01_Java解析XML
【打印list、Map集合的工具方法】
/**
* 打印List集合对应的元素
*/
public void printList(List<Object> list){
for(Object o:list){
System.out.println(o.toString());
}
} /**
* 打印Map集合对应的key-value
*/
public void printMap(Map<String,String> map){
Iterator it=map.entrySet().iterator();
while(it.hasNext()){
Entry entry=(Entry) it.next();
String key=(String) entry.getKey();
String value=(String) entry.getValue();
System.out.println("[ key="+key+", value="+value+" ]");
}
}
【cnBlogs.xml,保存在C:/cnBlogs.xml】
<?xml version="1.0" encoding="UTF-8"?>
<spiderman name="开源中国GIT">
<property key="duration" value="30s" /><!-- 运行时间 0 表示永久,可以给 {n}s {n}m {n}h {n}d -->
<property key="scheduler.period" value="24h" /><!-- 调度间隔时间 -->
<property key="logger.level" value="WARN" /><!-- 日志级别 INFO DEBUG WARN ERROR OFF --> <property key="worker.download.enabled" value="1" /><!-- 是否开启下载工人 -->
<property key="worker.extract.enabled" value="1" /><!-- 是否开启解析工人 -->
<property key="worker.result.enabled" value="1" /><!-- 是否开启结果处理工人 --> <property key="worker.download.class" value="net.kernal.spiderman.worker.download.impl.WebDriverDownloader" />
<property key="worker.download.chrome.driver" value="dist/chromedriver.exe" /><!-- WebDriver下载器的Chrome驱动 -->
<property key="worker.download.selector.delay" value="1s" /><!-- WebDriver下载器的延时时间 --> <property key="worker.download.size" value="1" /><!-- 下载线程数 -->
<property key="worker.extract.size" value="2" /><!-- 页面抽取线程数 -->
<property key="worker.result.size" value="2" /><!-- 结果处理线程数 -->
<property key="worker.result.handler" value="net.kernal.spiderman.worker.result.handler.impl.FileJsonResultHandler" />
<property key="worker.result.store" value="store/result" /><!-- 采集结果放置目录 -->
<property key="queue.store.path" value="store" /><!-- 检查器需要用到BDb存储 --> <!-- 种子 -->
<seed url="http://www.cnblogs.com/HigginCui/p/5811631.html" />
<seed url="http://www.cnblogs.com/HigginCui/p/5811234.html" />
<seed url="http://www.cnblogs.com/HigginCui/p/5827356.html" />
<seed url="http://www.cnblogs.com/HigginCui/p/5811494.html" /> <!-- 页面抽取规则 -->
<extract>
<extractor name="HtmlCleaner" class="net.kernal.spiderman.worker.extract.extractor.impl.HtmlCleanerExtractor" isDefault="1" />
<extractor name="Text" class="net.kernal.spiderman.worker.extract.extractor.impl.TextExtractor" />
<page name="我的项目列表" extractor="HtmlCleaner">
<url-match-rule type="equals">http://www.cnblogs.com/HigginCui/p/5811631.html</url-match-rule>
<model>
<field name="项目URL" isForNewTask="1" isArray="1" xpath="//a[@class='project']" attr="href">
<filter type="script">'http://www.cnblogs.com/HigginCui/p/5811631.html'+$this</filter>
</field>
</model>
</page>
<page name="项目详情" extractor="Text">
<url-match-rule type="startsWith">http://www.cnblogs.com/HigginCui/p/5811494.html</url-match-rule>
</page>
</extract>
</spiderman>

【test1.java】 使用extractModel(Object obj,String modelXpath)方法抽取对应xpath元素的方法
public class Demo01 {
/**
* xpath提供了对Xpath计算环境和表达式的访问
*/
private XPath xpath;
/**
* Document表示整个HTML或XML文档,它是文档的根,提供对文档数据的基本访问。
*/
private Document doc;
private Transformer transformer;
@Test
public void test1() throws ParserConfigurationException, SAXException, IOException {
