【Hadoop代码笔记】Hadoop作业提交之JobTracker等相关功能模块初始化
一、概要描述
本文重点描述在JobTracker一端接收作业、调度作业等几个模块的初始化工作。想过模块的介绍会在其他文章中比较详细的描述。受理作业提交在下一篇文章中会进行描述。
为了表达的尽可能清晰一点只是摘录出影响逻辑流转的主要代码。重点强调直接的协作调用,每个内部完成的逻辑(一直可以更细的说明、有些细节可能自己也理解并不深刻:-()在后续会描述。
主要包括JobTracker、TaskScheduler(此处以FairScheduler为例)、JobInProgressListener(以用的较多的EagerTaskInitializationListener为例)、TaskSelector(以最简单的DefaultTaskSelector为例)等。
二、 流程描述
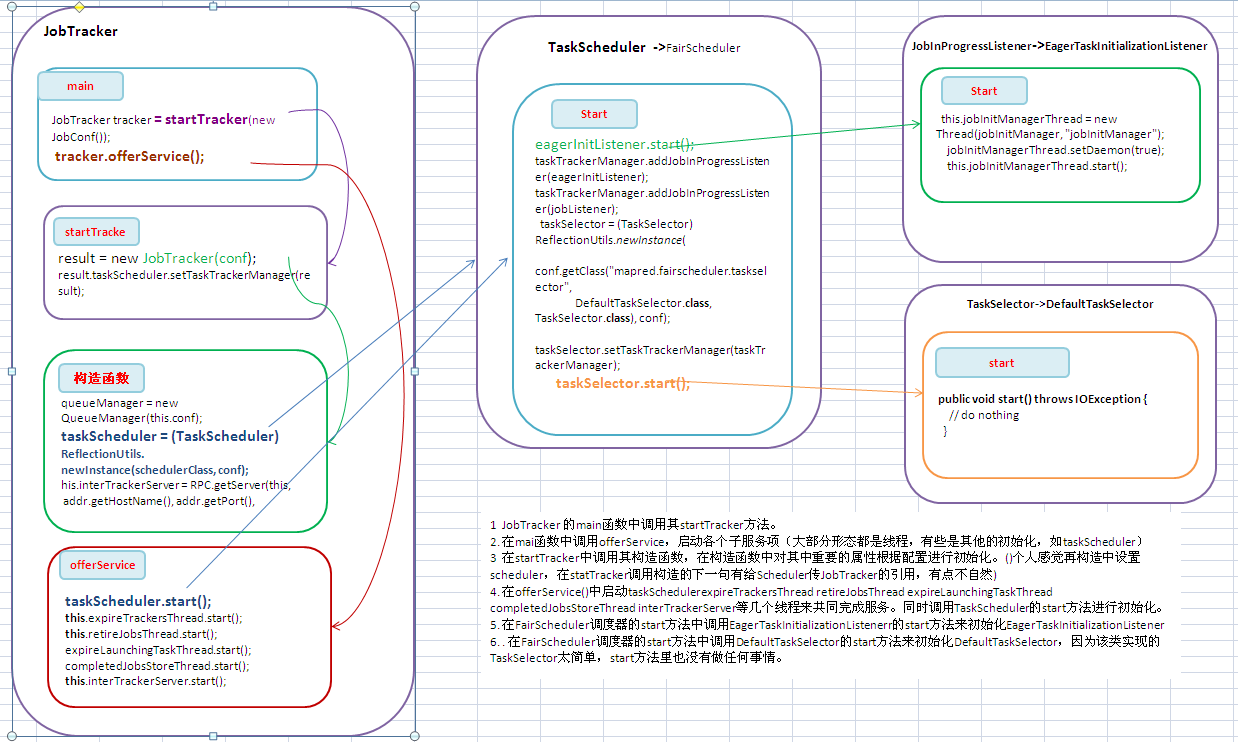
1 JobTracker 的main函数中调用其startTracker方法。
2. 在mai函数中调用offerService,启动各个子服务项(大部分形态都是线程,有些是其他的初始化,如taskScheduler)
3 在startTracker中调用其构造函数,在构造函数中对其中重要的属性根据配置进行初始化。()个人感觉再构造中设置scheduler,在statTracker调用构造的下一句有给Scheduler传JobTracker的引用,有点不自然)
4. 在offerService()中启动taskSchedulerexpireTrackersThread retireJobsThread expireLaunchingTaskThread completedJobsStoreThread interTrackerServer等几个线程来共同完成服务。同时调用TaskScheduler的start方法进行初始化。
5. 在FairScheduler调度器的start方法中调用EagerTaskInitializationListenerr的start方法来初始化EagerTaskInitializationListener
6. . 在FairScheduler调度器的start方法中调用DefaultTaskSelector的start方法来初始化DefaultTaskSelector,因为该类实现的TaskSelector太简单,start方法里也没有做任何事情。
三、 代码详述
1. JobTracker 的入口main函数。主要是实例化一个JobTracker类,然后调用offerService方法做事情。
在Jobtracker的main函数中去掉记日志和异常捕获外关键代码就一下两行。
JobTracker tracker = startTracker(new JobConf());
tracker.offerService();
2. JobTracker 的startTracker方法。 调用JobTracker的构造函数,完成初始化工作。
JobTracker result = null;
while (true) {
try {
result = new JobTracker(conf);
result.taskScheduler.setTaskTrackerManager(result);
Thread.sleep(1000);
} JobEndNotifier.startNotifier();
return result;
3. JobTracker的构造方法JobTracker(JobConf conf)。是一个有两三屏的长的方法。值得关注下,当然jobtracker服务运维的有些部分会适当忽略,着重看处理作业的部分。(其实这样的说法也不太对,Jobtracker的主要甚至是唯一的作用就是处理提交的job)
主要的工作有:
1)创建一个初始化一个队列管理器,一个HadoopMapReduce作业可以配置一个或者多个Queue,依赖于其使用的作业调度器Scheduler
2)根据配置创建一个调度器
3)创建一个RPC Server,其中handlerCount是RPC server服务端处理请求的Handler线程的数量,默认是10。详细机制参照RPC机制描述。
4)创建一个创建一个HttpServer,用于JobTracker的信息发布。
5)创建一个RecoveryManager,用于JobTracker重启时候恢复
6)创建一个CompletedJobStatusStore,用户持久化作业状态。
//初始化一个队列管理器,一个HadoopMapReduce作业可以配置一个或者多个Queue,依赖于其使用的作业调度器Scheduler
