Python机器学习-分类
- 监督学习下的分类模型,主要运用sklearn实践
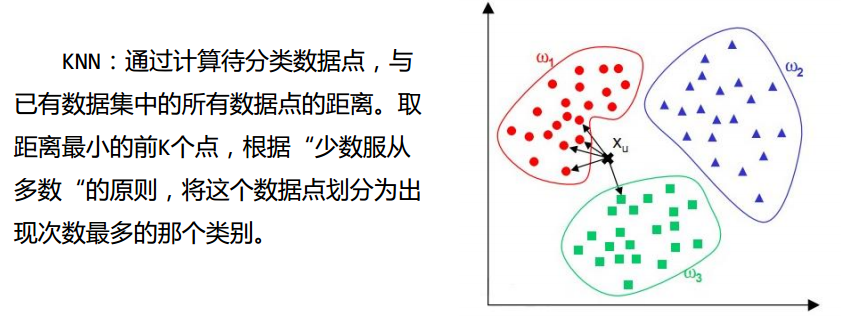
kNN分类器



决策树



朴素贝叶斯




实战一:预测股市涨跌
# -*- coding: utf-8 -*-
"""
Created on Mon Aug 28 15:42:55 2017 @author: Administrator
""" # unit4 classify #数据介绍:
#网易财经上获得的上证指数的历史数据,爬取了20年的上证指数数据。
#实验目的:
#根据给出当前时间前150天的历史数据,预测当天上证指数的涨跌。 import pandas as pd
import numpy as np
from sklearn import svm
from sklearn import cross_validation fpath='F:\RANJIEWEN\MachineLearning\Python机器学习实战_mooc\data\classify\stock\\000777.csv' data=pd.read_csv(fpath,encoding='gbk',parse_dates=[0],index_col=0)
data.sort_index(0,ascending=True,inplace=True) dayfeature=150
featurenum=5*dayfeature
x=np.zeros((data.shape[0]-dayfeature,featurenum+1))
y=np.zeros((data.shape[0]-dayfeature)) for i in range(0,data.shape[0]-dayfeature):
x[i,0:featurenum]=np.array(data[i:i+dayfeature] \
[[u'收盘价',u'最高价',u'最低价',u'开盘价',u'成交量']]).reshape((1,featurenum))
x[i,featurenum]=data.ix[i+dayfeature][u'开盘价'] for i in range(0,data.shape[0]-dayfeature):
if data.ix[i+dayfeature][u'收盘价']>=data.ix[i+dayfeature][u'开盘价']:
y[i]=1
else:
y[i]=0 clf=svm.SVC(kernel='rbf')
result = []
for i in range(5):
x_train, x_test, y_train, y_test = \
cross_validation.train_test_split(x, y, test_size = 0.2)
clf.fit(x_train, y_train)
result.append(np.mean(y_test == clf.predict(x_test)))
print("svm classifier accuacy:")
print(result)
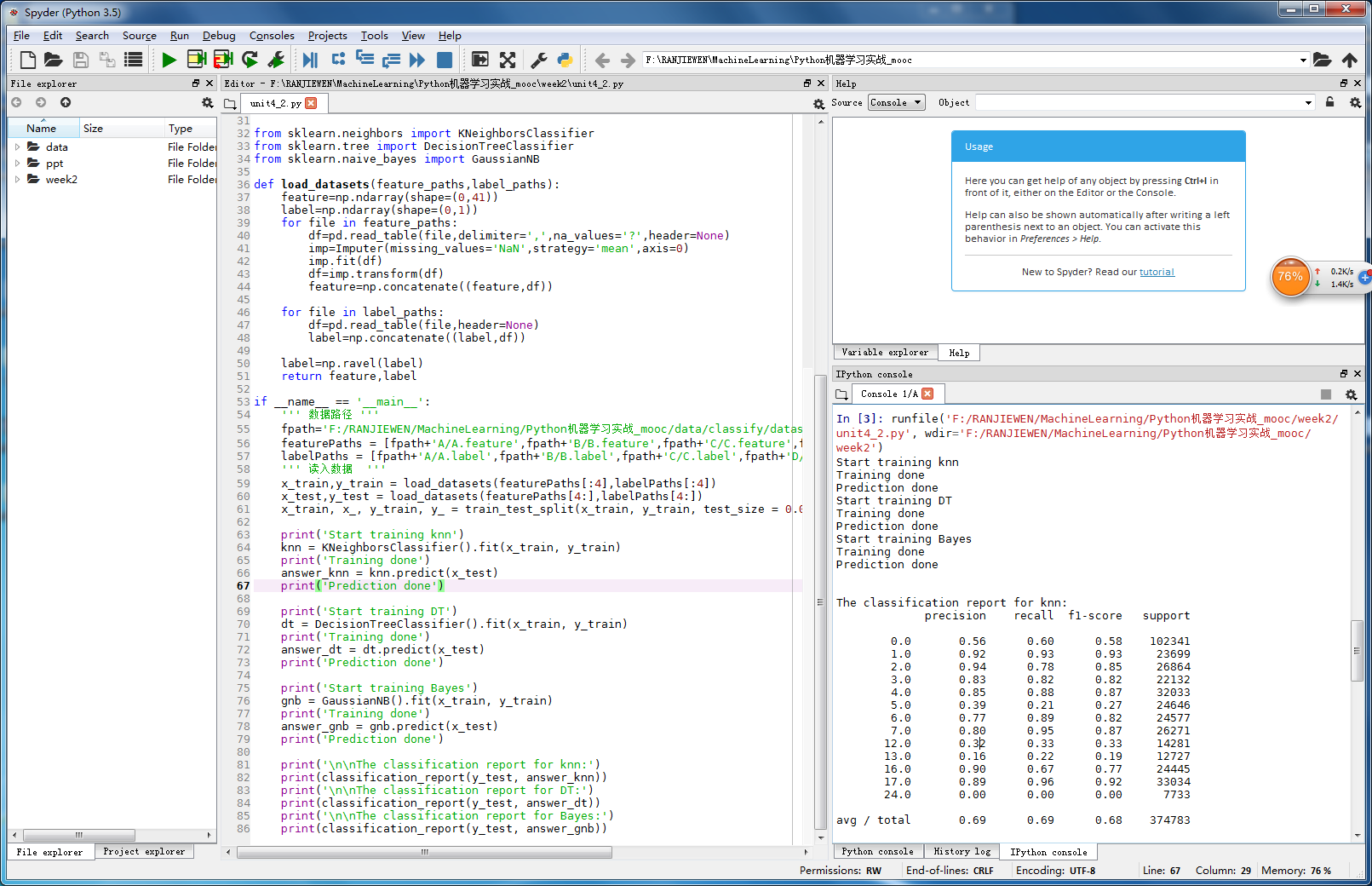
实战二:通过运动传感器采集的数据分析运行状态
# -*- coding: utf-8 -*-
"""
Created on Mon Aug 28 19:41:21 2017 @author: Administrator
""" '''
现在收集了来自 A,B,C,D,E 5位用户的可穿戴设备上的传感器数据,
每位用户的数据集包含一个特征文件(a.feature)和一个标签文件
(a.label)
特征文件中每一行对应一个时刻的所有传感器数值,标签文件中每行记录了
和特征文件中对应时刻的标记过的用户姿态,两个文件的行数相同,相同行
之间互相对应
标签文件内容如图所示,每一行代表与特征文件中对应行的用户姿态类别。
总共有0-24共25种身体姿态,如,无活动状态,坐态、跑态等。标签文件作为
训练集的标准参考准则,可以进行特征的监督学习。 假设现在出现了一个新用户,但我们只有传感器采集的数据,那么该如何得到
这个新用户的姿态呢?
或者对同一用户如果传感器采集了新的数据,怎么样根据新的数据判断当前
用户处于什么样的姿态呢?
''' import pandas as pd
import numpy as np from sklearn.preprocessing import Imputer
from sklearn.cross_validation import train_test_split
