Python学习手册之数据类型
在上一篇文章中,我们介绍了 Python 的异常和文件,现在我们介绍 Python 中的数据类型。
查看上一篇文章请点击:https://www.cnblogs.com/dustman/p/9979931.html
数据类型
None 类型
None 类型是 Python 的特殊类型,它是 NoneType 的对象类型,表示无值。该对象只有一个值 None。其它语言使用 null 来表示这个对象。
它不支持任何运算也没有任何内建方法。作为一个对象其布尔值为 False。除了和自己比较,None 和任何其他的数据类型比较永远返回 False。
>>> None == True
False
>>> None
>>> print(None)
None
>>> None == None
True
>>>
如果函数没有清楚地声明返回值,则返回 None 对象。
def func():
print("I like Python!")
temp = func()
print(temp)
运行结果:
>>>
I like Python!
None
>>>
字典
字典(Dictionaries)是 Python 中一个非常有用的内置数据类型。它不像列表一样通过数字索引来访问,字典当中的元素是通过键来存取。
字典是一个映射类型,在其它语言中被称为 map。字典用 {} 来标识,使用键 : 值 (key : value) 存储,具有极快的查找速度,使用 [] 语法来访问。
sex = {"John":"F","Amy":"M","Echo":"F"}
print(sex["Amy"])
print(sex["John"])
运行结果:
>>>
M
F
>>>
访问不存在字典里的键值会导致 KeyError 异常。
msg = {
"name":"John",
"sex":"M",
"age":10,
}
print(msg["name"])
print(msg["age"])
print(msg["son"])
运行结果:
>>>
John
10
KeyError: 'son'
>>>
实际上字典能够存储任何类型的数据。
字典为空时的表现形式为 {}
只有不可变的对象可以用作字典的 key,不可变的对象是指那些不能更改的对象。到目前为止,我们遇到的唯一可变对象是列表和字典。可变对象做键值会触发 TypeError 异常。
msg = {
['a','b','c']:"a to c"
}
运行结果:
>>>
TypeError: unhashable type: 'list'
>>>
正确使用字典非常重要,需要牢记字典的 key 必须是不可变对象。
字典方法
我们知道字典是可变对象,可以像列表一样,字典的键值存储的数值可以重新指派另外的值。
不同于列表的是,我们可以通过字典的键值存储数据,不管这个键存不存在字典里。
msg = {
"name":"John",
"sex":"M",
"age":10,
}
msg[2] = "Home"
msg[8] = "Job"
print(msg)
运行结果:
{'name': 'John', 'sex': 'M', 'age': 10, 2: 'Home', 8: 'Job'}
要在字典里确定一个键是否存在词典里,你可以使用 in 语法。
msg = {
"name":"John",
"sex":"M",
"age":10,
}
print("name" in msg)
print("job" in msg)
print("age" in msg)
运行结果:
>>>
True
False
True
>>>
我们还可以通过 get 的方法从字典里取数据,就像前面用 msg["name"] 这样的方法读取数据。与这种方法不同的是,当字典里没有该键值时 get 方法取回的值是 None,而不会触发 KeyError 异常。
msg = {
"name":"John",
"sex":"M",
"age":10,
"Job":False,
}
print(msg.get("name"))
print(msg.get(6))
print(msg.get(123,"Not in dictionary!"))
运行结果:
>>>
John
None
Not in dictionary!
>>>
我们还可以指定 get 方法的第二个参数,当键值在字典里不存在是会返回我们所指定的值。
下面代码运行结果是什么?
msg = {
1:1,2:1,3:2,4:3,
}
print(msg.get(2,0) + msg.get(8,3))
运行结果:
>>>
4
>>>
元组
元组 (Tuples) 跟列表很像,但是元组不能提供列表类能够提供给你的很多功能。元组的一大特征就是不可变。
元组使用圆括号来创建。
msg = ("Hello","World","!",)
你可以像访问列表一样,通过索引来访问元组。
print(msg[1])
给元组的元素重新分配值会触发 TypeError 异常。
msg[0] = "Thank"
运行结果:
>>>
TypeError: 'tuple' object does not support item assignment
>>>
和列表字典一样,元组也能嵌套存储。
我们也可以不用圆括号就创建元组,通过逗号分割来确定元组的分组。
msg = "Hello","World","!"
