Hadoop(3)-Hadoop介绍
Hadoop三大发行版本
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。
Hortonworks文档较好。
1. Apache Hadoop
官网地址:http://hadoop.apache.org/releases.html
下载地址:https://archive.apache.org/dist/hadoop/common/
2. Cloudera Hadoop
官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
(1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
(2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
(3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
(4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
(5)Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
3. Hortonworks Hadoop
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
(1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
(2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
(3)雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
(4)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
(5)HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
(6)Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的Microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
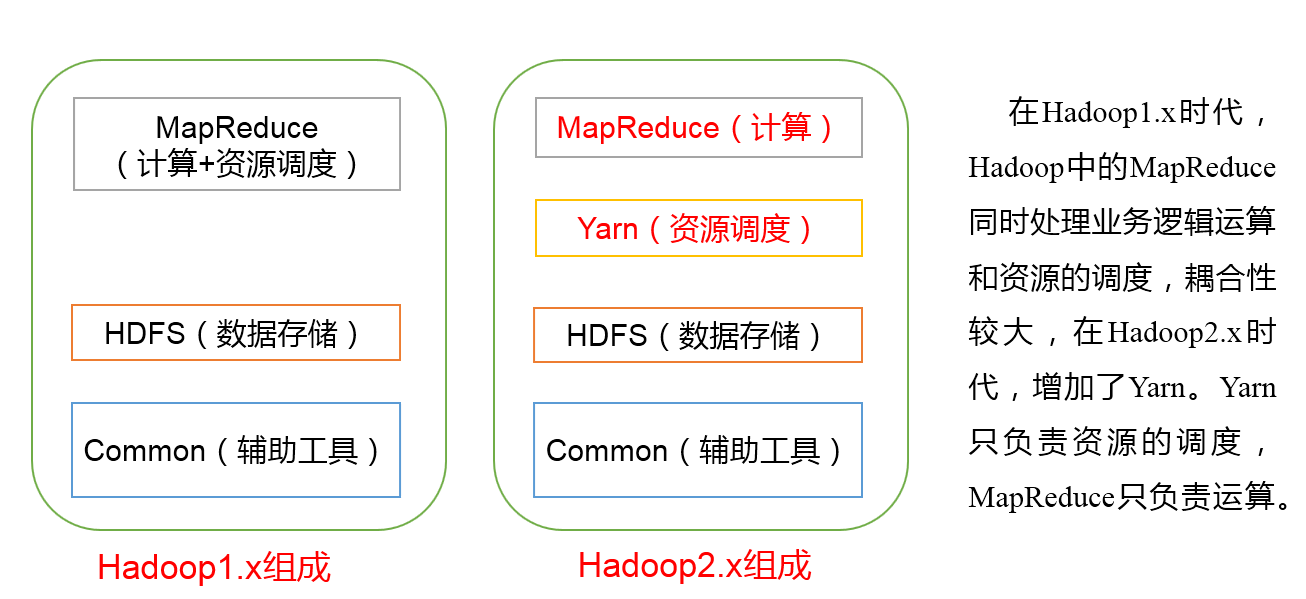
Hadoop1.x 和 Hadoop2.x的区别
HDFS架构概述

简单来说,NameNode是目录,DataNode是数据,Secondary NameNode是NameNode的助手
YARN架构概述
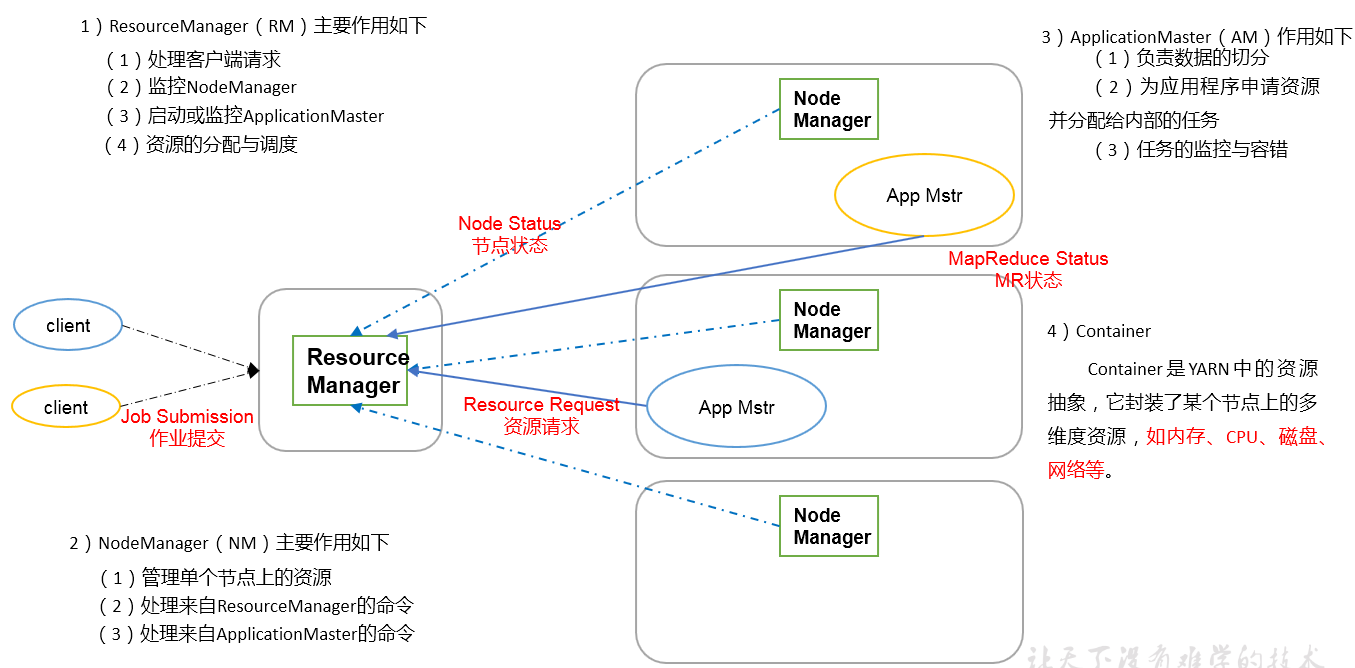
举例来说,ResourceManager为技术组长,NodeManager为组员,来了项目之后技术组长会临时组织一个小组来开发这个项目,同时又会在小组中临时指派一个小组长,小组长就是ApplicationMaster
ResourceManager和NodeManager一直 存在,而ApplicationMaster和Container则是跟着job而定
MapReduce架构概述
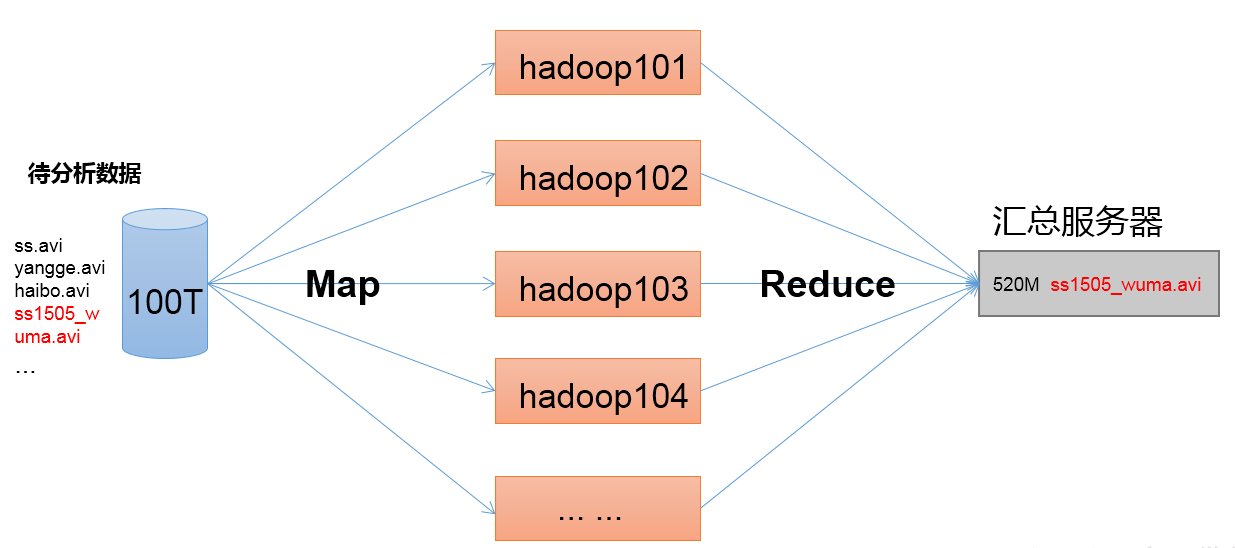
Map的工作是搜索计算,Reduce的工作是汇总和输出结果
大数据生态体系介绍
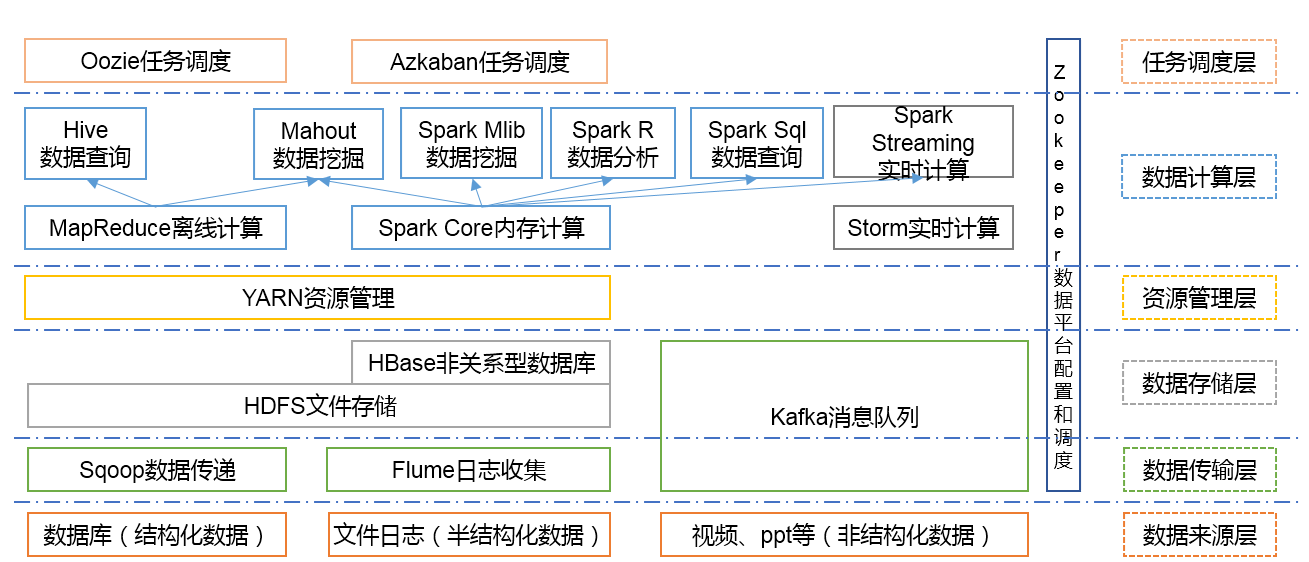
1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2)Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
(1)通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
(2)高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
(3)支持通过Kafka服务器和消费机集群来分区消息。
(4)支持Hadoop并行数据加载。
4)Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。如今已被Flink替代
5)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
6)Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
10)R语言:R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
11)Mahout:Apache Mahout是个可扩展的机器学习和数据挖掘库。
12)ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
Hadoop(3)-Hadoop介绍的更多相关文章
- Hadoop发行版本介绍
前言 从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘.开源界及厂商,所有数据软件,无一不向Hadoop靠拢.Hadoop也从小众的高富帅领域 ...
- Hadoop生态圈-hbase介绍-完全分布式搭建
Hadoop生态圈-hbase介绍-完全分布式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- 大数据之路week06--day07(Hadoop生态圈的介绍)
Hadoop 基本概念 一.Hadoop出现的前提环境 随着数据量的增大带来了以下的问题 (1)如何存储大量的数据? (2)怎么处理这些数据? (3)怎样的高效的分析这些数据? (4)在数据增长的情况 ...