queueManager = new QueueManager(this.conf);
// 根据 conf的配置创建一个调度器
Class<? extends TaskScheduler> schedulerClass = conf.getClass("mapred.jobtracker.taskScheduler",JobQueueTaskScheduler.class, TaskScheduler.class);
taskScheduler = (TaskScheduler) ReflectionUtils.newInstance(schedulerClass, conf);
//创建一个RPC Server,作用见上节详细描述
InetSocketAddress addr = getAddress(conf);
this.localMachine = addr.getHostName();
this.port = addr.getPort();
int handlerCount = conf.getInt("mapred.job.tracker.handler.count", 10);
//其中handlerCount是RPC server服务端处理请求的Handler线程的数量,默认是10
this.interTrackerServer = RPC.getServer(this, addr.getHostName(), addr.getPort(), handlerCount, false, conf);
//创建一个HttpServer
infoServer = new HttpServer("job", infoBindAddress, tmpInfoPort, tmpInfoPort == 0, conf);
infoServer.addServlet("reducegraph", "/taskgraph", TaskGraphServlet.class);
infoServer.start();
//用于重启时候恢复
recoveryManager = new RecoveryManager();
//初始化 the job status store,用户持久化作业状态
completedJobStatusStore = new CompletedJobStatusStore(conf,fs);
4. Jobtracker的offerService方法。把她相关的子服务(大部分是线程)启动,其他的相关的初始化。
1)启动任务调度器。
2)在每次启动时候,恢复需要恢复的作业
3)启动expireTrackersThread,其实是启动ExpireTrackers类型的一个线程。this.expireTrackersThread = new Thread(this.expireTrackers, expireTrackers");
4)启动retireJobsThread ,其实是启动RetireJobs类型的一个线程.删除完成的过期job
5)启动expireLaunchingTaskThread,查分配的task未返回报告的使之为过期。
6)启动CompletedJobStatusStore,负责job信息的持久化或者读出。
7)启动RPC 服务,接收客户端端的RPC请求
//启动任务调度器。
taskScheduler.start();
//恢复需要恢复的作业,不深入进行看了。
recoveryManager.recover();
//启动expireTrackersThread,其实是启动ExpireTrackers类型的一个线程。this.expireTrackersThread = new Thread(this.expireTrackers, expireTrackers");
this.expireTrackersThread.start();
//启动retireJobsThread ,其实是启动RetireJobs类型的一个线程.删除完成的过期job this.retireJobsThread = new Thread(this.retireJobs, "retireJobs");
this.retireJobsThread.start();
//检查分配的task未返回报告的使之为过期。
expireLaunchingTaskThread.start();
//启动CompletedJobStatusStore,负责job信息的持久化或者读出。
completedJobsStoreThread.start();
//启动RPC 服务,接收客户端端的RPC请求
this.interTrackerServer.start();
