关于在scrapy中使用xpath
1. 还是以虎嗅为例,他给我返回的是一个json格式的json串

2.那么我需要操作的就是把json串转换成我们的字典格式再进行操作
str=json.loads(response.body)['data'] #这边是拿到响应体数据,然后进行序列化成字典,拿到字典中key为data的的值.是一个字符串
3.自己导入选择器
from scrapy.selector import Selector
4.使用Selector的xpath方法获取内容
result = Selector(text=你从json提取出来的str).xpath('你的xpath表达式').extract()
5.使用效果
我把上一篇虎嗅的在parse中修改了来示范一下
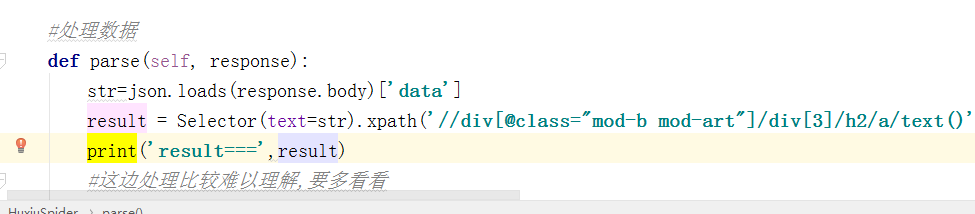
#处理数据
def parse(self, response):
str=json.loads(response.body)['data']
result = Selector(text=str).xpath('//div[@class="mod-b mod-art"]/div[3]/h2/a/text()').extract()
print('result===',result)
#这边处理比较难以理解,要多看看

5.文档
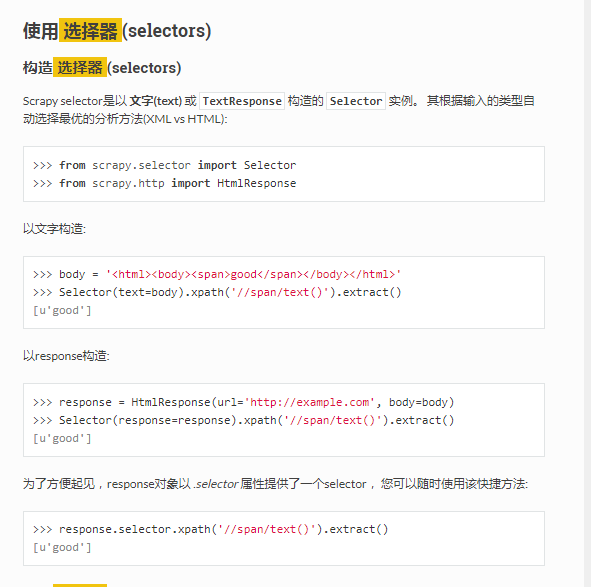
当输入 response.selector 时, 您将获取到一个可以用于查询返回数据的selector(选择器),
以及映射到 response.selector.xpath() 、 response.selector.css() 的
快捷方法(shortcut): response.xpath() 和 response.css() 。
关于在scrapy中使用xpath的更多相关文章
- [ 转 ] scrapy 中解决 xpath 中的中文编码问题
1.问题描述: 实现定位<h2>品牌</h2>节点 brand_tag = sel.xpath("//h2[text()= '品牌']") 报错:Value ...
- scrapy中的xpath用法和css的用法
css 不包含那个类 response.css(".list-left dd:not(.page)") 获取属性和文本 img.css("a::text").e ...
- 使用scrapy中xpath选择器的一个坑点
情景如下: 一个网页下有一个ul,这个ur下有125个li标签,每个li标签下有我们想要的 url 字段(每个 url 是唯一的)和 price 字段,我们现在要访问每个li下的url并在生成的请求中 ...
- 在Scrapy中如何利用Xpath选择器从HTML中提取目标信息(两种方式)
前一阵子我们介绍了如何启动Scrapy项目以及关于Scrapy爬虫的一些小技巧介绍,没来得及上车的小伙伴可以戳这些文章: 手把手教你如何新建scrapy爬虫框架的第一个项目(上) 手把手教你如何新建s ...