print(msg[0])
运行结果:
>>>
Hello
>>>
空元祖必须通过圆括号创建。
empty = ()
尽管元组不能改变,但是运行速度快于列表。
列表切片
Python 为列表提供了高级特征切片 (Slice) 操作功能,大大弱化了获取一个列表区间的操作。切片操作通过两个索引数字中间用冒号分割来完成,返回从第一个数字索引到第二个数字索引的一个新列表。
msg = [0,1,2,3,4,5,14,28,32]
print(msg[2:5])
print(msg[0:1])
运行结果:
>>>
[2, 3, 4]
[0]
>>>
和 range 函数操作一样,包含第一个数字索引里的值,不包含第二个数字索引的值。
如果切片的第一个数字忽略,切片操作从 0 开始,如果切片的第二个数字缺失,切片操作直到列表尾部结束。
msg = [0,1,2,3,4,5,14,28,32]
print(msg[:5])
print(msg[5:])
运行结果:
>>>
[0, 1, 2, 3, 4]
[5, 14, 28, 32]
>>>
切片操作同样可以作用于元组。
列表切片操作同样可以提供第三个参数,这一参数将被视为切片的步长 (Step) ,在默认情况下,步长大小为 1、
msg = [0,1,2,3,4,5,14,28,32]
print(msg[:2])
print(msg[2:8:2])
运行结果:
>>>
[0, 1]
[2, 4, 14]
>>>
[2:8:2] 将会取出列表从索引 2 开始直到索引 8 并且每隔 2 个取一个列表的元素。
索引操作也可以使用负数,在这种情况下,位置计数将从列表的末尾开始。
msg = [0,1,2,3,4,5,14,28,32]
print(msg[1:-1])
运行结果:
>>>
[1, 2, 3, 4, 5, 14, 28]
>>>
如果步进使用负值,则切片操作将从后向前执行。
使用 [::-1] 切片是一种常见的方法来反转列表。
列表生成式
列表生成式即 List Comprehensions,是 Python 内置的非常强大却简单的可以用来创建列表的生成式。
# a list comprehension
cubes = [i**2 for i in range(5)]
print(cubes)
运行结果:
>>>
[0, 1, 4, 9, 16]
>>>
列表生成式同样可以包含 if 条件判断,一遍创建一个符合一定条件的列表。
cubes = [i**2 for i in range(5) if i**2 % 2 ==0]
print(cubes)
运行结果:
>>>
[0, 4, 16]
>>>
通过列表生成式生成一个非常大的列表会引发 MemoryError 异常。
even = [2*i for i in range(10**150)]
运行结果:
>>>
MemoryError
>>>
这个问题我们可以通过 迭代器 来解决这个问题,迭代器将会在下一篇文章中讲到。
字符串格式化
我们经常会输出劣势 '尊敬的客户,您尾号xx的账户向xx公司完成xx交易,余额xx'之类的字符串,而 xxx 的内容都是根据变量变化的。
所以,需要一种简便的格式化字符串的方式。String 对象提供了一个 format 方法。
# string formatting
nums = [1,2,3]
msg = "Numbers:{0} {1} {2}".format(nums[0],nums[1],nums[2])
print(msg)
运行结果:
>>>
Numbers:1 2 3
>>>
每一个参数对应字符串里相应的占位符 {}。使用数字的方式不仅可以交换参数的位置,甚至可以在字符串里面换位,比如 {5} 在最前面。
字符串格式化也可以用命名参数替换。
msg = "{a},{b}".format(a=5,b=15)
