Pandas简易入门(四)
本节主要介绍一下Pandas的另一个数据结构:DataFrame,本文的内容来源:https://www.dataquest.io/mission/147/pandas-internals-dataframes
在上一节中已经介绍过了Series对象,Series对象可以理解为由一列索引和一列值,共两列数据组成的结构。而DataFrame就是由一列索引和多列值组成的结构,其中,在DataFrame中的每一列都是一个Series对象。
行选择
不管何时,你调用了一个方法返回或者打印一个DataFrame时,最左边的一列必然是索引值,可以通过index属性来直接访问DataFrame的索引值,本节所用的数据来源于:https://github.com/fivethirtyeight/data/tree/master/fandango
import pandas as pd
fandango = pd.read_csv('fandango_score_comparison.csv')
# print(fandango.head(2)) 输出前两行
print(fandango.index) # 打印索引列的值
这是原始的数据:
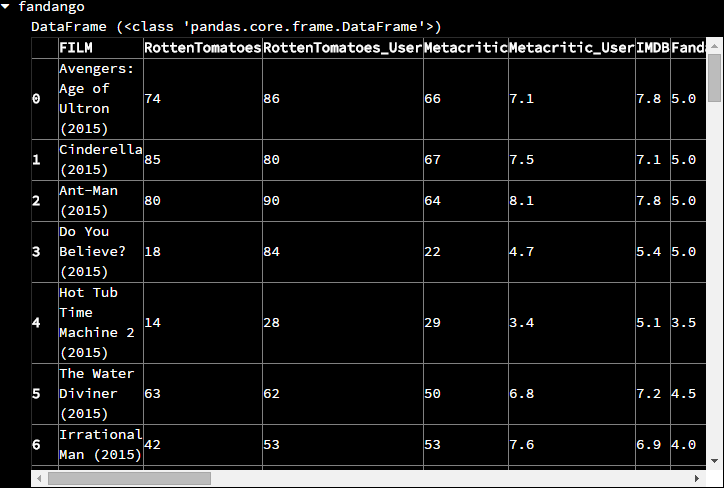
在Series中,每一个索引都对应着一个值,在DataFrame中,每一个索引则对应着一行的数据,可以通过几种方法来选择多数据
# 选择前五行 fandango[0:5] # 选择索引号140及其以后的行 fandango[140:] # 只选择索引号为50的那一行 fandango.loc[50] # 选择索引号为45和90的两行 fandango.loc[[45,90]]
总结:要选择连续的多行,就是用列表的切片功能,选择一行就是用loc[]方法或者iloc[]方法(二者的区别可以看我的另一篇博客“Pandas之让人容易混淆的行选择和列选择“)
当选择一行的数据时,Pandas会返回一个Series对象,当选择多行数据时,会返回一个DataFrame对象
自定义索引
Pandas可以使用某一列来重新自定义DataFrame的索引,通过set_index()方法来实现,该方法主要有两个参数:
- inplace,如果设置为True就不会返回一个新的DataFrame,而是直接修改该DataFrame
- drop,如果设置为True,就会移出掉该列的数据
# 我要把电影名称作为该DataFrame的索引
fandango = pd.read_csv('fandango_score_comparison.csv')
fandango_films = fandango.set_index('FILM', inplace=False, drop=True)
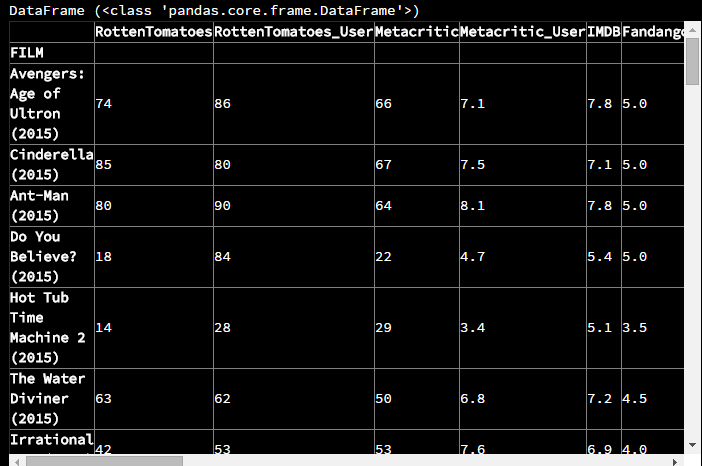
可以看到索引值已经变了,并且该DataFrame中也移除了名为FILM的列(该列变成了索引)
