【原创】如何确定Kafka的分区数、key和consumer线程数
def partition(key: Any, numPartitions: Int): Int = {
Utils.abs(key.hashCode) % numPartitions
}
这就保证了相同key的消息一定会被路由到相同的分区。如果你没有指定key,那么Kafka是如何确定这条消息去往哪个分区的呢?
if(key == null) { // 如果没有指定key
val id = sendPartitionPerTopicCache.get(topic) // 先看看Kafka有没有缓存的现成的分区Id
id match {
case Some(partitionId) =>
partitionId // 如果有的话直接使用这个分区Id就好了
case None => // 如果没有的话,
val availablePartitions = topicPartitionList.filter(_.leaderBrokerIdOpt.isDefined) //找出所有可用分区的leader所在的broker
if (availablePartitions.isEmpty)
throw new LeaderNotAvailableException("No leader for any partition in topic " + topic)
val index = Utils.abs(Random.nextInt) % availablePartitions.size // 从中随机挑一个
val partitionId = availablePartitions(index).partitionId
sendPartitionPerTopicCache.put(topic, partitionId) // 更新缓存以备下一次直接使用
partitionId
}
}
可以看出,Kafka几乎就是随机找一个分区发送无key的消息,然后把这个分区号加入到缓存中以备后面直接使用——当然了,Kafka本身也会清空该缓存(默认每10分钟或每次请求topic元数据时)
val nPartsPerConsumer = curPartitions.size / curConsumers.size // 每个consumer至少保证消费的分区数
val nConsumersWithExtraPart = curPartitions.size % curConsumers.size // 还剩下多少个分区需要单独分配给开头的线程们
...
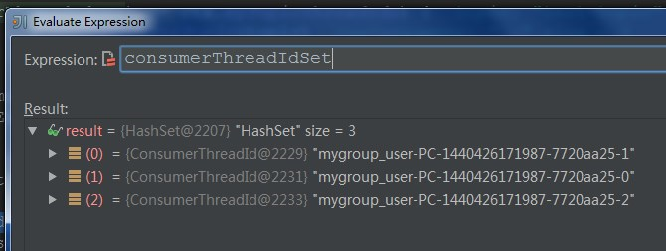
for (consumerThreadId <- consumerThreadIdSet) { // 对于每一个consumer线程
val myConsumerPosition = curConsumers.indexOf(consumerThreadId) //算出该线程在所有线程中的位置,介于[0, n-1]
assert(myConsumerPosition >= 0)
// startPart 就是这个线程要消费的起始分区数
val startPart = nPartsPerConsumer * myConsumerPosition + myConsumerPosition.min(nConsumersWithExtraPart)
// nParts 就是这个线程总共要消费多少个分区
val nParts = nPartsPerConsumer + (if (myConsumerPosition + 1 > nConsumersWithExtraPart) 0 else 1)
...
}
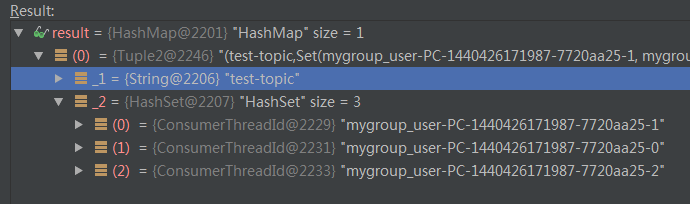
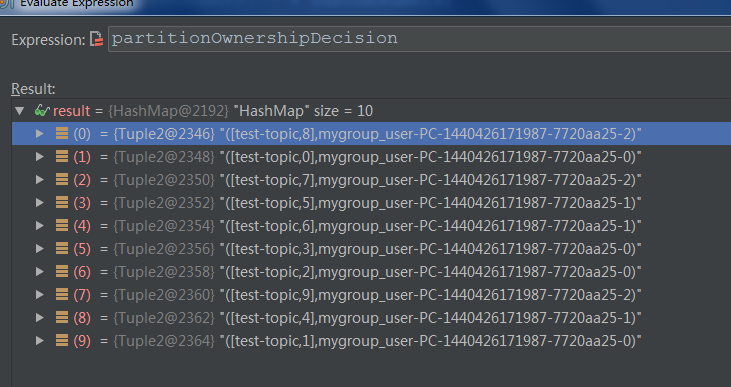
针对于这个例子,nPartsPerConsumer就是10/3=3,nConsumersWithExtraPart为10%3=1,说明每个线程至少保证3个分区,还剩下1个分区需要单独分配给开头的若干个线程。这就是为什么C0消费4个分区,后面的2个线程每个消费3个分区,具体过程详见下面的Debug截图信息:




【原创】如何确定Kafka的分区数、key和consumer线程数的更多相关文章
- 如何确定Kafka的分区数、key和consumer线程数
[原创]如何确定Kafka的分区数.key和consumer线程数 在Kafak中国社区的qq群中,这个问题被提及的比例是相当高的,这也是Kafka用户最常碰到的问题之一.本文结合Kafka源码试 ...