print(msg)
运行结果:
>>>
5,15
>>>
Python 还提供了另一种格式化的方法。这种格式化方式和 C 语言一致用 % 实现,举例如下:
s = 'Hello,%s' % 'Python'
print(s)
s = 'Hi,%s,you have $%d' % ('man',100)
print(s)
运行结果:
>>>
Hello,Python
Hi,man,you have $100
>>>
% 运算符就是用来格式化字符串的,下图是常见的占位符。
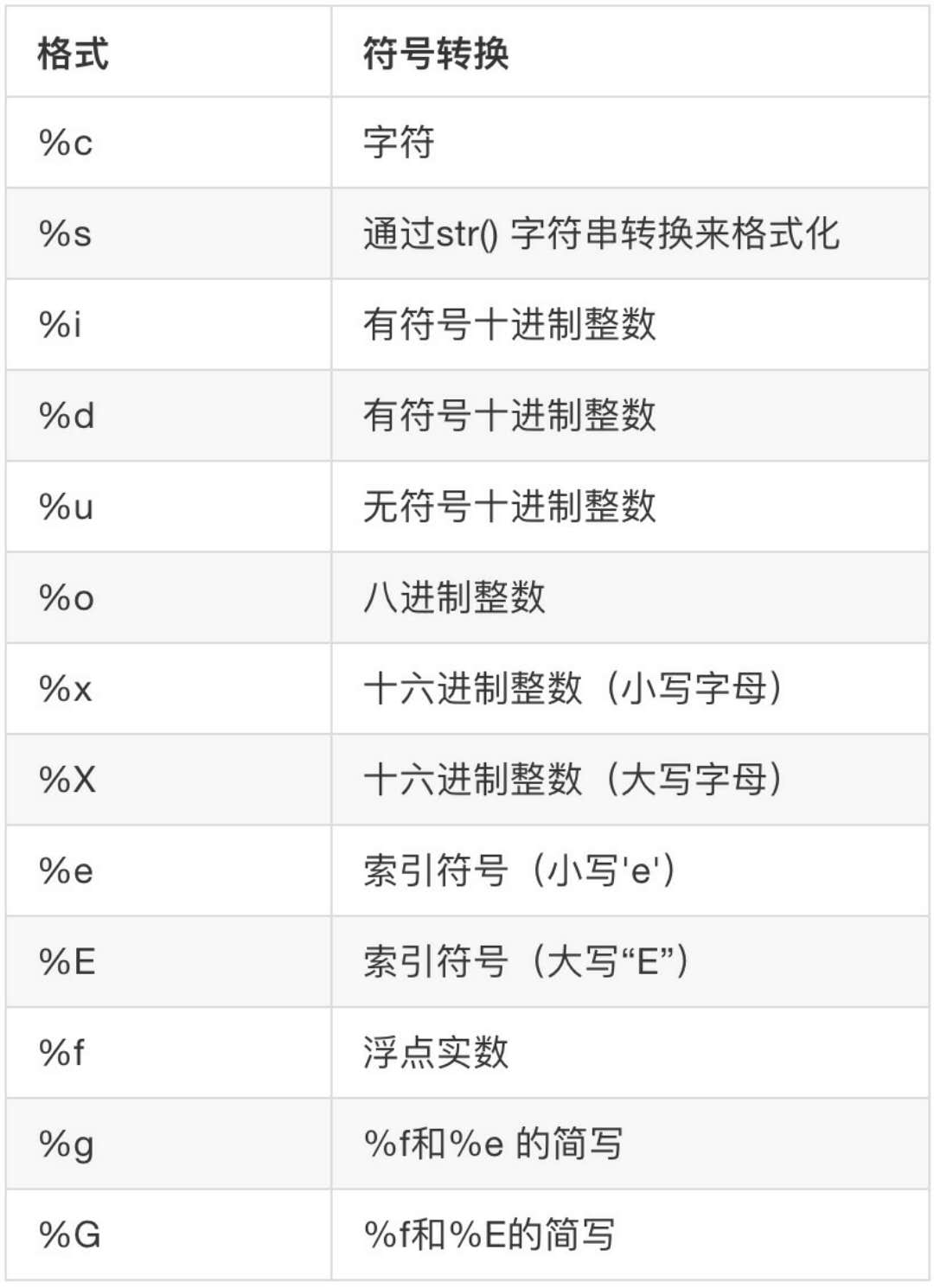
在字符串内部,%s 表示用字符串替换,%d表示用整数替换,有几个 %? 占位符,后面就跟几个变量或者值,顺序需要对应好。如果只有一个 %?,括号可以省略。
常用方法
字符串方法
Python 标准库内建一些常用的方法。
join - 用一个字符串作为分隔符连接字符串列表。
replace - 对字符串进行替换操作。
startswith - 字符串是否以另一个字符串开头。
endswith - 字符串是否以另一个字符串结束。
upper 和 lower - 返回字符串以大写或小写的形式。
split - 切割字符串为列表。
print(",".join(["man","and","boy"]))
print("Hello me".replace("me","world"))
print("This is a man".startswith("This"))
print("This is a woman".endswith("woman"))
print("this is a boy".upper())
print("THIS IS A GIRL".lower())
print("man,and,boy".split(","))
运行结果:
>>>
man,and,boy
Hello world
True
True
THIS IS A BOY
this is a girl
['man', 'and', 'boy']
>>>
数学方式
max 和 min - 查找一组数里最大和最小的值。
abs - 绝对值。
round - 四舍五入
sum - 数字列表里数字的总和。
print(max(9,8,7,4,5,2,1))
print(min(1,2,3,4,0,-5))
print(abs(-41))
print(abs(32))
print(sum([100,455,78,-584]))
运行结果:
>>>
9
-5
41
32
49
>>>
列表方法
标准库提供了一些非常有用的函数,all 和 any 函数为我们对列表进行条件判断提供了方便。函数 enumerate 也提供了另一种方式来遍历列表的方法。
nums = [14,51,48,46,11]
if all([i > 6 for i in nums]):
print("All larger than 6")
if any([i % 2 == 0 for i in nums]):
print("At least on is even")
for v in enumerate(nums):
print(v)
运行结果:
>>>
All larger than 6
At least on is even
(0, 14)
(1, 51)
(2, 48)
(3, 46)
(4, 11)
>>>
文本分析
现在我们来做学习一个文本分析的具体例子,我们来分析文本里每个字母出现的百分比。首先我们打开一个文件并读取内容。
filename = input("Enter a filename: ")
with open(filename) as f:
msg= f.read()
print(msg)
运行结果:
Enter a filename: test.txt
