大数据学习——mapreduce汇总手机号上行流量下行流量总流量
时间戳 手机号 MAC地址 ip 域名 上行流量包个数 下行 上行流量 下行流量 http状态码
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157993044 18211575961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 视频网站 15 12 1527 2106 200
1363157995074 84138413 5C-0E-8B-8C-E8-20:7DaysInn 120.197.40.4 122.72.52.12 20 16 4116 1432 200
1363157993055 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
1363157995033 15920133257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.360.cn 信息安全 20 20 3156 2936 200
1363157983019 13719199419 68-A1-B7-03-07-B1:CMCC-EASY 120.196.100.82 4 0 240 0 200
1363157984041 13660577991 5C-0E-8B-92-5C-20:CMCC-EASY 120.197.40.4 s19.cnzz.com 站点统计 24 9 6960 690 200
1363157973098 15013685858 5C-0E-8B-C7-F7-90:CMCC 120.197.40.4 rank.ie.sogou.com 搜索引擎 28 27 3659 3538 200
1363157986029 15989002119 E8-99-C4-4E-93-E0:CMCC-EASY 120.196.100.99 www.umeng.com 站点统计 3 3 1938 180 200
1363157992093 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 15 9 918 4938 200
1363157986041 13480253104 5C-0E-8B-C7-FC-80:CMCC-EASY 120.197.40.4 3 3 180 180 200
1363157984040 13602846565 5C-0E-8B-8B-B6-00:CMCC 120.197.40.4 2052.flash2-http.qq.com 综合门户 15 12 1938 2910 200
1363157995093 13922314466 00-FD-07-A2-EC-BA:CMCC 120.196.100.82 img.qfc.cn 12 12 3008 3720 200
1363157982040 13502468823 5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 综合门户 57 102 7335 110349 200
1363157986072 18320173382 84-25-DB-4F-10-1A:CMCC-EASY 120.196.100.99 input.shouji.sogou.com 搜索引擎 21 18 9531 2412 200
1363157990043 13925057413 00-1F-64-E1-E6-9A:CMCC 120.196.100.55 t3.baidu.com 搜索引擎 69 63 11058 48243 200
1363157988072 13760778710 00-FD-07-A4-7B-08:CMCC 120.196.100.82 2 2 120 120 200
1363157985066 13726238888 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
1363157993055 13560436666 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200 作业:1/统计每一个用户(手机号)所耗费的总上行流量、下行流量,总流量
map
读一行,切分字段
抽取手机号,上行流量 下行流量
context.write(手机号,bean) reduce 2/得出上题结果的基础之上再加一个需求:将统计结果按照总流量倒序排序 3/将流量汇总统计结果按照手机归属地不同省份输出到不同文件中
map
读一行,切分字段
抽取手机号,上行流量 下行流量
context.write(手机号,bean) map输出的数据要分成6个区
重写partitioner,让相同归属地的号码返回相同的分区号int 6省 跑6个reduce task
reduce
拿到一个号码所有数据
遍历,累加
输出
新建一个maven项目
项目结构如下
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.cyf</groupId>
<artifactId>FlowSum</artifactId>
<packaging>jar</packaging>
<version>1.0</version> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.4</version>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>cn.itcast.mapreduce.FlowSum</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build> </project>
FlowBean.java
package cn.itcast.mapreduce; import org.apache.hadoop.io.Writable; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; /**
* Created by Administrator on 2019/1/4.
*/
public class FlowBean implements Writable { private long upFlow;
private long downFlow;
private long sumFlow; //序列化框架在反序列化的时候创建对象的实例会去调用我们的无参构造函数
public FlowBean() { } public FlowBean(long upFlow, long downFlow, long sumFlow) {
super();
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = sumFlow;
} public FlowBean(long upFlow, long downFlow) {
super();
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
} public void set(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
} public long getUpFlow() {
return upFlow;
} public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
} public long getDownFlow() {
return downFlow;
} public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
} public long getSumFlow() {
return sumFlow;
} public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
} //序列化的方法
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow); } //反序列化的方法
//注意:字段的反序列化的顺序跟序列化的顺序必须保持一致
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readLong();
this.downFlow = in.readLong();
this.sumFlow = in.readLong(); } public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
} /**
* 这里进行我们自定义比较大小的规则
*/ public int compareTo(FlowBean o) { return (int) (o.getSumFlow() - this.getSumFlow());
}
}
FlumSum.java
package cn.itcast.mapreduce; import java.io.IOException; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; /**
* Created by Administrator on 2019/1/4.
