爬虫—Ajax数据爬取
一、什么是Ajax
有时候我们使用浏览器查看页面正常显示的数据与使用requests抓取页面得到的数据不一致,这是因为requests获取的是原始的HTML文档,而浏览器中的页面是经过JavaScript处理数据后的结果。这些数据可能是通过Ajax加载的,可能包含HTML文档中,可能经过特定算法计算后生成的。
Ajax,全称为Asynchronous JavaScript and XML,即异步的JavaScript和XML。它是利用JavaScript在保证页面不被刷新,连接不变的情况下服务器交换数据并更新部分网页的技术。
1.示例
浏览网页的时候,我们发现很多网页都有下滑查看更多的选项。比如,就拿新浪微博主页来说。一直往下滑,看到几个微博之后就没有了,而是会出现一个加载的动画,很快就出现了新的微博内容。这个过程就是Ajax加载的过程,如下图:
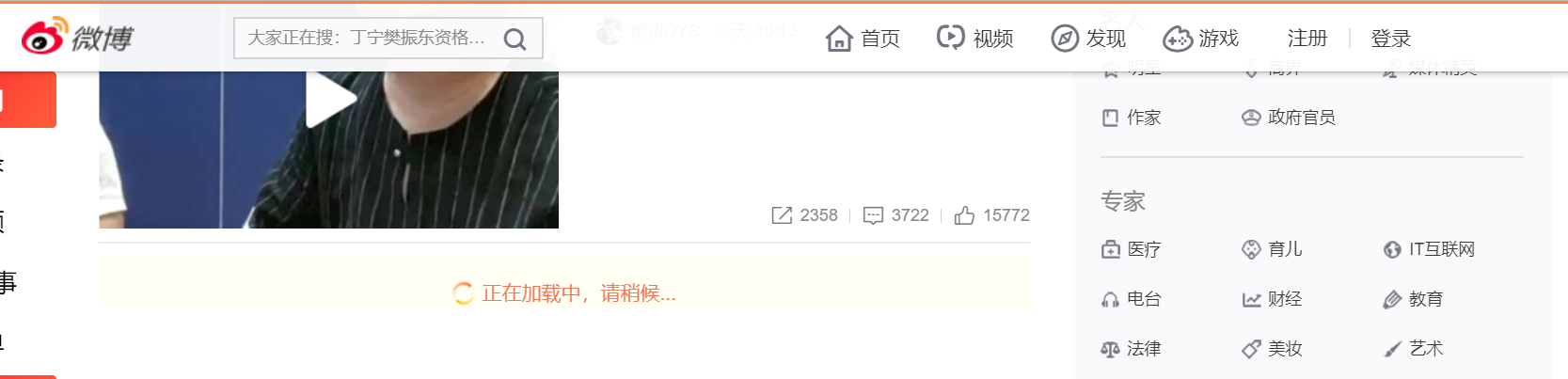
2.基本原理
发送Ajax请求到网页更新的过程可以简单的分为三步:
1.发送请求
2.解析内容
3.渲染页面
♦ 发送请求
var xmlhttp;
if (window.XMLHttpRequest) {
// IE7,Firefox,Chrome,Safari,opera
xmlhttp = new XMLHttpRequest()
} else {
// IE6,IE5
xmlhttp = new ActiveXObject('Microsoft.XMLHTTP');
}
xmlhttp.onreadystatechange = function () {
if (xmlhttp.readyState == 4 && xmlhttp.status == 200) {
document.getElementById("content").innerHTML = xmlhttp.responseText;