I like Python!!!!!
I like Python!!!!
I like Python!!!
I like Python!!
I like Python!
I like Python
下面代码用来统计一个字母出现在字符串的次数。
def count_char(test,char):
count = 0
for c in test:
if c == char:
count += 1
return count
这个函数接受两个参数,一个是字符串,一个是字母,返回字母出现在字符串的次数。现在我们可以打开文件调用它。
filename = input("Enter a filename: ")
with open(filename) as f:
msg= f.read()
print(count_char(msg,'P'))
运行结果:
>>>
Enter a filename: test.txt
6
>>>
字母 "P" 总共出现在文件里 6 次。
接下来就是统计每个字母出现在文件的百分比。
for char in "AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz":
percent = 100 * count_char(msg,char) / len(msg)
print("{0} - {1}%".format(char,round(percent,2)))
把所有的代码合并在一起运行。
def count_char(content,char):
count = 0
for c in content:
if c == char:
count += 1
return count filename = input("Enter a filename: ")
with open(filename) as f:
msg= f.read() print(count_char(msg, 'P'))
for char in "AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz":
percent = 100 * count_char(msg,char) / len(msg)
print("{0} - {1}%".format(char,round(percent,2)))
运行结果:
>>>
Enter a filename: test.txt
6
A - 0.0%
a - 0.0%
B - 0.0%
b - 0.0%
C - 0.0%
c - 0.0%
...
H - 0.0%
h - 6.0%
I - 6.0%
i - 6.0%
J - 0.0%
...
>>>
“今年的我们已与去年不同,我们的爱人亦是如此,如果变化中的我们依旧爱着那个变了的另一半,那是幸运所致。”
-- 毛姆(英国小说家/故事圣手)
Python学习手册之数据类型的更多相关文章
- [python学习手册-笔记]002.python核心数据类型
python核心数据类型 ❝ 本系列文章是我个人学习<python学习手册(第五版)>的学习笔记,其中大部分内容为该书的总结和个人理解,小部分内容为相关知识点的扩展. 非商业用途转载请注明 ...
- 《Python学习手册》(二)
<Python学习手册>(二) --类型和运算 数字 十六进制 八进制 二进制 0x 0o 0b hex() oct() bin() >>>int('10',2) 2 & ...
- 《Python学习手册 第五版》 -第10章 Python语句简介
前面在开始讲解数据类型的时候,有说过Python的知识结构,在此重温一下 Python知识结构: 程序由模块组成 模块包含语句 语句包含表达式 表达式创建并处理对象 关于知识结构,前面已经说过我自己的 ...
