的HLog文件发布到Zookeeper节点上(/Hbase/splitAWL),每个日志一个任务,任务的最初状态为TASK_UNASSIGNED
(2)在Master发布Hlog任务后,RegionServer会采用竞争方式认领对应的任务(先查看任务的状态,如果是TASK_UNASSIGNED,就将该任务状态修改为TASK_OWNED)
(3)RegionServer取得任务后会让对应的HLogSplitter线程处理Hlog的切分,切分的时候读取出Hlog的对,然后写入不通的Region buffer的内存中。
(4)RegionServer启动对应写线程,将Region buffer的数据写入到HDFS中,路径为/hbase/table/region/seqenceid.temp,seqenceid是一个日志中该Region对应的最大sequenceid,如果日志切分成功,而RegionServer会将对应的ZK节点的任务修改为TASK_DONE,如果切分失败,则会将任务修改为TASK_ERR
(5)如果任务是TASK_ERR状态,则Master会重新发布该任务,继续由RegionServer竞争任务,并做切分处理
(6)Master重新将宕机的RegionServer中的Rgion分配到正常的RegionServer中,对应的RegionServer读取Region的数据,将该region目录下的一系列的seqenceid.temp进行从小到大进行重放,从而实现对应 Region数据的恢复。
弊端:
使用多台RegionServer做Hlog的切分工作,确实能提高效率。正常故障恢复可以降低到分钟级别。但是这种方式有个弊端是会产生很多小文件(切分的Hlog数 * 宕机的RegionServer上的Region数)。比如一个RegionServer有20个Region,有50个Hlog,那么产生的小文件数量为20*50=1000个。如果集群中有多台RegionServer宕机的情况,小文件更是会成倍增加,恢复的过程还是会比较慢。
Distributed Log Replay
Distributed Log Replay和Distributed Log Splitting的不同是先将宕机RegionServer上的Region分配给正常的RgionServer,并将该Region标记为recovering。再使用Distributed Log Splitting类似的方式进行Hlog切分,不同的是,RegionServer将Hlog切分到对应Region buffer后,并不写HDFS,而是直接进行重放。这样可以减少将大量的文件写入HDFS中,大大减少了HDFS的IO消耗

7、HBase命令
HBase提供了一个shell终端给用户交互
创建表:create '表名','列族名1','列族名2'...
查看所有表:list
描述表:describe '表名'
判断表是否存在:exsit '表名'
判断是否禁用启用表: is enabled '表名'
is disabled '表名'
添加记录:put '表名','rowkey','列族:列','值'
查看rowkey下的所有数据:get '表名','rowkey'
查看表中的记录数:count '表名'
获取某个列族:get '表名','rowkey','列族'
获取某个列族的某列:get '表名','rowkey','列族:列'
删除记录:delete '表名','rowkey','列族:列'
删除整行:deleteall '表名','rowkey'
删除一张表:第一步 disable ‘表名’ ,第二步 drop '表名'
清空表:truncate '表名'(过程是:disable表->删除表->创建表)
查看所有记录:scan '表名'
查看某个表某个列中所有数据:scan "表名" , {COLUMNS=>'列族名:列名'}
参考:https://www.cnblogs.com/qcloud1001/p/7615526.html
https://www.jianshu.com/p/e2bbf23f1ba2