5. TaskScheduler(FairScheduler)的Start方法。Scheduler相关的初始化。
1)调用用EagerTaskInitializationListener的Start方法,启动一个守护线程来初始化其jobInitQueue中的Job(JobInprogress)
2)向taskTrackerManager(其实就是JobTracker)注册JobInProgressListener,响应Job相关的动作,如典型的jobAdded方法。eagerInitListener响应JobAdded方法,是把加入的job放到自己的管理的队列中,启动线程去初始化;jobListener是该类的内部类,其jobAdded方法是构造job的调度信息JobInfo,并把每个job和对应的调度信息加入到实例变量Map<JobInProgress, JobInfo> infos中,供调度时使用。
3)初始化PoolManager
4)根据配置,初始化一个LoadManager,在scheduler中决定某个tasktracker是否可以得到一个新的Task,不同的LoadManager有不同的算法。一般默认的是CapBasedLoadManager,根据每个Node的最大可接受数量平均分配。
5)构造一个TaskSelector
6) 一个线程调用FairScheduler的update方法来以一定间隔来更新作业权重、运行待运行的task数等状态信息以便FairScheduler调度用。
7) 注册到infoserver中,可以通过web查看其信息。
// 1)调用用EagerTaskInitializationListener的Start方法,启动一个守护线程来初始化其jobInitQueue中的Job(JobInprogress)
Configuration conf = getConf();
this.eagerInitListener = new EagerTaskInitializationListener(conf); eagerInitListener.start();
// 2)向taskTrackerManager(其实就是JobTracker)注册JobInProgressListener,响应Job相关的动作,如典型的jobAdded方法。eagerInitListener响应JobAdded方法,是把加入的job放到自己的管理的队列中,启动线程去初始化;jobListener是该类的内部类,其jobAdded方法是构造job的调度信息JobInfo,并把每个job和对应的调度信息加入到实例变量Map<JobInProgress,
// JobInfo> infos中,供调度时使用。
taskTrackerManager.addJobInProgressListener(eagerInitListener);
taskTrackerManager.addJobInProgressListener(jobListener); // 3)初始化PoolManager
poolMgr = new PoolManager(conf);
// 4)根据配置,初始化一个LoadManager,在scheduler中决定某个tasktracker是否可以得到一个新的Task,不同的LoadManager有不同的算法。一般默认的是CapBasedLoadManager,根据每个Node的最大可接受数量平均分配。
loadMgr = (LoadManager) ReflectionUtils.newInstance(conf.getClass(
"mapred.fairscheduler.loadmanager", CapBasedLoadManager.class,
LoadManager.class), conf);
loadMgr.setTaskTrackerManager(taskTrackerManager);
loadMgr.start(); // 5)构造一个TaskSelector
taskSelector = (TaskSelector) ReflectionUtils.newInstance(conf
.getClass("mapred.fairscheduler.taskselector",
DefaultTaskSelector.class, TaskSelector.class), conf);
taskSelector.setTaskTrackerManager(taskTrackerManager);
taskSelector.start();
Class<?> weightAdjClass = conf.getClass(
"mapred.fairscheduler.weightadjuster", null);