- python的scrapy框架的使用 和xpath的使用 && scrapy中request和response的函数参数 && parse()函数运行机制
这篇博客主要是讲一下scrapy框架的使用,对于糗事百科爬取数据并未去专门处理 最后爬取的数据保存为json格式 一.先说一下pyharm怎么去看一些函数在源码中的代码实现 按着ctrl然后点击函数就 ...
- 论Scrapy中的数据持久化
引入 Scrapy的数据持久化,主要包括存储到数据库.文件以及内置数据存储. 那我们今天就来讲讲如何把Scrapy中的数据存储到数据库和文件当中. 终端指令存储 保证爬虫文件的parse方法中有可迭代 ...
- scrapy中对于item的把控
其实很简单,就是想要存储的位置发生改变.直接看例子,然后触类旁通. 以大众点评 评论的内容为例 ,位置:http://www.dianping.com/shop/77489519/review_mor ...
- 15,scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生如果直接用scrapy对其url发请求,是获取不到那部分动态加载出来的数据值,但是通过观察会发现,通过浏览器 ...
- scrapy中的selenium
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
随机推荐
- ByteUnit
JDK里面有TimeUnit,看spark源码有个ByteUnit.这个类还是挺不错的. public enum ByteUnit { BYTE (1), KiB (1024L), MiB ((lon ...
- [.net 多线程]ThreadPool的安全机制
ThreadPool类,有两个方法我们没有用到,UnsafeQueueUserWorkItem 和UnsafeRegisterWaitForSingleObject. 为了完全理解这些方法,首先,我们 ...
- Win7 WPF程序无法接受外部拖拽
最近在WPF项目中遇到一个问题.虽然选择了AllowDrop = True,但是还是无法支持从外部拖拽文件到程序,倒是内部拖拽(如从一个列表拖拽到树)和从程序拖拽到外部可以. 解决过程 1.考虑是程序 ...
- 21天学通C++学习笔记(四):数组和字符串
1. 数组 概念 是一组元素 这些元素是相同的数据类型 按顺序存储到内存中 目的是避免在业务需要时去重复声明很多同类型的变量 初始化 分别初始化:int i [5] = {1,2,3,4,5}; 全部 ...
- 阿里 RPC 框架 DUBBO 初体验
最近研究了一下阿里开源的分布式RPC框架dubbo,楼主写了一个 demo,体验了一下dubbo的功能. 快速开始 实际上,dubbo的官方文档已经提供了如何使用这个RPC框架example代码,基于 ...
- Mybatis-generator逆向工程
$.Mybatis-generator介绍 MyBatis Generator(MBG)是MyBatis MyBatis 和iBATIS的代码生成器.它将为所有版本的MyBatis以及版本2.2.0之 ...
- 1、认识Socket
专业术语定义:(不易理解浏览大体意思即可) 网络上的两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一个socket. 建立网络通信连接至少要一对端口号(socket).socket本 ...
- linux安装配置阿里云的yum源和python3
一.yum源理解 yum源仓库的地址 在/etc/yum.repos.d/,并且只能读出第一层的repo文件 yum仓库的文件都是以.repo结尾的 二.下载阿里云的.repo仓库文件 ,放到/etc ...
- I/O(输入/输出)---序列化与反序列化
概念: 序列化就是将对象的状态存储到特定的介质中的过程,也就是将对象状态转换为可保持或传输格式的过程. 反序列化则是从特定存储介质中将数据重新构建对象的过程.可以将存储在文件上的对象信息读取,然后重新 ...
- 老男孩Day13作业:ORM学员管理系统
一.作业需求: 用户角色,讲师\学员, 用户登陆后根据角色不同,能做的事情不同,分别如下 讲师视图: 管理班级,可创建班级,根据学员qq号把学员加入班级 可创建指定班级的上课纪录,注意一节上 ...