*/
public class FlowSum {
//在kv中传输我们的自定义的对象是可以的 ,不过必须要实现hadoop的序列化机制 也就是implement Writable
public static class FlowSumMapper extends Mapper<LongWritable, Text, Text, FlowBean> { Text k = new Text();
FlowBean v = new FlowBean(); @Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException { //将读取到的每一行数据进行字段的切分
String line = value.toString();
String[] fields = StringUtils.split(line, "\t"); //抽取我们业务所需要的字段
String phoneNum = fields[1];
long upFlow = Long.parseLong(fields[fields.length - 3]);
long downFlow = Long.parseLong(fields[fields.length - 2]); k.set(phoneNum);
v.set(upFlow, downFlow); context.write(k, v); }
} public static class FlowSumReducer extends Reducer<Text, FlowBean, Text, FlowBean> { FlowBean v = new FlowBean(); //这里reduce方法接收到的key就是某一组《a手机号,bean》《a手机号,bean》 《b手机号,bean》《b手机号,bean》当中的第一个手机号
//这里reduce方法接收到的values就是这一组kv对中的所以bean的一个迭代器
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context)
throws IOException, InterruptedException { long upFlowCount = 0;
long downFlowCount = 0; for (FlowBean bean : values) {
upFlowCount += bean.getUpFlow();
downFlowCount += bean.getDownFlow();
}
v.set(upFlowCount, downFlowCount);
context.write(key, v);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf); job.setJarByClass(FlowSum.class); //告诉程序,我们的程序所用的mapper类和reducer类是什么
job.setMapperClass(FlowSumMapper.class);
job.setReducerClass(FlowSumReducer.class); //告诉框架,我们程序输出的数据类型
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(FlowBean.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class); //告诉框架,我们程序使用的数据读取组件 结果输出所用的组件是什么
//TextInputFormat是mapreduce程序中内置的一种读取数据组件 准确的说 叫做 读取文本文件的输入组件
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class); //告诉框架,我们要处理的数据文件在那个路劲下