InputStream is=new FileInputStream("C:\\cnBlogs.xml");
DocumentBuilder db=DocumentBuilderFactory.newInstance().newDocumentBuilder(); //从DOM工厂获得DOM解析器
doc=db.parse(is); //解析的XML文档C:\\cnBlogs.xml的输入流,得到一个Document
xpath=XPathFactory.newInstance().newXPath();
//抽取property中的key属性
System.out.println("=========抽取property中的key属性==========");
List<Object> propertyKeyList=extractModel(doc,"//property/@key");
printList(propertyKeyList);
//抽取seed中的url属性
System.out.println("=========抽取seed中的url属性==========");
List<Object> seedUrlList=extractModel(doc,"//seed/@url");
printList(seedUrlList);
//抽取extractor中的class属性
System.out.println("=========抽取extractor中的class属性==========");
List<Object> extractorClassList=extractModel(doc,"//extractor/@class");
printList(extractorClassList);
//抽取url-match-rule的text()文本
System.out.println("=========抽取url-match-rule的text()文本==========");
List<Object> url_match_rulTextList=extractModel(doc,"//url-match-rule/text()");
printList(url_match_rulTextList);
}
/**
* 抽取对应Xpath为"modelXpath"的元素的方法
*/
public List<Object> extractModel(Object obj,String modelXpath){
NodeList nodeList = null;
try {
/**
* Xpath.compile(String expression):编译一个xpath表达式expression提供以后计算,返回一个XPathExpression
* XPathExpression.evalute(Object item,QName returnType):计算指定上下文的Xpath表达式,返回指定的类型的结果
*/
nodeList = (NodeList)this.xpath.compile(modelXpath).evaluate(obj, XPathConstants.NODESET);
} catch (XPathExpressionException e) {
e.printStackTrace();
}
//下面是将NodeList集合转换成我们普通的ArrayList集合
List<Object> mNodes = new ArrayList<Object>();
for (int i = ; i < nodeList.getLength(); i++){ //getLength():获取NodeList中的结点数
Node node = nodeList.item(i); //返回NodeList集合中的第i个项
mNodes.add(node);
}
return mNodes;
}
}
【运行结果】

【小结】
 [ Document javax.xml.parsers.DocumentBuilder.parse(InputStream is) throws SAXException, IOException ]
[ Document javax.xml.parsers.DocumentBuilder.parse(InputStream is) throws SAXException, IOException ] [ Object javax.xml.xpath.XPathExpression.evaluate(Object item, QName returnType) throws XPathExpressionException ]
[ Object javax.xml.xpath.XPathExpression.evaluate(Object item, QName returnType) throws XPathExpressionException ] [
[ @Test
public void testNode() throws Exception{
InputStream is=new FileInputStream("C:\\cnBlogs.xml");
DocumentBuilder db=DocumentBuilderFactory.newInstance().newDocumentBuilder(); //从DOM工厂获得DOM解析器
doc=db.parse(is); //解析的XML文档C:\\cnBlogs.xml的输入流,得到一个Document
xpath=XPathFactory.newInstance().newXPath(); List<Object> propertyNodeList=extractModel(doc,"//property"); //抽取对应的model
for(Object o: propertyNodeList){
Node node=(Node) o;
System.out.println("【 =======nodeType:"+node.getNodeType()+", nodeName:"+node.getNodeName()+" =======】");
NamedNodeMap attrs=node.getAttributes(); //获取所有的属性name-value(所以是Map类型的)
for(int i=;i<attrs.getLength();i++){ //遍历所有的map
Node n=attrs.item(i);
System.out.println("[ nodeType:"+n.getNodeType()+", nodeName:"+n.getNodeName()+", nodeValue:"+n.getNodeValue()+" ]"); //得到属性的name 和 属性的value
}
}
}
【运行结果(部分)】
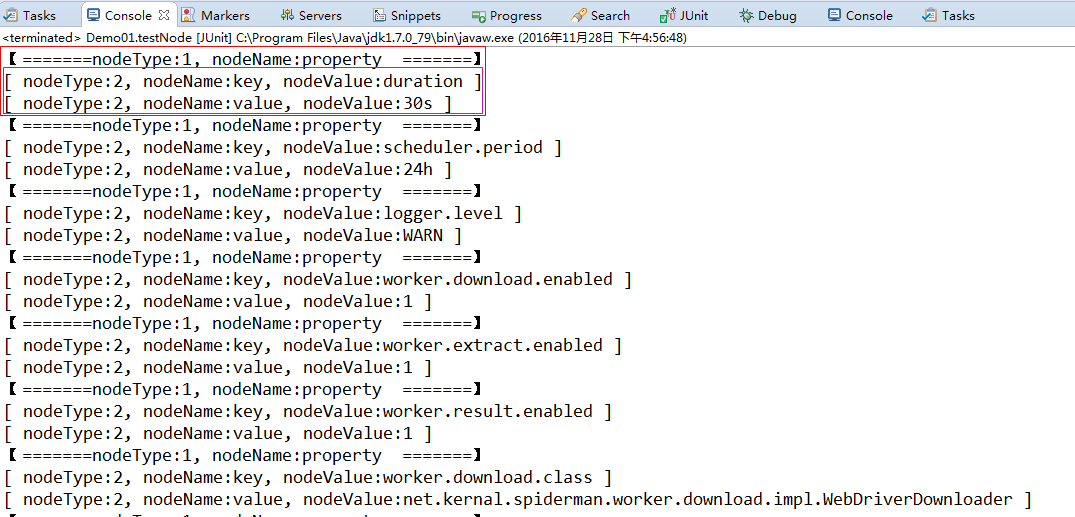
【解释】

01_Java解析XML的更多相关文章
- Android 解析XML文件和生成XML文件
解析XML文件 public static void initXML(Context context) { //can't create in /data/media/0 because permis ...