- 《Python学习手册 第五版》 -第16章 函数基础
前面的章节讲解的是一些基础数据类型.基本语句使用和一些文档查看的内容,这些都是一些基础,其实还谈不上入门,只有了解了函数,才算入门 函数是编程里面使用最多的也是最基本的程序结构, 本章重点内容 1.函 ...
- Python学习手册(第4版) - 专业程序员的养成完整版PDF免费下载_百度云盘
Python学习手册(第4版) - 专业程序员的养成完整版PDF免费下载_百度云盘 提取码:g7v1 作者简介 作为全球Python培训界的领军人物,<Python学习手册:第4版>作者M ...
- Python学习手册(第4版)PDF高清完整版免费下载|百度云盘
Python学习手册(第4版)PDF高清完整版免费下载|百度云盘 提取码:z6il 内容简介 Google和YouTube由于Python的高可适应性.易于维护以及适合于快速开发而采用它.如果你想要编 ...
- [python学习手册-笔记]003.数值类型
003.数值类型 ❝ 本系列文章是我个人学习<python学习手册(第五版)>的学习笔记,其中大部分内容为该书的总结和个人理解,小部分内容为相关知识点的扩展. 非商业用途转载请注明作者和出 ...
- [python学习手册-笔记]004.动态类型
004.动态类型 ❝ 本系列文章是我个人学习<python学习手册(第五版)>的学习笔记,其中大部分内容为该书的总结和个人理解,小部分内容为相关知识点的扩展. 非商业用途转载请注明作者和出 ...
- 《Python学习手册》读书笔记
之前为了编写一个svm分词的程序而简单学了下Python,觉得Python很好用,想深入并系统学习一下,了解一些机制,因此开始阅读<Python学习手册(第三版)>.如果只是想快速入门,我 ...
随机推荐
- Android 应用开发 之通过AsyncTask与ThreadPool(线程池)两种方式异步加载大量数据的分析与对比--转载
在加载大量数据的时候,经常会用到异步加载,所谓异步加载,就是把耗时的工作放到子线程里执行,当数据加载完毕的时候再到主线程进行UI刷新.在数据量非常大的情况下,我们通常会使用两种技术来进行异步加载,一 ...
- log4j2单独的配置与使用&log4j2+slf4j的结合的配置与使用
转载自:https://github.com/iamyong 一.log4j2单独的配置与使用 所用jar文件 log4j-api-2.8.2.jar log4j-core-2.8.2.jar 配置文 ...
- 【Leetcode】【Easy】Pascal's Triangle II
Given an index k, return the kth row of the Pascal's triangle. For example, given k = 3,Return [1,3, ...
- sudo cat > EOF权限问题
sudo bash -c 'cat << EOF > /etc/yum.repos.d/some-name.repo line1 line2 line3 EOF'
- oracle_How to Recover Data (Without a Backup!)
How to Recover Data (Without a Backup!) It's the classic career-limiting maneuver(职业限制机动): accidenta ...
- python27 文件读写
fileobject = open(文件的绝对路径或相对路径,读写模式,其他可选参数) '''r-读 文件不存在报错FileNotFoundError''' try: f = open('file0. ...
- Hibernate中一对多关联关系中的级联属性
如果想通过级联属性删除一端的数据和多端的数据要使用 void org.hibernate.Session.delete(Object arg0) 方法. getSession().delete(tea ...
- CSU-ACM2018暑假集训比赛1
A:https://www.cnblogs.com/yinbiao/p/9365127.html B:https://www.cnblogs.com/yinbiao/p/9365171.html C: ...
- 自己理解的数据库shcema
不懂就被人嘲笑呀 ,你还不知道怎么说. 从定义中我们可以看出schema为数据库对象的集合,为了区分各个集合,我们需要给这个集合起个名字,这些名字就是我们在企业管理器的方案下看到的许多类似用户名的节点 ...
- css3响应式布局设计——回顾
响应式设计是在不同设备下分辨率不同显示的样式就不同. media 属性用于为不同的媒体类型规定不同的样式.根绝浏览器的宽度和高度重新渲染页面. 语法: @media mediatype and | n ...