from sklearn.metrics import classification_report from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB def load_datasets(feature_paths,label_paths):
feature=np.ndarray(shape=(0,41))
label=np.ndarray(shape=(0,1))
for file in feature_paths:
df=pd.read_table(file,delimiter=',',na_values='?',header=None)
imp=Imputer(missing_values='NaN',strategy='mean',axis=0)
imp.fit(df)
df=imp.transform(df)
feature=np.concatenate((feature,df)) for file in label_paths:
df=pd.read_table(file,header=None)
label=np.concatenate((label,df)) label=np.ravel(label)
return feature,label if __name__ == '__main__':
''' 数据路径 '''
fpath='F:/RANJIEWEN/MachineLearning/Python机器学习实战_mooc/data/classify/dataset/'
featurePaths = [fpath+'A/A.feature',fpath+'B/B.feature',fpath+'C/C.feature',fpath+'D/D.feature',fpath+'E/E.feature']
labelPaths = [fpath+'A/A.label',fpath+'B/B.label',fpath+'C/C.label',fpath+'D/D.label',fpath+'E/E.label']
''' 读入数据 '''
x_train,y_train = load_datasets(featurePaths[:4],labelPaths[:4])
x_test,y_test = load_datasets(featurePaths[4:],labelPaths[4:])
x_train, x_, y_train, y_ = train_test_split(x_train, y_train, test_size = 0.0) print('Start training knn')
knn = KNeighborsClassifier().fit(x_train, y_train)
print('Training done')
answer_knn = knn.predict(x_test)
print('Prediction done') print('Start training DT')
dt = DecisionTreeClassifier().fit(x_train, y_train)
print('Training done')
answer_dt = dt.predict(x_test)
print('Prediction done') print('Start training Bayes')
gnb = GaussianNB().fit(x_train, y_train)
print('Training done')
answer_gnb = gnb.predict(x_test)
print('Prediction done') print('\n\nThe classification report for knn:')
print(classification_report(y_test, answer_knn))
print('\n\nThe classification report for DT:')
print(classification_report(y_test, answer_dt))
print('\n\nThe classification report for Bayes:')
print(classification_report(y_test, answer_gnb))
- result
Python机器学习-分类的更多相关文章
- 吴裕雄 python 机器学习——分类决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 常用python机器学习库总结
开始学习Python,之后渐渐成为我学习工作中的第一辅助脚本语言,虽然开发语言是Java,但平时的很多文本数据处理任务都交给了Python.这些年来,接触和使用了很多Python工具包,特别是在文本处 ...