if (weightAdjClass != null) {
weightAdjuster = (WeightAdjuster) ReflectionUtils.newInstance(
weightAdjClass, conf);
}
assignMultiple = conf.getBoolean("mapred.fairscheduler.assignmultiple",
false);
sizeBasedWeight = conf.getBoolean(
"mapred.fairscheduler.sizebasedweight", false);
initialized = true;
running = true;
lastUpdateTime = clock.getTime();
// 6) 一个线程调用FairScheduler的update方法来以一定间隔来更新作业权重、运行待运行的task数等状态信息以便FairScheduler调度用。
if (runBackgroundUpdates)
new UpdateThread().start();
// 7) 注册到infoserver中,可以通过web查看其信息。
if (taskTrackerManager instanceof JobTracker) {
JobTracker jobTracker = (JobTracker) taskTrackerManager;
HttpServer infoServer = jobTracker.infoServer;
infoServer.setAttribute("scheduler", this);
infoServer.addServlet("scheduler", "/scheduler",
FairSchedulerServlet.class);
}
6. JobInProgressListener(EagerTaskInitializationListener)的start方法。初始化一个线程,检查器jobqueue上的job进行初始化。
this.jobInitManagerThread = new Thread(jobInitManager, "jobInitManager");
jobInitManagerThread.setDaemon(true);
this.jobInitManagerThread.start();
7. TaskSelector(DefaultTaskSelector)的start方法。在父类TaskSelector和子类DefaultTaskSelector都没有做任何事情,因为DefaultTaskSelector的实现的主要业务方法只是简单封装,在该类中没有保存任何状态的信息,也不用其他子服务之类的来完成,因此没有初始化内容。但是其他方式的TaskSelector可能会有,因此父类中定义了个start方法。
public void start() throws IOException {
// do nothing
}
完。
为了转载内容的一致性、可追溯性和保证及时更新纠错,转载时请注明来自:http://www.cnblogs.com/douba/p/hadoop_job_submit_service_init.html。谢谢!
【Hadoop代码笔记】Hadoop作业提交之JobTracker等相关功能模块初始化的更多相关文章
- JobTracker等相关功能模块初始化
[Hadoop代码笔记]Hadoop作业提交之JobTracker等相关功能模块初始化 一.概要描述 本文重点描述在JobTracker一端接收作业.调度作业等几个模块的初始化工作.想过模块的介绍会在 ...
- 【Hadoop代码笔记】通过JobClient对Jobtracker的调用详细了解Hadoop RPC
Hadoop的各个服务间,客户端和服务间的交互采用RPC方式.关于这种机制介绍的资源很多,也不难理解,这里不做背景介绍.只是尝试从Jobclient向JobTracker提交作业这个最简单的客户端服务 ...
- 【hadoop代码笔记】hadoop作业提交之汇总
一.概述 在本篇博文中,试图通过代码了解hadoop job执行的整个流程.即用户提交的mapreduce的jar文件.输入提交到hadoop的集群,并在集群中运行.重点在代码的角度描述整个流程,有些 ...
- 【Hadoop代码笔记】目录
整理09年时候做的Hadoop的代码笔记. 开始. [Hadoop代码笔记]Hadoop作业提交之客户端作业提交 [Hadoop代码笔记]通过JobClient对Jobtracker的调用看详细了解H ...
