Spark集群数据处理速度慢(数据本地化问题)
SparkStreaming拉取Kafka中数据,处理后入库。整个流程速度很慢,除去代码中可优化的部分,也在spark集群中找原因。
发现:
集群在处理数据时存在移动数据与移动计算的区别,也有些其他叫法,如:数据本地化、计算本地化、任务本地化等。
自己简单理解:
假设集群有6个节点,来了一批数据共12条,数据被均匀的分布在了每个节点,也就是每个节点2条。现在要开始处理这些数据。
一种情况是:某数据由哪个节点处理被随机的分配,类似A节点存了数据1和数据2却可能被要求处理C节点的数据5和数据6,C节点的数据5和数据6就被备份到A节点,而A节点的数据又要备份到其他某一节点用于被处理。集群节点间存在大量数据移动,影响了速度。
另一种情况:某节点自身储存的数据就由自身来处理,比如A节点存储了数据1和数据2,那么数据1和数据2就由A节点来计算,C节点存储了数据5和数据6,那么数据5和数据6就由C节点来计算。这也就避免了数据的移动。
当然实际要比我描述的复杂得多,我的理解肯定也有不对的地方。
浏览器打开spark 8080端口master界面,图中红色箭头处如果显示各机器IP地址那就很有可能会造成移动数据的问题。
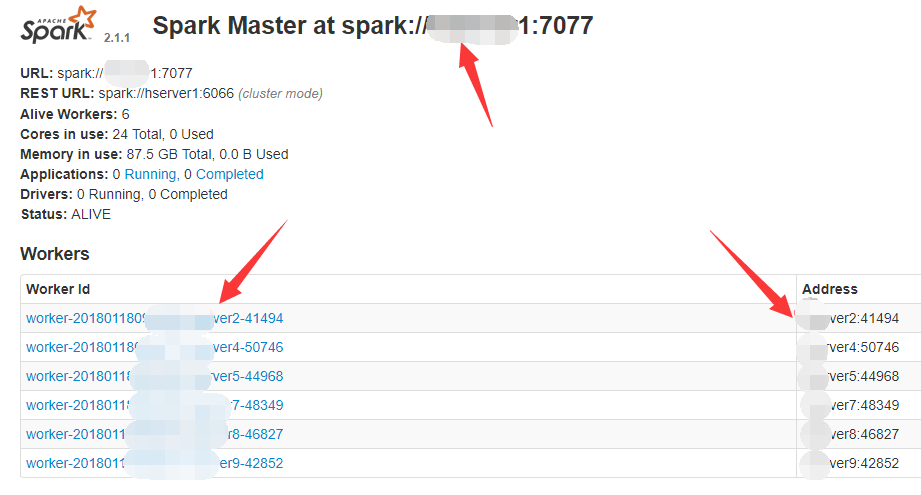
解决:
先停止spark集群,在master机器用 start-master.sh 启动,然后分别在每一台worker机器用 start-slave.sh -h 本机hostname spark://master机器hostname:7077 启动。
过程中可能遇到很多问题,多注意每台机器上的几个文件中的内容是否有问题:/etc/hosts, spark中conf文件夹中spark-env.sh和slaves
Spark集群数据处理速度慢(数据本地化问题)的更多相关文章
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- 大数据平台搭建-spark集群安装
版本要求 java 版本:1.8.*(1.8.0_60) 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downl ...
- 大数据:spark集群搭建
创建spark用户组,组ID1000 groupadd -g 1000 spark 在spark用户组下创建用户ID 2000的spark用户 获取视频中文档资料及完整视频的伙伴请加QQ群:9479 ...
- hbase集群写不进去数据的问题追踪过程
hbase从集群中有8台regionserver服务器,已稳定运行了5个多月,8月15号,发现集群中4个datanode进程死了,经查原因是内存 outofMemory了(因为这几台机器上部署了spa ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- Spark集群的任务提交执行流程
本文转自:https://www.linuxidc.com/Linux/2018-02/150886.htm 一.Spark on Standalone 1.spark集群启动后,Worker向Mas ...
- Spark集群部署
Spark是通用的基于内存计算的大数据框架,可以和hadoop生态系统很好的兼容,以下来部署Spark集群 集群环境:3节点 Master:bigdata1 Slaves:bigdata2,bigda ...
随机推荐
- IC卡文件系统的逻辑结构【转】
转自:http://bbs.ednchina.com/BLOG_ARTICLE_172028.HTM 文件系统是COS的重要模块之一,它负责组织.管理.维护IC卡内存储的所有数据.文件系统的设计和实现 ...
- pm2笔记
概述 pm2是一个进程管理工具.使用pm2部署NodeJS服务可以轻松实现负载均衡. 指定用户启动 pm2启动时会指定一个PM2_HOME目录,作为存放日志文件.rpc.sock文件,默认情况下会PM ...
- ttk.Treeview
TTK的目的. TreeView控件的呈现层次结构,用户可以使用鼠标动作来显示或隐藏结构的任何部分. 与术语“树”的关联是由于编程实践:树结构是一个常见的程序设计.严格地说,在一个TreeView控件 ...
- selenium 3.0与2.0 打开火狐浏览器的区别
3.0的selenium需要引入gecko.driver驱动 ,因为没有在系统环境path中配置相关路径,因此需要特别指出,为了方便使用,建议直接和火狐安装包中的.exe文件放在同一目录下. 2.0的 ...
- 学习apache commons lang3的源代码 (2):RandomStringUtils
本文,主要是分析类;RandomStringUtils. 下面这个方法的:count:表示要生成的数量(比如4个字符组成的字符串等) start,end,表示限定的范围,比如生成ascii码的随机等. ...
- Centos 7.3 安装 Mongodb
通过yum 安装: yum install -y mongodb-server Mongodb操作命令: #启动 systemctl start mongod.service #关闭 systemct ...
- WN7下安装office2013编辑文档反应这么慢?
把office在高级选项里面“禁用硬件加速”给打勾就OK了. [office 2013密钥] 9MBNG-4VQ2Q-WQ2VF-X9MV2-MPXKV F2V7V-8WN76-77BPV-MKY36 ...
- ionic3 学习记录
1生命周期 ionViewDidLoad(){ console.log("1.0 ionViewDidLoad 当页面加载的时候触发,仅在页面创建的时候触发一次,如果被缓存了,那么下次再打开 ...
- 用 grunt-contrib-connect 构建实时预览开发环境 实时刷新
本文基本是参照着 用Grunt与livereload构建实时预览的开发环境 实操了一遍,直接实现能实时预览文件列表,内容页面.不用刷新页面了,这比以前开发网页程序都简单. 这里要用到的 Grunt 插 ...
- RQNOJ PID379 / 约会计划 -并查集
PID379 / 约会计划 题目描述 cc是个超级帅哥,口才又好,rp极高(这句话似乎降rp),又非常的幽默,所以很多mm都跟他关系不错.然而,最关键的是,cc能够很好的调解各各妹妹间的关系.mm之间 ...