- hadoop(1)---hadoop的介绍和几种模式。
一.什么是hadoop? Hadoop软件库是一个开源框架,允许使用简单的编程模型跨计算机集群分布式处理大型数据集.它旨在从单个服务器扩展到数千台计算机,每台计算机都提供本地计算和存储.库本身不是依靠 ...
- Hadoop以及组件介绍
一.背景介绍 在接触过大数据相关项目的时候常常都会听到Hadoop这个东西,简单来说,他是一个用分布式计算来处理大数据的开源软件,下面包含了许多的组件和子项目,这篇文章将会介绍Hadoop的原理以及一 ...
- 大数据及hadoop相关知识介绍
一.大数据的基本概念 1.1什么是大数据 互联网企业是最早收集大数据的行业,最典型的代表就是Google和百度,这两个公司是做搜索引擎的,数量都非常庞大,每天都要去把互联网上的各种各样的网页信息抓取下 ...
- Hadoop: Hadoop Cluster配置文件
Hadoop配置文件 Hadoop的配置文件: 只读的默认配置文件:core-default.xml, hdfs-default.xml, yarn-default.xml 和 mapred-defa ...
- [Hadoop 周边] Hadoop和大数据:60款顶级大数据开源工具(2015-10-27)【转】
说到处理大数据的工具,普通的开源解决方案(尤其是Apache Hadoop)堪称中流砥柱.弗雷斯特调研公司的分析师Mike Gualtieri最近预测,在接下来几年,“100%的大公司”会采用Hado ...
- 【云计算 Hadoop】Hadoop 版本 生态圈 MapReduce模型
忘的差不多了, 先补概念, 然后开始搭建集群实战 ... . 一 Hadoop版本 和 生态圈 1. Hadoop版本 (1) Apache Hadoop版本介绍 Apache的开源项目开发流程 : ...
随机推荐
- 【Leetcode】【Easy】Minimum Depth of Binary Tree
Given a binary tree, find its minimum depth. The minimum depth is the number of nodes along the shor ...
- Ext,合计保留两位小数
1. features: [{ ftype: 'summary', dock: 'bottom' }], 2. summaryType: function(records){ return '合计'; ...
- 一张图看懂微软Power BI系列组件
一.Power BI简介 Power BI是微软最新的商业智能(BI)概念,它包含了一系列的组件和工具.话不多说,直接上图吧: Power BI的核心理念就是让我们用户不需要强大的技术背景,只需要掌握 ...
- 通过一个实际例子理解Kubernetes里pod的自动scale - 水平自动伸缩
kubectl scale命令用于程序在负载加重或缩小时进行pod扩容或缩小,我们通过一些实际例子来观察scale命令到底能达到什么效果. 命令行创建一个deployment: kubectl run ...
- windows 网络通讯模型Overlapped (转)(未看)
https://blog.csdn.net/jofranks/article/details/7895316 https://blog.csdn.net/caoshiying/article/deta ...
- iText生成PDF 格式报表
1.导包 <dependency> <groupId>com.lowagie</groupId> <artifactId>itext</artif ...
- transform,animate
1.transform 用来定义变换 IE10及以上支持 示例:transform: rotate | scale | skew | translate |matrix; 一.旋转rotate 正数 ...
- 【luogu P1456 Monkey King】 题解
题目链接:https://www.luogu.org/problemnew/show/P1456 左偏树并查集不加路径压缩吧... #include <cstdio> #include & ...
- 【题解】POJ 2115 C Looooops (Exgcd)
POJ 2115:http://poj.org/problem?id=2115 思路 设循环T次 则要满足A≡(B+CT)(mod 2k) 可得 A=B+CT+m*2k 移项得C*T+2k*m=B-A ...
- 【其它】Nook HD刷机
很久以前的 Nook HD 平板刷机.只能用 microSD(TF)卡刷.需要的软件全都保存在了自己的百度网盘,自己亲测有效. 一.准备工作 1.首先,将tf卡格式化为fat32格式,实测可以使用.将 ...