Python orm基础
ORM 对象映射关系程序。
通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用sql语言。
orm的优点:
- 隐藏了数据访问细节,“封闭”的通用数据库交互,ORM的核心。他使得我们的通用数据库交互变得简单易行,并且完全不用考虑该死的SQL语句。快速开发,由此而来。
- ORM使我们构造固化数据结构变得简单易行。
缺点:
- 无可避免的,自动化意味着映射和关联管理,代价是牺牲性能(早期,这是所有不喜欢ORM人的共同点)。现在的各种ORM框架都在尝试使用各种方法来减轻这块(LazyLoad,Cache),效果还是很显著的。
最有名的ORM框架是SQLAlchemy,系统中没有该模块的需要安装 pip install sqlalchemy (或easy_install SQLAlchemy)
如果在pip install sqlalchemy 中报ReadTimeoutError: HTTPSConnectionPool(host='files.pythonhosted.org'错,需要先设置超时时间:pip --default-timeout=100 install -U Pillow,再重新安装 pip install sqlalchemy,通过imort sqlalchemy验证是否安装正常。
ORM框架SQLAlchemy 使用,创建表:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#conding:utf-8import sqlalchemyfrom sqlalchemy import create_enginefrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import Column,Integer,String #区分大小写#创建连接engine=create_engine("mysql+pymysql://root:123456@localhost/ceshi",encoding='utf-8',echo=True)#生成orm基类base=declarative_base()class user(base): __tablename__ = 'users' #表名 id = Column(Integer, primary_key=True) name = Column(String(32)) password = Column(String(64))base.metadata.create_all(engine) #创建表结构 |
注:pymysql设置编码字符集一定要在数据库访问的URL上增加?charset=utf8,否则数据库的连接就不是utf8的编码格式
|
1
|
engine=create_engine("mysql+pymysql://root:123456@localhost/ceshi",encoding='utf-8',echo=True) |
ORM框架SQLAlchemy 使用,插入数据:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
#conding:utf-8import sqlalchemyfrom sqlalchemy import create_enginefrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import Column,Integer,String #区分大小写from sqlalchemy.orm import sessionmaker#创建连接engine=create_engine("mysql+pymysql://root:123456@localhost/ceshi",encoding='utf-8',echo=True)#生成orm基类base=declarative_base()class user(base): __tablename__ = 'users' #表名 id = Column(Integer, primary_key=True) name = Column(String(32)) password = Column(String(64))base.metadata.create_all(engine) #创建表结构Session_class=sessionmaker(bind=engine) ##创建与数据库的会话,class,不是实例Session=Session_class() #生成session实例user_obj = user(name="rr",password="123456") #插入你要创建的数据对象,每执行一次都会新增一次数据。print user_obj.name,user_obj.id #此时还没创建对象呢,不信你打印一下id发现还是NoneSession.add(user_obj) #把要创建的数据对象添加到这个session里print user_obj.name,user_obj.id #此时也依然还没创建Session.commit() #提交,使前面修改的数据生效。 |
结果:
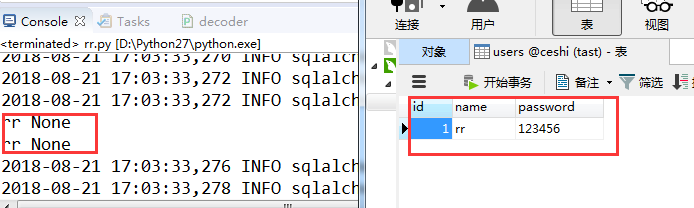
查询:
|
1
2
3
|
my_user = Session.query(user).filter_by(name="ee").first() #创建查询对象print(my_user.id,my_user.name,my_user.password) #输出查询内容print my_user #内存地址 |
结果:

修改:
|
1
2
3
|
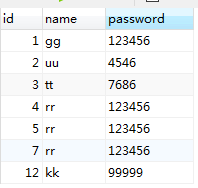
my_user = Session.query(user).filter_by(name="yy").first() #根据指定条件创建符合条件的对象my_user.name='uu' #将name='yy'的name修改为uuprint(my_user.id,my_user.name,my_user.password) #输出查询内容 |
结果:

参考数据表:
回滚:
|
1
2
3
4
5
6
7
|
user_obj = user(name="kk",password="99999") #插入你要创建的数据对象Session.add(user_obj) #把要创建的数据对象添加到这个session里my_user = Session.query(user).filter_by(name="rr").first() #根据指定条件创建符合条件的对象,first()是指name='rr'的第一条记录my_user.name="gg" #将name='yy'的name修改为uuprint(Session.query(user).filter(user.name.in_(["gg","kk"])).all()) #显示修改后的数据Session.rollback() #回滚print(Session.query(user).filter(user.name.in_(["gg","kk"])).all()) #显示回滚后的内容 |
结果:

获取所有数据
|
1
|
print Session.query(user.id,user.name).all() #只显示id,name |
结果:

多条件查询
|
1
2
|
objs = Session.query(user).filter(user.id>0).filter(user.id<=3).all() #注意:filter()中的关键字不能是表达式user.id=0print objs |
filter的关系相当于 user.id >0 AND user.id <=3 的效果
结果:

统计和分组
|
1
2
|
objs = Session.query(user).filter(user.name.like('r%')).count() #统计print objs |
结果:

|
1
2
|
from sqlalchemy import funcprint(Session.query(func.count(user.name),user.name).group_by(user.name).all() ) #分组 |
结果:
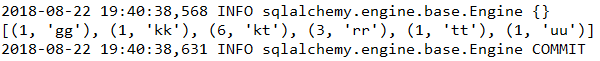
外键关联
参照表:两张表是一对多的关系。
|
1
|
users(一) |
addresses(多)
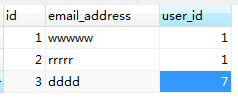
创建表addresses,将users表中的id作为addresses表的外键。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
import sqlalchemyfrom sqlalchemy import create_enginefrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import Column,Integer,String,ForeignKey #区分大小写from sqlalchemy.orm import sessionmaker,relationship#创建连接engine=create_engine("mysql+pymysql://root:123456@localhost/ceshi",encoding='utf-8',echo=True)#生成orm基类base=declarative_base()class user(base): __tablename__ = 'users' #表名 id = Column(Integer, primary_key=True) name = Column(String(32)) password = Column(String(64)) def __repr__(self): return "<user(id='%d',name='%s', password='%s')>" % (self.id, self.name, self.password) class Address(base): __tablename__ = 'addresses' id = Column(Integer, primary_key=True) email_address = Column(String(32), nullable=False) user_id = Column(Integer, ForeignKey('users.id')) user = relationship("user", backref="addresses") '''允许你在user表里通过backref字段反向查出所有它在addresses表里的关联项,在内存中创建。在addresses表中可以使用user来查询users表中的数据,在users表中可以使用backref后的addresses来查询assresses表中的数据。''' def __repr__(self): return "<Address(email_address='%s',id='%d',user_id='%d')>" % (self.email_address,self.id,self.user_id)base.metadata.create_all(engine) #创建表结构Session_class=sessionmaker(bind=engine) #创建与数据库的会话,class,不是实例Session=Session_class() #生成session实例obj = Session.query(user).first()print obj.addresses #在users表里面通过addresses来查询addresses表中的数据。for i in obj.addresses: print i addr_obj = Session.query(Address).first()print(addr_obj.user) #在addresses表中通过user来查询users表中的数据。print(addr_obj.user.name)Session.commit() #提交,使前面修改的数据生效。 |
结果:

输出的结果1是列表形式,print 多行记录时以列表的形式显示。
注:在定义表的类下面加 def __repr__(self): return ... 是为了在print时输出哪些数据,以及输出后的显示形式。
补充:1.主键:是唯一标识一条记录,不能有重复的,不允许为空,用来保证数据完整性
2.外键:是另一表的主键, 外键可以有重复的, 可以是空值,用来和其他表建立联系用的。所以说,如果谈到了外键,一定是至少涉及到两张表。例如下面这两张表:
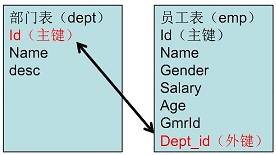
设定条件向指定表中添加记录:
|
1
2
3
4
5
|
obj = Session.query(user).filter(user.name=='ee').all()[0] #设定条件print(obj.addresses)obj.addresses = [Address(email_address="ertttt"), #向addresses表中添加2列。 Address(email_address="dddd")] |
结果:

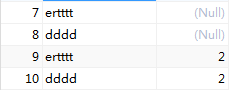
多外键关联
在Customer表有2个字段都关联了Address表
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
class Customer(base): __tablename__ = 'customer' id = Column(Integer, primary_key=True) name = Column(String) billing_address_id = Column(Integer, ForeignKey("address.id")) shipping_address_id = Column(Integer, ForeignKey("address.id")) '''#创建的列billing_address_id、shipping_address_id都作为外键关联address表中id列''' billing_address = relationship("Address") shipping_address = relationship("Address")#创建两个关联项 class Address(base): __tablename__ = 'address' id = Column(Integer, primary_key=True) street = Column(String) city = Column(String) state = Column(String) |
如果报错:
sqlalchemy.exc.AmbiguousForeignKeysError: Could not determine join
condition between parent/child tables on relationshipCustomer.billing_address - there are multiple foreign key|
1
2
|
illing_address = relationship("Address", foreign_keys=[billing_address_id])shipping_address = relationship("Address", foreign_keys=[shipping_address_id]) |
使pymysql分清哪个外键是对应哪个字段。
多对多关系
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
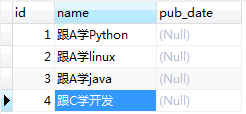
from sqlalchemy import Table, Column, Integer,String,DATE, ForeignKeyfrom sqlalchemy.orm import relationshipfrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import create_enginefrom sqlalchemy.orm import sessionmakerengine=create_engine("mysql+pymysql://root:123456@localhost/ceshi",encoding='utf-8',echo=True)base = declarative_base()book_m2m_author = Table('book_m2m_author', base.metadata, Column('book_id',Integer,ForeignKey('books.id')), Column('author_id',Integer,ForeignKey('authors.id')), ) #创建book_m2m_author表,关联另外两张表。class Book(base): __tablename__ = 'books' id = Column(Integer,primary_key=True) name = Column(String(64)) pub_date = Column(DATE) authors = relationship('Author',secondary=book_m2m_author,backref='books') def __repr__(self): return self.nameclass Author(base): __tablename__ = 'authors' id = Column(Integer, primary_key=True) name = Column(String(32)) def __repr__(self): return self.namebase.metadata.create_all(engine) #创建表结构Session_class=sessionmaker(bind=engine) #创建与数据库的会话,class,不是实例Session=Session_class()b1 = Book(name="跟A学Python")b2 = Book(name="跟A学linux")b3 = Book(name="跟A学java")b4 = Book(name="跟C学开发") a1 = Author(name="A")a2 = Author(name="B")a3 = Author(name="C") b1.authors = [a1,a2] #建立关系b2.authors = [a1,a2,a3]Session.add_all([b1,b2,b3,b4,a1,a2,a3])Session.commit() |
结果:
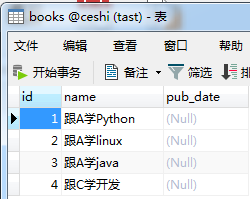
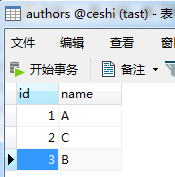
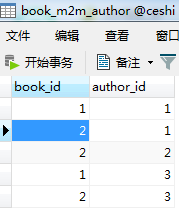
用orm查一下数据
|
1
2
3
4
5
|
book_obj = Session.query(Book).filter_by(name="跟A学Python").first()print(book_obj.name, book_obj.authors)#这里book_obj.authors只输出name,因为定义类Author时在__repr__(self):定义了返回值 author_obj =Session.query(Author).filter_by(name="A").first()print(author_obj.name , author_obj.books) |
结果:


多对多删除
1.通过书删除作者,删除的是关系。
|
1
2
3
|
author_obj =Session.query(Author).filter_by(name="C").first()book_obj = Session.query(Book).filter_by(name="跟A学linux").first()book_obj.authors.remove(author_obj) #通过指定书里删除作者,删除的是关系,作者不受影响。 |
2.删除作者的同时也删除关系。
|
1
2
|
author_obj =Session.query(Author).filter_by(name="A").first()Session.delete(author_obj) #delete删除作者A,关系也会删除掉。 |
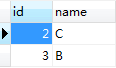
结果:
books表