}
};
xmlhttp.open('POST', '/ajax', true);
xmlhttp.send()
这是使用JavaScript对Ajax的底层实现,实际上是新建了XMLHttpRequest对象,然后调用onreadystatechange实现设置了监听,然后使用open()和send()方法向某个连接(也就是服务器)发送请求。响应返回时监听对应的方法便触发,解析响应内容。
♦ 解析内容
onreadystatechange对应的属性触发后,利用xmlhttp的responseText属性获取响应内容。
♦渲染网页
解析响应完成之后,通过document.getElementById("content").innerHTML这样的方法对某个元素内部的HTML代码进行更改,从而渲染网页。这样的操作也称为DOM操作,即对Document进行操作。
因此,我们知道了真实的数据都是一次次Ajax请求得到的,如果想要抓取这些数据,需要知道这些请求到底是怎么发送的。之后再使用Python进行模拟发送操作,获取到其中的结果。
二,Ajax方法分析
1.查看请求
使用Chrome浏览器访问新浪微博首页,打开开发者工具。切换到Network选项卡,重新刷新页面,看到非常多的条目。
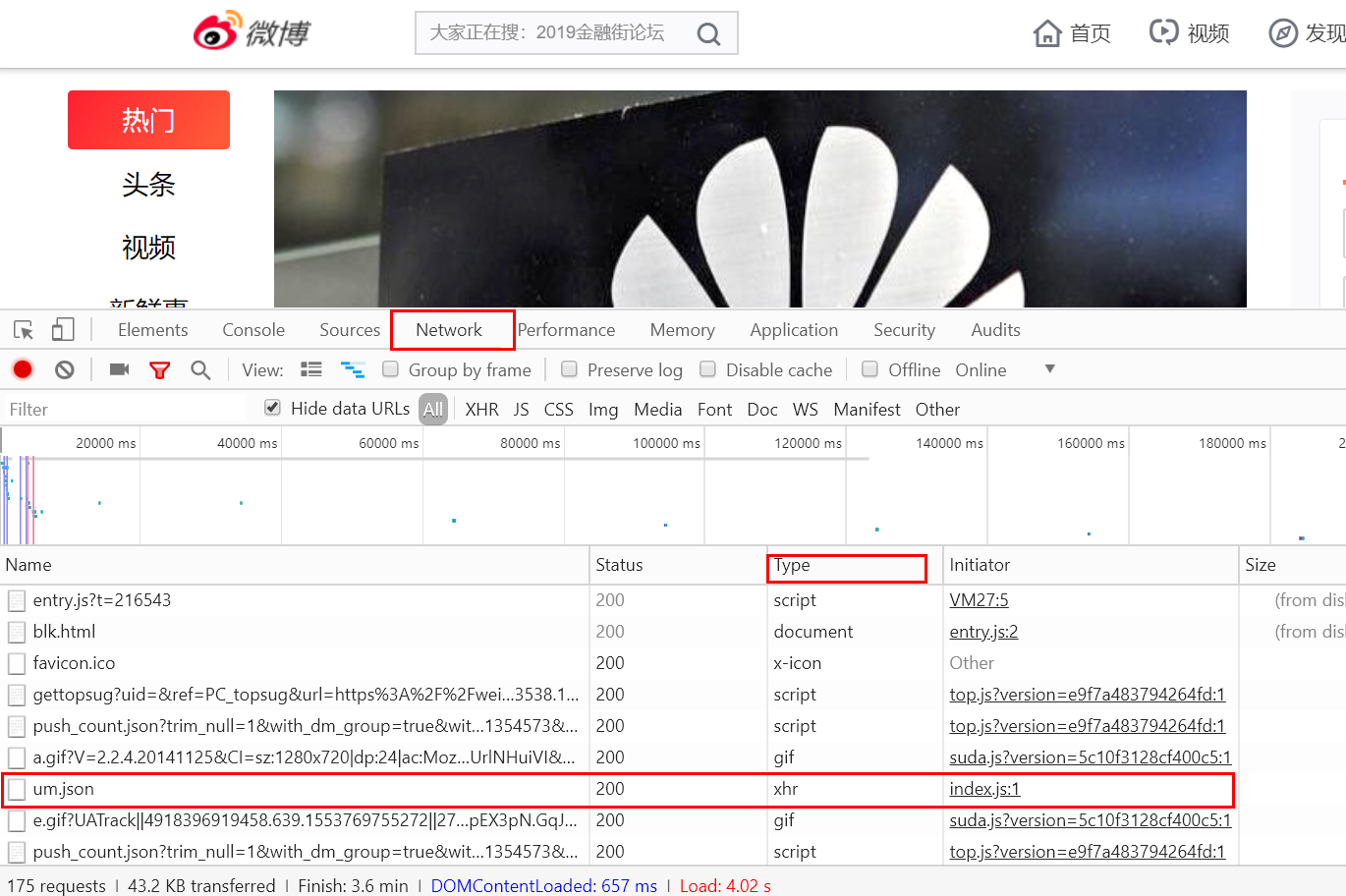
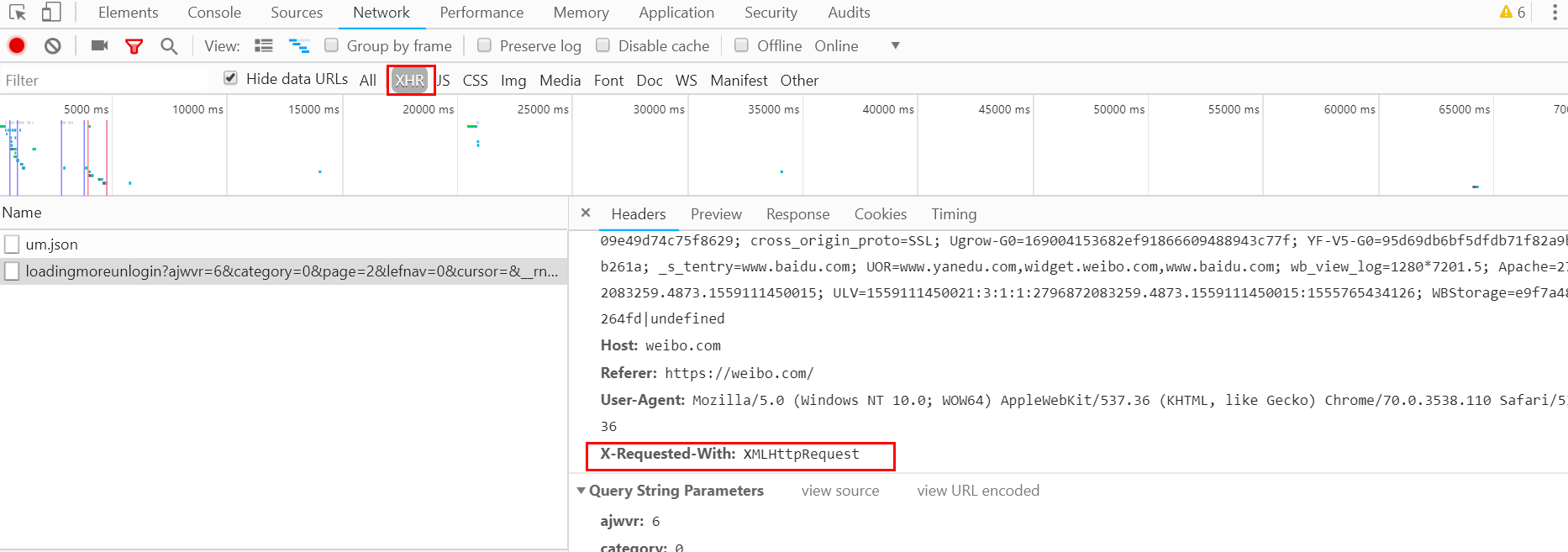
Ajax请求其实有它特殊的请求类型,叫做xhr。在途中Type对应请求类型中,点击图中的XHR可以过滤出所有的xhr请求。找到其中一个xhr的请求,点击进去查看详细内容。其中Request Headers中有一条信息为X-Requested-With:XMLHttpRequest,这就标记了次请求是Ajax请求。如下图
三,Ajax结果提取
1.请求分析