- Android之解析XML
1.XML:可扩展标记语言. 可扩展标记语言是一种很像超文本标记语言的标记语言. 它的设计宗旨是传输数据,而不是显示数据. 它的标记没有被预定义.需要自行定义标签. 它被设计为具有自我描述性. 是W3 ...
- Android之Pull解析XML
一.Pull解析方法介绍 除了可以使用SAX和DOM解析XML文件,也可以使用Android内置的Pull解析器解析XML文件.Pull解析器的运行方式与SAX解析器相似.它也是事件触发的.Pull解 ...
- Android之DOM解析XML
一.DOM解析方法介绍 DOM是基于树形结构的节点或信息片段的集合,允许开发人员使用DOM API遍历XML树,检索所需数据.分析该结构通常需要加载整个文档和构造树形结构,然后才可以检索和更新节点信息 ...
- Android之SAX解析XML
一.SAX解析方法介绍 SAX(Simple API for XML)是一个解析速度快并且占用内存少的XML解析器,非常适合用于Android等移动设备. SAX解析器是一种基于事件的解析器,事件驱动 ...
- Android 使用pull,sax解析xml
pull解析xml文件 1.获得XmlpullParser类的引用 这里有两种方法 //解析器工厂 XmlPullParserFactory factory=XmlPullParserFactory. ...
- 用 ElementTree 在 Python 中解析 XML
用 ElementTree 在 Python 中解析 XML 原文: http://eli.thegreenplace.net/2012/03/15/processing-xml-in-python- ...
- java解析xml的三种方法
java解析XML的三种方法 1.SAX事件解析 package com.wzh.sax; import org.xml.sax.Attributes; import org.xml.sax.SAXE ...
- WP8解析XML格式文件
DOTA2 WebAPI请求返回的格式有两种,一种是XML,一种是JSON,默认是返回JSON格式,如果要返回XML格式的话,需要在加上format=xml. 这里举一个简单的解析XML格式的例子(更 ...
随机推荐
- Spring Framework 5.0.0.M3中文文档 翻译记录 Part I. Spring框架概览1-2.2
Part I. Spring框架概览 The Spring Framework is a lightweight solution and a potential one-stop-shop for ...
- ecshop去官方化的修改
1:如何修改网站"欢迎光临本店" 回答:languages\zh_cn\common.php文件中, $_LANG['welcome'] = '欢迎光临本店';将他修改成你需要的字 ...
- php empty()和isset()的区别<转载>
在使用 php 编写页面程序时,我经常使用变量处理函数判断 php 页面尾部参数的某个变量值是否为空,开始的时候我习惯了使用 empty() 函数,却发现了一些问题,因此改用 isset() 函数,问 ...
- windows消息钩子
1.消息钩子的概念: Windows应用程序是基于消息驱动的,不论什么线程仅仅要注冊窗体类都会有一个消息队列用于接收用户输入的消息和系统消息.为了拦截消息,Windows提出了钩子的概念.钩子(Hoo ...
- 金蝶K3 破解版
- [AngularJS - thoughtram] Exploring Angular 1.3: Binding to Directive Controllers
The post we have: http://www.cnblogs.com/Answer1215/p/4185504.html gives a breif introduce about bin ...
- iOS开发——新特性OC篇&Swift 2.0新特性
Swift 2.0新特性 转眼间,Swift已经一岁多了,这门新鲜.语法时尚.类型安全.执行速度更快的语言已经渐渐的深入广大开发者的心.我同样也是非常喜爱这门新的编程语言. 今年6月,一年一度 ...
- Route Filters
Route Filters The Controller's Middleware, represents a High-Level processing API, executed by the r ...
- SQL 编码规范
1. 必须对表起别名,方便调查表用了哪些列 比如 select owner,object_id,name from a,b where a.id=b.id; 如果不对表取别名,我怎么知道你访问的列是哪 ...
- ASP.NET MVC 4 Ajax上传文件
这两天一直纠结着表单的问题.想在一个表单里实现三个功能: 输入查询条件,点击查询: 导出查询数据: 上传文件: 方法有很多,乱花渐欲迷人眼,尝试了很多,无果.大致说的是,给不同按钮写js代码,在js代 ...