FileInputFormat.setInputPaths(job, new Path("/flowsum/input")); //告诉框架,我们的处理结果要输出到什么地方
FileOutputFormat.setOutputPath(job, new Path("/flowsum/output")); boolean res = job.waitForCompletion(true); System.exit(res ? 0 : 1);
} }
新建 /flowsum/input
hadoop fs -mkdir -p /flowsum/input
数据为3.txt
5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4
--7A--CC-0A:CMCC 120.196.100.99
5C-0E-8B-8B-B1-:CMCC 120.197.40.4
--AC-CD-E6-:CMCC-EASY 120.196.100.99 iface.qiyi.com 视频网站
5C-0E-8B-8C-E8-:7DaysInn 120.197.40.4 122.72.52.12
C4--FE-BA-DE-D9:CMCC 120.196.100.99
5C-0E-8B-C7-BA-:CMCC 120.197.40.4 sug.so..cn 信息安全
-A1-B7---B1:CMCC-EASY 120.196.100.82
5C-0E-8B--5C-:CMCC-EASY 120.197.40.4 s19.cnzz.com 站点统计
5C-0E-8B-C7-F7-:CMCC 120.197.40.4 rank.ie.sogou.com 搜索引擎
E8--C4-4E--E0:CMCC-EASY 120.196.100.99 www.umeng.com 站点统计
C4--FE-BA-DE-D9:CMCC 120.196.100.99
5C-0E-8B-C7-FC-:CMCC-EASY 120.197.40.4
5C-0E-8B-8B-B6-:CMCC 120.197.40.4 .flash2-http.qq.com 综合门户
-FD--A2-EC-BA:CMCC 120.196.100.82 img.qfc.cn
5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 综合门户
--DB-4F--1A:CMCC-EASY 120.196.100.99 input.shouji.sogou.com 搜索引擎
-1F--E1-E6-9A:CMCC 120.196.100.55 t3.baidu.com 搜索引擎
-FD--A4-7B-:CMCC 120.196.100.82
-FD--A4--B8:CMCC 120.196.100.82 i02.c.aliimg.com
C4--FE-BA-DE-D9:CMCC 120.196.100.99
把数据放在 /flowsum/input 目录下
hadoop fs -put 3.txt /flowsum/input
把打包后的jar上传

运行
hadoop jar FlowSum-1.0.jar cn.itcast.mapreduce.FlowSum
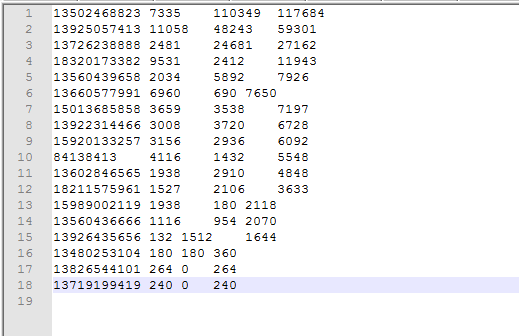
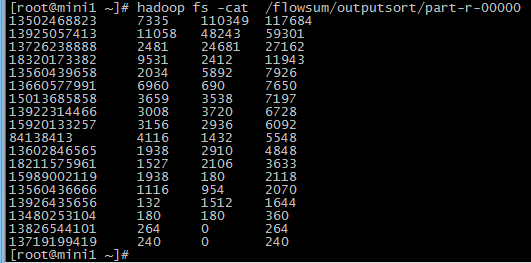
结果如下
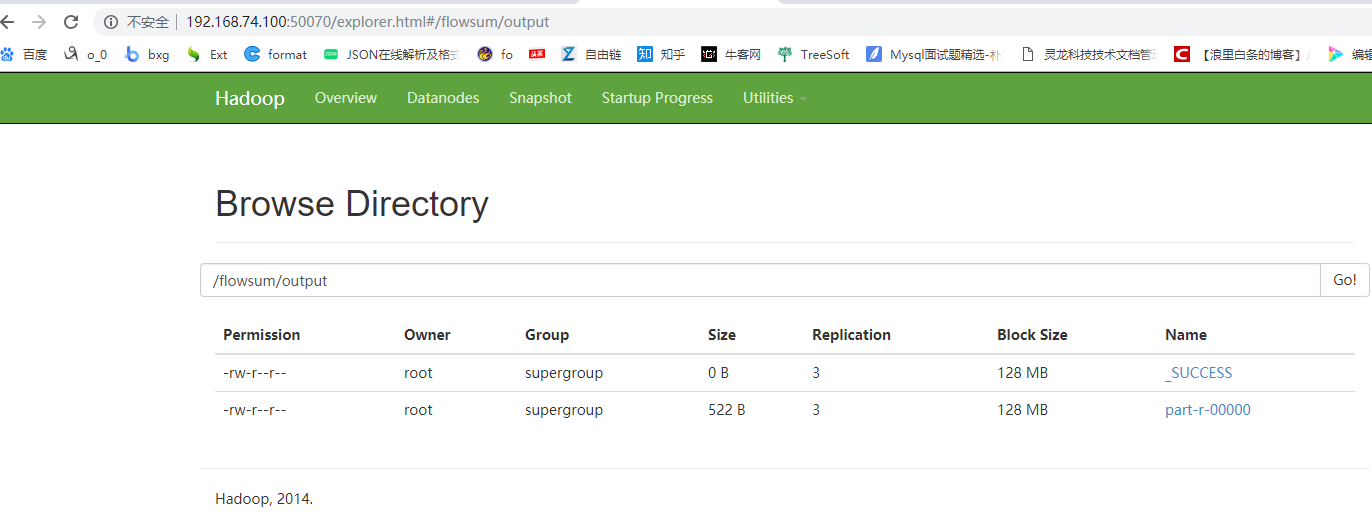


倒序排列效果
大数据学习——mapreduce汇总手机号上行流量下行流量总流量的更多相关文章
- 大数据学习——mapreduce运营商日志增强
需求 1.对原始json数据进行解析,变成普通文本数据 2.求出每个人评分最高的3部电影 3.求出被评分次数最多的3部电影 数据 https://pan.baidu.com/s/1gPsQXVYSQE ...