- 【转】如何确定Kafka的分区数、key和consumer线程数
文章来源:http://www.cnblogs.com/huxi2b/p/4583249.html -------------------------------------------------- ...
- 【原创】开发Kafka通用数据平台中间件
开发Kafka通用数据平台中间件 (含本次项目全部代码及资源) 目录: 一. Kafka概述 二. Kafka启动命令 三.我们为什么使用Kafka 四. Kafka数据平台中间件设计及代码解析 五. ...
- Apache Samza流处理框架介绍——kafka+LevelDB的Key/Value数据库来存储历史消息+?
转自:http://www.infoq.com/cn/news/2015/02/apache-samza-top-project Apache Samza是一个开源.分布式的流处理框架,它使用开源分布 ...
- 【原创】谈谈redis的热key问题如何解决
引言 讲了几天的数据库系列的文章,大家一定看烦了,其实还没讲完...(以下省略一万字). 今天我们换换口味,来写redis方面的内容,谈谈热key问题如何解决. 其实热key问题说来也很简单,就是瞬间 ...
- kafka如何防止key相同的消息并发消费
最开始,我认为只用把消费者设置为单线程消费,就可以避免并发问题. 因为同一个key,分区一定相同,那么就只会被同一个消费者消费,消费者又是单线程,这样就避免了并发问题 后面发现,上述的方式没有办法处理 ...
- springboot kafka集成(实现producer和consumer)
本文介绍如何在springboot项目中集成kafka收发message. 1.先解决依赖 springboot相关的依赖我们就不提了,和kafka相关的只依赖一个spring-kafka集成包 &l ...
- Apache Kafka - KIP-42: Add Producer and Consumer Interceptors
kafka 0.10.0.0 released Interceptors的概念应该来自flume 参考,http://blog.csdn.net/xiao_jun_0820/article/det ...
- kafka producer自定义partitioner和consumer多线程
为了更好的实现负载均衡和消息的顺序性,Kafka Producer可以通过分发策略发送给指定的Partition.Kafka Java客户端有默认的Partitioner,平均的向目标topic的各个 ...
随机推荐
- javascript工厂模式和构造函数模式创建对象
一.工厂模式 工厂模式是软件工程领域一种广为人知的设计模式,这种模式抽象了创建具体对象的过程(本书后面还将讨论其他设计模式及其在JavaScript 中的实现).考虑到在ECMAScript 中无法创 ...
- UWP开发之Mvvmlight实践八:为什么事件注销处理要写在OnNavigatingFrom中
前一段开发UWP应用的时候因为系统返回按钮事件(SystemNavigationManager.GetForCurrentView().BackRequested)浪费了不少时间.现象就是在手机版的详 ...
- potrace源码分析一
1 简介 potrace是由Dalhousie University的Peter Selinger开发一款位图轮廓矢量化软件,该软件源码是可以公开下载的,详细见项目主页:http://potrace. ...
- C#反序列化XML异常:在 XML文档(0, 0)中有一个错误“缺少根元素”
Q: 在反序列化 Xml 字符串为 Xml 对象时,抛出如下异常. 即在 XML文档(0, 0)中有一个错误:缺少根元素. A: 首先看下代码: StringBuilder sb = new Stri ...
- EC笔记:第4部分:21、必须返回对象时,别返回引用
使用应用可以大幅减少构造函数与析构函数的调用次数,但是引用不可以滥用. 如下: struct St { int a; }; St &func(){ St t; return t; } 在返回t ...
- 使用HTML5的cavas实现的一个画板
<!DOCTYPE html><html><head> <meta charset="utf-8"> <meta http-e ...
- Android—万能ListView适配器
ListView是开发中最常用的控件了,但是总是会写重复的代码,浪费时间又没有意义. 最近参考一些资料,发现一个万能ListView适配器,代码量少,节省时间,总结一下分享给大家. 首先有一个自定义的 ...
- centos7 安装时候检测不到空余硬盘的解决办法
我是用U盘装的centos,在进行硬盘规划时,看到硬盘的可用空间太少 这是因为我的硬盘以前装的是windows系统,硬盘几乎都已经被windows 操作系统给使用了,剩余空间也只会是windows用剩 ...
- Hilbert-Huang Transform(希尔伯特-黄变换)
在我们正式开始讲解Hilbert-Huang Transform之前,不妨先来了解一下这一伟大算法的两位发明人和这一算法的应用领域 Section I 人物简介 希尔伯特:公认的数学界“无冕之王”,1 ...
- 【译】Meteor 新手教程:在排行榜上添加新特性
原文:http://danneu.com/posts/6-meteor-tutorial-for-fellow-noobs-adding-features-to-the-leaderboard-dem ...