spark SQL编程
1.编程实现将 RDD 转换为 DataFrame
源文件内容如下(包含 id,name,age):
| 1,Ella,36 2,Bob,29 3,Jack,29 |
请将数据复制保存到 Linux 系统中,命名为 employee.txt,实现从 RDD 转换得到DataFrame,并按“id:1,name:Ella,age:36”的格式打印出 DataFrame 的所有数据。请写出程序代码。
import org.apache.spark.sql.types._
import org.apache.spark.sql.Encoder
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
object RDDtoDF {
def main(args: Array[String]) {
val spark=SparkSession.builder().appName("RddToFrame").master("local").getOrCreate()
import spark.implicits._
val employeeRDD=spark.sparkContext.textFile("file:///usr/local/spark/employee.txt")
val schemaString="id name age"
val fields=schemaString.split(" ").map(fieldName=>StructField
(fieldName,StringType,nullable = true))
val schema = StructType(fields)
val rowRDD = employeeRDD.map(_.split(",")).map(attributes =>
Row(attributes().trim, attributes(), attributes().trim)) val employeeDF = spark.createDataFrame(rowRDD, schema)
employeeDF.createOrReplaceTempView("employee")
val results=spark.sql("select id,name,age from employee")
results.map(t => "id:"+t()+","+"name:"+t()+","+"age:"+t()).show() }
}

2.编程实现利用 DataFrame 读写 MySQL 的数据
(1)在 MySQL 数据库中新建数据库 sparktest,再创建表 employee,包含如表 6-2 所示的
两行数据。
表 6-2 employee 表原有数据
| id | name | gender | Age |
| 1 | Alice | F | 22 |
| 2 | John | M | 25 |
打开mysql


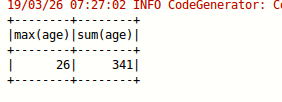
(2)配置 Spark 通过 JDBC 连接数据库 MySQL,编程实现利用 DataFrame 插入如表 6-3 所示的两行数据到 MySQL 中,最后打印出 age 的最大值和 age 的总和。
表 6-3 employee 表新增数据
| id | name | gender | age |
| 3 | Mary | F | 26 |
| 4 | Tom | M | 23 |
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
object TestMySQL {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("TestMySQL").master("local").getOrCreate()
import spark.implicits._
val employeeRDD=spark.sparkContext.parallelize(Array("3 Mary F 26","4 Tom M 23")).map(_.split(" "))
val schema=StructType(List(StructField("id",IntegerType,
true),StructField("name",StringType,true),StructField("gender",StringType,true),
StructField("age",IntegerType,true)))
val rowRDD=employeeRDD.map(p=>Row(p().toInt,p().trim,p().trim,p().toInt))
val employeeDF=spark.createDataFrame(rowRDD,schema)
val prop=new Properties()
prop.put("user","root")
prop.put("password","wangli")
prop.put("driver","com.mysql.jdbc.Driver")
employeeDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/sparktest","sparktest.employee",prop)
val jdbcDF = spark.read.format("jdbc").option("url",
"jdbc:mysql://localhost:3306/sparktest").option("driver","com.mysql.jdbc.Driver").option("dbtable","employee")
.option("user","root").option("password", "wangli").load()
jdbcDF.agg("age" -> "max", "age" -> "sum").show()
} }
spark SQL编程的更多相关文章
- 实验5 Spark SQL编程初级实践
今天做实验[Spark SQL 编程初级实践],虽然网上有答案,但都是用scala语言写的,于是我用java语言重写实现一下. 1 .Spark SQL 基本操作将下列 JSON 格式数据复制到 Li ...
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- 实验 5 Spark SQL 编程初级实践
实验 5 Spark SQL 编程初级实践 参考厦门大学林子雨 1. Spark SQL 基本操作 将下列 json 数据复制到你的 ubuntu 系统/usr/local/spark 下,并 ...
- Spark SQL 编程初级实践
一.实验目的 (1) 通过实验掌握 Spark SQL 的基本编程方法: (2) 熟悉 RDD 到 DataFrame 的转化方法: (3) 熟悉利用 Spark ...
- 第五周周二练习:实验 5 Spark SQL 编程初级实践
1.题目: 源码: import java.util.Properties import org.apache.spark.sql.types._ import org.apache.spark.sq ...
- spark实验(五)--Spark SQL 编程初级实践(1)
一.实验目的 (1)通过实验掌握 Spark SQL 的基本编程方法: (2)熟悉 RDD 到 DataFrame 的转化方法: (3)熟悉利用 Spark SQL 管理来自不同数据源的数据. 二.实 ...
- Spark SQL编程指南(Python)
前言 Spark SQL允许我们在Spark环境中使用SQL或者Hive SQL执行关系型查询.它的核心是一个特殊类型的Spark RDD:SchemaRDD. SchemaRDD类似于传统关 ...
- 实验5 Spark SQL 编程初级实践
源文件内容如下(包含 id,name,age),将数据复制保存到 ubuntu 系统/usr/local/spark 下, 命名为 employee.txt,实现从 RDD 转换得到 DataFram ...
- Spark SQL编程指南(Python)【转】
转自:http://www.cnblogs.com/yurunmiao/p/4685310.html 前言 Spark SQL允许我们在Spark环境中使用SQL或者Hive SQL执行关系型查询 ...
随机推荐
- jQuery中关于toggle的使用
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>t ...
- python,itertools模块
itertools模块的使用: # coding=utf-8 """ itertools模块 """ import itertools im ...
- dynamic和nullable一起使用时的注意
dynamic和nullable一起使用时的注意
- 使用Sencha Cmd创建脚本框架
从Ext JS 4.1.1a 开始,为了配合 Sencha Touch开发 而设计了 Sencha Cmd这个跨平台的命令行工具. 要使用Sencha Cmd,必须先安装好 Java Run-tim ...
- 21天学通C++学习笔记(三):变量和常量
1. 简述 内存是一种临时存储器,也被称为随机存取存储器(RAM),所有的计算机.智能手机及其他可编程设备都包含微处理器和一定数量的内存,用地址来定位不同的存储区域,像编号一样. 硬盘可以永久的存储数 ...
- HTTP总结
参考: https://www.cnblogs.com/fuqiang88/p/5956363.html https://www.cnblogs.com/zlingh/p/5887143.html h ...
- 001.linux的基础优化(期中架构方面的优化)
1. linux内核优化 第一步 cat >>/etc/sysctl.conf<<EOF net.ipv4.tcp_fin_timeout = 2 net.ipv4.tcp_t ...
- Python的特殊属性和魔法函数
python中有很多以下划线开头和结尾的特殊属性和魔法函数,它们有着很重要的作用. 1.__doc__:说明性文档和信息,python自建,不需要我们定义. # -*- coding:utf- -*- ...
- 【bzoj2330】: [SCOI2011]糖果 图论-差分约束-SPFA
[bzoj2330]: [SCOI2011]糖果 恩..就是裸的差分约束.. x=1 -> (A,B,0) (B,A,0) x=2 -> (A,B,1) [这个情况加个A==B无解的要特 ...
- poj2154(polya定理+欧拉函数)
题目链接:http://poj.org/problem?id=2154 题意:n 种颜色的珠子构成一个长为 n 的环,每种颜色珠子个数无限,也不一定要用上所有颜色,旋转可以得到状态只算一种,问有多少种 ...