- [Python] 机器学习库资料汇总
声明:以下内容转载自平行宇宙. Python在科学计算领域,有两个重要的扩展模块:Numpy和Scipy.其中Numpy是一个用python实现的科学计算包.包括: 一个强大的N维数组对象Array: ...
- python机器学习《回归 一》
唠嗑唠嗑 依旧是每一次随便讲两句生活小事.表示最近有点懒,可能是快要考试的原因,外加这两天都有笔试和各种面试,让心情变得没那么安静的敲代码,没那么安静的学习算法.搞得第一次和技术总监聊天的时候都不太懂 ...
- 2016年GitHub排名前20的Python机器学习开源项目(转)
当今时代,开源是创新和技术快速发展的核心.本文来自 KDnuggets 的年度盘点,介绍了 2016 年排名前 20 的 Python 机器学习开源项目,在介绍的同时也会做一些有趣的分析以及谈一谈它们 ...
- [resource]Python机器学习库
reference: http://qxde01.blog.163.com/blog/static/67335744201368101922991/ Python在科学计算领域,有两个重要的扩展模块: ...
- python机器学习实战(一)
python机器学习实战(一) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7140974.html 前言 这篇notebook是关于机器 ...
- python机器学习实战(二)
python机器学习实战(二) 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7159775.html 前言 这篇noteboo ...
- python机器学习实战(三)
python机器学习实战(三) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7277205.html 前言 这篇notebook是关于机器 ...
随机推荐
- CentOS6.5卸载openJDK和安装Sun JDK
CentOS6.5卸载openJDK和安装Sun JDK 最近业务需要,新安装了CentOS6.5系统,在配置tomcat的时候,总是报错找不到jdk中的java.研究了半天,发现应该是openJDK ...
- (转)5个Xcode开发调试技巧
1.Enable NSZombie Objects(开启僵尸对象) Enable NSZombie Objects可能是整个Xcode开发环境中最有用的调试技巧.这个技巧非常非常容易追踪到重复释放的问 ...
- css 标题
纯CSS制作的复古风格的大标题 .vintage{ background: #EEE url(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAQAAAA ...
- Linux下配置MySQL主从复制
一.环境准备 本次准备两台Linux主机,操作系统都为CentOS6.8, 都安装了相同版本的MySQL.(MySQL5.7). 主从服务器的防火墙都开启了3306端口. 相关信息如下: [主服务器] ...
- DRF filter
filter 配置 fiter定义 自定义filter继承BaseFilterBackend,必须重写filter_queryset,返回值为过滤后的queryset filter在GenericAP ...
- 关于springmvc返回json格式数据
1.引入maven依赖 <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifac ...
- 请编写一个方法,返回某集合的所有非空子集。 给定一个int数组A和数组的大小int n,请返回A的所有非空子集。保证A的元素个数小于等于20,且元素互异。各子集内部从大到小排序,子集之间字典逆序排序,见样例。
题解:观察测试样例,会发现每个子集的选择规律与二进制((2^n) - 1)到 1 的顺序生成的规律是一致的,样例中n=3,2^n-1=7,用二进制表示为111,其中每一位的1表示数组中的三个数都选择. ...
- WordPress实现前台登录功能
一.添加登录表单 1.首先在当前主题的目录下新建一个php文件,命名为page-login.php,然后将page.php中的所有代码复制到page-login.php中: 2.删除page-logi ...
- dp的两个不错的题
C - Cheapest Palindrome Keeping track of all the cows can be a tricky task so Farmer John has instal ...
- TMOS_Order_of_Operations_v0.1