|
1
|
authors表 |
book_m2m_author表
Python orm基础的更多相关文章
- Python文件基础
===========Python文件基础========= 写,先写在了IO buffer了,所以要及时保存 关闭.关闭会自动保存. file.close() 读取全部文件内容用read,读取一行用 ...
- 3.Python编程语言基础技术框架
3.Python编程语言基础技术框架 3.1查看数据项数据类型 type(name) 3.2查看数据项数据id id(name) 3.3对象引用 备注Python将所有数据存为内存对象 Python中 ...
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- 小白必看Python视频基础教程
Python的排名从去年开始就借助人工智能持续上升,现在它已经成为了第一名.Python的火热,也带动了工程师们的就业热.可能你也想通过学习加入这个炙手可热的行业,可以看看Python视频基础教程,小 ...
- python/ORM操作详解
一.python/ORM操作详解 ===================增==================== models.UserInfo.objects.create(title='alex ...
- Python爬虫基础之requests
一.随时随地爬取一个网页下来 怎么爬取网页?对网站开发了解的都知道,浏览器访问Url向服务器发送请求,服务器响应浏览器请求并返回一堆HTML信息,其中包括html标签,css样式,js脚本等.我们之前 ...
- 零基础学Python--------第2章 Python语言基础
第2章 Python语言基础 2.1 Python语法特点 2.11注释 在Python中,通常包括3种类型的注释,分别是单行注释.多行注释和中文编码声明注释. 1.单行注释 在Python中,使用 ...
- Python学习基础笔记(全)
换博客了,还是csdn好一些. Python学习基础笔记 1.Python学习-linux下Python3的安装 2.Python学习-数据类型.运算符.条件语句 3.Python学习-循环语句 4. ...
- Python数据分析基础教程
Python数据分析基础教程(第2版)(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1_FsReTBCaL_PzKhM0o6l0g 提取码:nkhw 复制这段内容后 ...
随机推荐
- 科普:google的数字图书馆
https://books.google.com/ngrams Google Ngram Viewer,她利用google所拥有的所有图书作为资源,为你提供单词和短语历年使用次数的展示图标.数据化了数 ...
- Node.js+Express搭建博客系统基本环境安装
1.下载安装node.js 官网下载地址:https://nodejs.org/en/download/ 2.安装express. 打开node命令行工具,在命令行中输入:npm install -g ...
- 为什么要在css文件里定义 ul{margin:0;padding:0;}这个选择器?
为什么要在css文件里定义 ul{margin:0;padding:0;}这个选择器? ul标签在FF中默认是有padding值的,而在IE中仅仅有margin默认有值.请看下面不同浏览中对paddi ...
- H264编码技术[3]
H.264的目标应用涵盖了目前大部分的视频服务,如有线电视远程监控.交互媒体.数字电视.视频会议.视频点播.流媒体服务等.H.264为解决不同应用中的网络传输的差异.定义了两层:视频编码层(VCL:V ...
- 【POI2004】【Bzoj2069】T2 洞穴 zaw
T2 洞穴zaw [问题描述] 在 Byte 山的山脚下有一个洞穴入口. 这个洞穴由复杂的洞室经过隧道连接构成. 洞穴的入口是 1 号点.两个洞室要么就通过隧道连接起来,要么就经过若干隧道间接的相连. ...
- 9 Range 实用操作
9.1 剪切.复制和粘贴来移动数据 sourceRange.Cut [Destination] 如果指定Destination,相当于Ctrl^X(sourceRange) & Ctrl^V( ...
- IntelliJ IDEA 缓存和索引介绍
转自:https://www.cnblogs.com/zhanghaibinblogs/p/6722061.html IDEA 在首次加载项目的时候都会创建索引,IDEA 的缓存和索引主要是用来加快文 ...
- ASP.Net 下载大文件的实现 (转)
原文:http://www.cnblogs.com/luisliu/p/4253815.html 当我们的网站需要支持下载大文件时,如果不做控制可能会导致用户在访问下载页面时发生无响应,使得浏览器崩溃 ...
- J20170528-ts
断片 片断 くどい 啰嗦 アノテーション 注释 annotation
- vue seo
最近在实习,刚来没几天,老大没安排什么大事给我,昨天下午说给我一个小任务,要求如下: 1.收集几个流量大的网站(必须是vue做的)页面交互和逻辑尽可能复杂多样2.对比一下各个页面的seo是如何做的3. ...