使用了自定义的索引后,类似于之前的行选择一样进行选择,只是把整数索引换成了电影名称而已,例如
# 使用切片或者loc[]函数 fandango_films["Avengers: Age of Ultron (2015)":"Hot Tub Time Machine 2 (2015)"] fandango_films.loc["Avengers: Age of Ultron (2015)":"Hot Tub Time Machine 2 (2015)"] # 指定要返回的电影 fandango_films.loc['Kumiko, The Treasure Hunter (2015)'] # 选择要返回的多部电影 movies = ['Kumiko, The Treasure Hunter (2015)', 'Do You Believe? (2015)', 'Ant-Man (2015)'] fandango_films.loc[movies]
Apply方法
apply()方法是运行在Series对象中的,而Pandas中任何单独一列或者单独一行的数据就是一个Series对象,apply()方法中要传递的是一个向量运算方法
如果该方法返回一个单独的值(譬如将整列(行)的值相加),那么就会返回一个Series,该Series保存的是全部列的运行结果,如下
import numpy as np # 得出每一列的数据类型 types = fandango_films.dtypes # 选择具有浮点数据的那些列 float_columns = types[types.values == 'float64'].index float_df = fandango_films[float_columns]
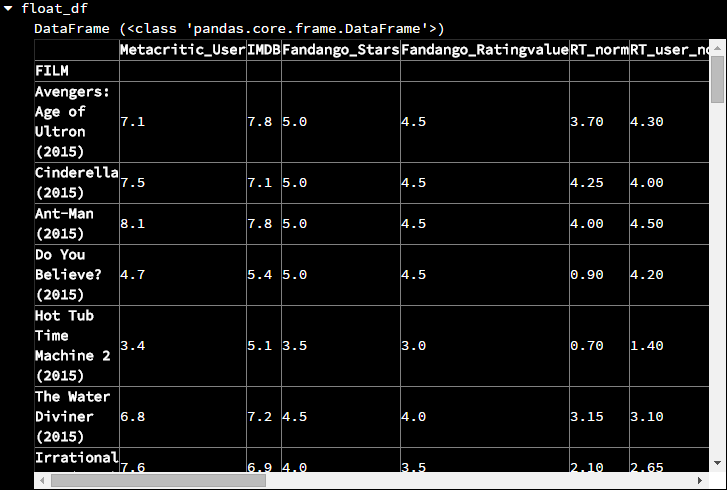
# 对选择的列计算总分,在lambda中的x是一个Series,代表了某一列 count = float_df.apply(lambda x: np.sum(x))
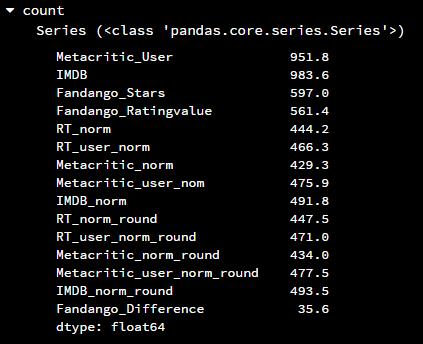
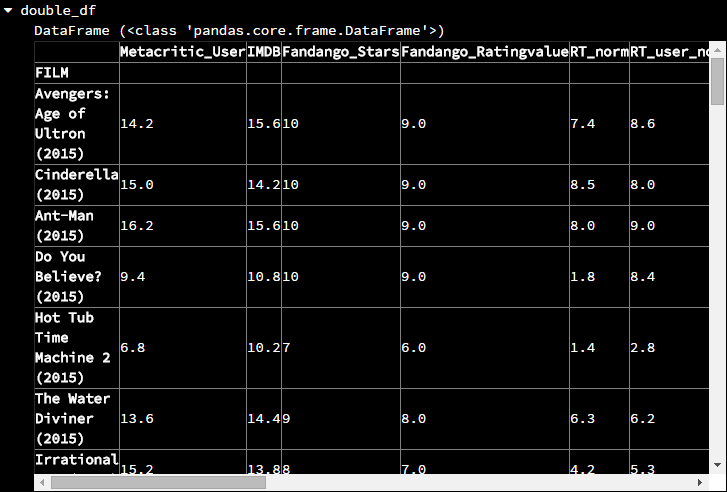
如果该方法没有合并运算结果(譬如将整列(行)的值都分别乘2),那么就会返回一个DataFrame。如下
double_df = float_df.apply(lambda x: x*2)
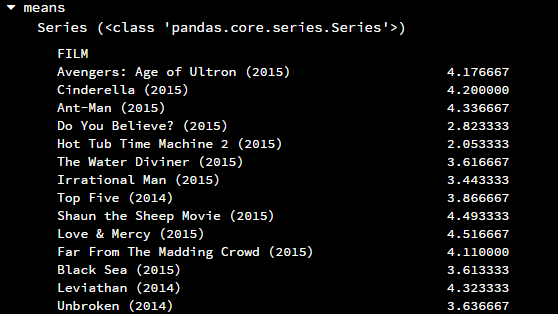
如果要在行上使用apply()方法,只要指定参数axis = 1即可
# 计算每部电影的平均分 means = float_df.apply(lambda x: np.mean(x), axis = 1)
Pandas简易入门(四)的更多相关文章
- Pandas简易入门(二)
目录: 处理缺失数据 制作透视图 删除含空数据的行和列 多行索引 使用apply函数 本节主要介绍如何处理缺失的数据,可以参考原文:https://www. ...