- 【Hadoop代码笔记】Hadoop作业提交之JobTracker接收作业提交
一.概要描述 在上一篇博文中主要描述了JobTracker接收作业的几个服务(或功能)模块的初始化过程.本节将介绍这些服务(或功能)是如何接收到提交的job.本来作业的初始化也可以在本节内描述,但是涉 ...
- 【Hadoop代码笔记】Hadoop作业提交之客户端作业提交
1. 概要描述仅仅描述向Hadoop提交作业的第一步,即调用Jobclient的submitJob方法,向Hadoop提交作业. 2. 详细描述Jobclient使用内置的JobS ...
- 【hadoop代码笔记】Hadoop作业提交中EagerTaskInitializationListener的作用
在整理FairScheduler实现的task调度逻辑时,注意到EagerTaskInitializationListener类.差不多应该是job提交相关的逻辑代码中最简单清楚的一个了. todo: ...
- 【hadoop代码笔记】Mapreduce shuffle过程之Map输出过程
一.概要描述 shuffle是MapReduce的一个核心过程,因此没有在前面的MapReduce作业提交的过程中描述,而是单独拿出来比较详细的描述. 根据官方的流程图示如下: 本篇文章中只是想尝试从 ...
- 【Hadoop代码笔记】Hadoop作业提交之TaskTracker获取Task
一.概要描述 在上上一篇博文和上一篇博文中分别描述了jobTracker和其服务(功能)模块初始化完成后,接收JobClient提交的作业,并进行初始化.本文着重描述,JobTracker如何选择作业 ...
随机推荐
- 团体程序设计天梯赛-练习集L2-006. 树的遍历
L2-006. 树的遍历 时间限制 400 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 陈越 给定一棵二叉树的后序遍历和中序遍历,请你输出其层序遍历 ...
- Ehcache详细解读(转载)
Ehcache 是现在最流行的纯Java开源缓存框架,配置简单.结构清晰.功能强大,最初知道它,是从Hibernate的缓存开始的.网上中文的EhCache材料以简单介绍和配置方法居多,如果你有这方面 ...
- Stretch a row if data overflows in jasper reports
My band stretches if necessary with the following conditions, I do not know yours. I have started wi ...
- ***总结:在linux下连接redis并进行命令行操作(设置redis密码)
[root@iZ254lfyd6nZ ~]# cd / [root@iZ254lfyd6nZ /]# ls bin boot dev etc home lib lib64 lost+found med ...
- Ubuntu环境下手动配置openSSH
配置openSSH 1.手动下载压缩文件(.tar.gz) zlib-1.2.7.tar.gz openssl-1.0.1j.tar.gz openssh-6.0p1.tar.gz 2.安装zlib ...
- Google Play市场考察报告
考察了Google Play日本市场的10款应用,考察的重点在于每个App有什么亮点,盈利模式在哪里.本文并不是App的功能介绍. (1)恋爱文集[文库类应用] 该应用收录了一些恋爱文章,其主要受众是 ...
- hdu 1729 Stone Game 博弈论
那么对于这题对于每一堆,放石子放满就想当于满的时候取s-c个,反向只是让我理解题意更深. 首先我们知道(S,S)这个局面是必败局面.对于每一堆能加的数量有限,而当c的值(大于或者等于) D=sqrt( ...
- 多线程 (三)iOS中的锁
锁的类别:互斥锁,递归锁,条件锁,自旋锁等 锁的实现方式:NSLock,NSRecursiveLock, NSConditionLock,@synchronized,GCD的信号量等 下面说一下常用的 ...
- [itint5]跳马问题加强版
http://www.itint5.com/oj/#12 首先由跳马问题一,就是普通的日字型跳法,那么在无限棋盘上,任何点都是可达的.证法是先推出可以由(0,0)到(0,1),那么由对称型等可知任何点 ...
- 锋利的JQuery-Jquery中DOM操作
<html> <head> <meta http-equiv="Content-Type" content="text/html; char ...