- 大数据学习——mapreduce案例join算法
需求: 用mapreduce实现select order.orderid,order.pdtid,pdts.pdt_name,oder.amount from orderjoin pdtson ord ...
- 大数据学习——mapreduce学习topN问题
求每一个订单中成交金额最大的那一笔 top1 数据 Order_0000001,Pdt_01,222.8 Order_0000001,Pdt_05,25.8 Order_0000002,Pdt_05 ...
- 大数据学习——mapreduce共同好友
数据 commonfriends.txt A:B,C,D,F,E,O B:A,C,E,K C:F,A,D,I D:A,E,F,L E:B,C,D,M,L F:A,B,C,D,E,O,M G:A,C,D ...
- 大数据学习——mapreduce倒排索引
数据 a.txt hello jerry hello tom b.txt allen tom allen jerry allen hello c.txt hello jerry hello tom 1 ...
- 大数据学习——mapreduce程序单词统计
项目结构 pom.xml文件 <?xml version="1.0" encoding="UTF-8"?> <project xmlns=&q ...
- 大数据学习——MapReduce学习——字符统计WordCount
操作背景 jdk的版本为1.8以上 ubuntu12 hadoop2.5伪分布 安装 Hadoop-Eclipse-Plugin 要在 Eclipse 上编译和运行 MapReduce 程序,需要安装 ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 【机器学习实战】第15章 大数据与MapReduce
第15章 大数据与MapReduce 大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力. 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则 ...
随机推荐
- Educational Codeforces Round 20 A
Description You are given matrix with n rows and n columns filled with zeroes. You should put k ones ...
- Hibernate通过实体对象对应数据库表信息
Hibernate通过实体对象对应数据库表信息,包括:数据库表名称.主键列名.非主键列名等. 获取对象映射缓存管理类: AbstractEntityPersister aep = (AbstractE ...
- php输出中文字符
中文字符不可以使用imagettftext()函数在图片中直接输出,如果要输出中文字符,需要先使用iconv()函数对中文字符进行编码,语法格式如下:string iconv ( string $in ...
- PoolManager插件(转载)
http://www.xuanyusong.com/archives/2974 前几天我在博客里面分享了为什么Unity实例化很慢的原因,并且也分享了一个缓存池的工具.有朋友给我留言说PoolMana ...
- C#实现为类和函数代码自动添加版权注释信息的方法
这篇文章主要介绍了C#实现为类和函数代码自动添加版权注释信息的方法,主要涉及安装文件的修改及函数注释模板的修改,需要的朋友可以参考下 本文实例讲述了C#实现为类和函数代码自动添加版权注释信息的方法 ...
- python中一些函数应用
items将一个字典以列表的形式返回,因为字典是无序的,所以返回的列表也是无序的. 例如:a = {"a":1,"b":2} a.items 就是 a ...
- codevs 1043 方格取数 2000年NOIP全国联赛提高组
时间限制: 1 s 空间限制: 128000 KB 题目等级 : 钻石 Diamond 题目描述 Description 设有N*N的方格图(N<=10,我们将其中的某些方格中填入正整数,而 ...
- MySQL数据表查询操作
准语法结构:编写DQL时一定要严格按照此语法的顺序来实现!/* SELECT [ALL | DISTINCT] ALL表示查询出所有的内容 DISTINCT 去重 {* | 表名.* | 表名.字段名 ...
- Mathematics-基础:1+2+3+……+n
设Sn=1+2+3+……+n-1+n则有Sn=n+n-1+……+3+2+1两式相加得2Sn=(n+1)+(n+1)+……+(n+1)2Sn=n×(n+1)Sn=n×(n+1)/2
- 二分 || UOJ 148 跳石头
L距离中有n块石头,位置在d[i], 移走m块,使从起点0跳到终点l时,每次跳跃的最小距离最大,求这个最小距离 *解法:想到二分(想不到),对要求的结果进行二分,于是对最小距离二分== #includ ...