- Pandas简易入门(三)
本节主要介绍一下Pandas的数据结构,本文引用的网址:https://www.dataquest.io/mission/146/pandas-internals-series 本文所使用的数据来自于 ...
- Pandas简易入门(一)
目录: 读取数据 索引 选择数据 简单运算 声明,本文引用于:https://www.dataquest.io/mission/8/introduction-to-pandas (建议阅读原文) Pa ...
- 机器学习简易入门(四)- logistic回归
摘要:使用logistic回归来预测某个人的入学申请是否会被接受 声明:(本文的内容非原创,但经过本人翻译和总结而来,转载请注明出处) 本文内容来源:https://www.dataquest.io/ ...
- Python pandas快速入门
Python pandas快速入门2017年03月14日 17:17:52 青盏 阅读数:14292 标签: python numpy 数据分析 更多 个人分类: machine learning 来 ...
- crontab简易入门
前言 crontab是Unix和Linux用于设置周期性被执行的指令,是互联网很常用的技术,很多任务都会设置在crontab循环执行,如果不使用crontab,那么任务就是常驻程序,这对你的程序要求比 ...
- 【原创】NIO框架入门(四):Android与MINA2、Netty4的跨平台UDP双向通信实战
概述 本文演示的是一个Android客户端程序,通过UDP协议与两个典型的NIO框架服务端,实现跨平台双向通信的完整Demo. 当前由于NIO框架的流行,使得开发大并发.高性能的互联网服务端成为可能. ...
- python学习笔记--Django入门四 管理站点--二
接上一节 python学习笔记--Django入门四 管理站点 设置字段可选 编辑Book模块在email字段上加上blank=True,指定email字段为可选,代码如下: class Autho ...
- Swift语法基础入门四(构造函数, 懒加载)
Swift语法基础入门四(构造函数, 懒加载) 存储属性 具备存储功能, 和OC中普通属性一样 // Swfit要求我们在创建对象时必须给所有的属性初始化 // 如果没办法保证在构造方法中初始化属性, ...
随机推荐
- TCP/IP协议原理与应用笔记19:IP分组的交付和路由选择
1. 引言: (1)互联网结构: 信息:IP分组(直接广播地址(Directed Broadcast Address),其指定了在一个特定网络中的"所有主机".) 节点:路由器.主 ...
- WdatePicker时间控件联动选择
$("#txtStartTime").bind("click focus", function () { var endtimeTf = $dp.$('txtE ...
- python(7)– 类的反射
python中的反射功能是由以下四个内置函数提供:hasattr.getattr.setattr.delattr,改四个函数分别用于对对象内部执行:检查是否含有某成员.获取成员.设置成员.删除成员. ...
- linux - 文本处理 及 正则表达式
先新建一个文件,并写入一些东西,方便测试, 从passwd里复制几行吧 $ /etc/passwd > passwd t$ ll 总用量 drwxrwxr-x huanghao huanghao ...
- zoj 2676 网络流+01分数规划
思路: 这题的结论得要看amber的论文,结论就是将求f(x)/b(x)最小转化为求min(f(x)-b(x)*λ),其中x为S集的解空间,f(x)为解的边权和,b(x)为解的边数, λ=f(x)/b ...
- sqlserver2005数据库18456错误(转)
第一步.以windows验证模式进入数据库管理器.第二步:右击sa,选择属性:在常规选项卡中,重新填写密码和确认密码(改成个好记的).把强制实施密码策略去掉.第三步:点击状态选项卡:勾选授予和启用.然 ...
- javascript事件学习笔记
事件冒泡 并不是所有的事件都支持事件冒泡,比如submit ,focus,blur不支持事件冒泡,mouseover,mouseout虽然支持冒泡,但是一般不用,因为需要经常计算元素的位置,消耗比较大 ...
- <转>HTML+CSS总结/深入理解CSS盒子模型
原文地址:http://www.chinaz.com/design/2010/1229/151993.shtml 前言:前阵子在做一个项目时,在页面布局方面遇到了一点小问题,于是上stackoverf ...
- C#算法基础之快速排序
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- UpdatePanel中执行js
在UpdatePanel中,直接使用Page.ClientScript.RegisterStartupScript的方式执行javascript,会导致无法执行.原因可能是因为RegisterStar ...