使用开发者工具打开Ajax的XHR过滤器,然后一直向下滑动页面,我们会看到不断有Ajax请求发出。选定其中一个请求,分析其参数信息,进入请求详情。如下图:
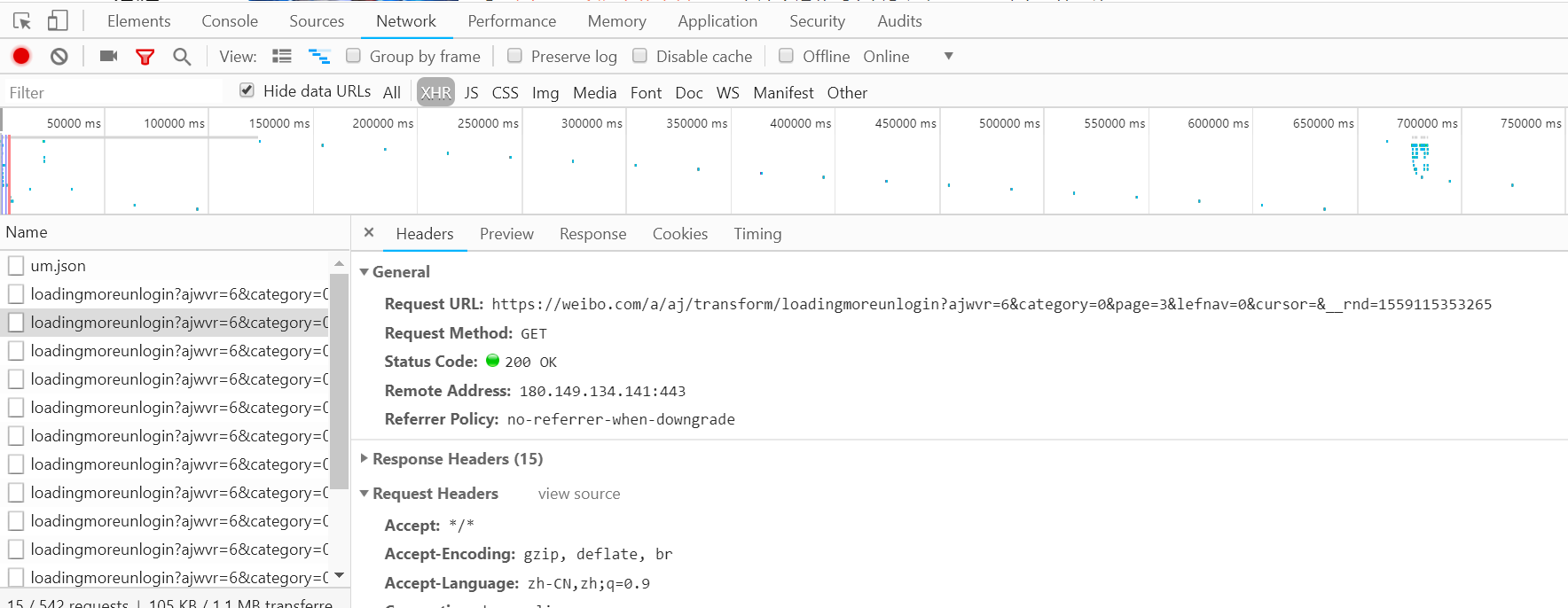
可以发现,这是一个GET请求,url为https://weibo.com/a/aj/transform/loadingmoreunlogin? ajwvr=6&category=0&page=3&lefnav=0&cursor=&__rnd=1559115353265。请求的参数有六个:ajwvr,category,page,lefnav,cursor,__rnd。
再看看其他请求,发现只有page,__rnd这两个参数在改变。很明显page是用来控制分页的,细心观察__rnd的值为对应的时间戳。
2.分析响应
观察这个请求的响应内容:
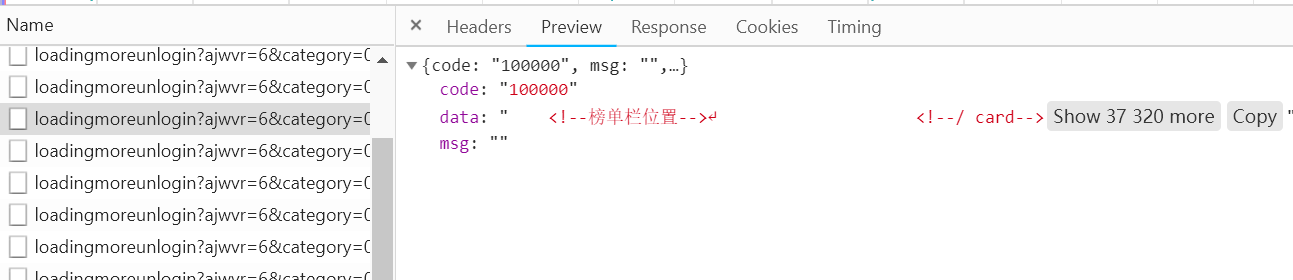
这个内容的格式为JSON,其中主要的内容在data对应的值里面。这样我们请求一个接口,改变page参数就可以获得对应数据。
3.爬取数据
这里我们来模拟这戏Ajax请求,将前10页的数据爬取下来。
# _*_ coding=utf-8 _*_ import requests, time
from urllib.parse import urlencode base_url = 'https://weibo.com/a/aj/transform/loadingmoreunlogin?'
headers = {
'Host': 'weibo.com',
'Referer': 'https://weibo.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
} def get_page(page):
"""
:param page:
:return:
"""
# 构造__rnd参数
rnd = int(time.time())
# 构造参数字典
params = {
'ajwvr': '',
'category': '',
'page': page,
'lefnav': '',
'cursor': '',
'__rnd': rnd }
# 拼接参数与url
url = base_url + urlencode(params) try:
res = requests.get(url, headers=headers)
if res.status_code == 200:
return res.json()
except Exception as e:
print('Error:', e.args) def parse(res):
weibo = {}
if res:
weibo['data'] = res.get('data')
yield weibo if __name__ == "__main__":
for page in range(1, 11):
result = get_page(page)
weibo_data = parse(result)
for data in weibo_data:
print(data)
运行结果:
{'data': ' <!--榜单栏位置-->\n <!--/ card-->\r\n<div class="UG_slider" >\r\n <ul action-type="header_slider" node-type="header_slider">\r\n <li>\r\n <a href="/a/hot/7562265474177025_1.html?type=new" target="_blank" suda-uatrack="key=www_unlogin_home&value=focus01">\r\n <img src="https://wx2.sinaimg.cn/crop.0.61.600.337/60718250ly1g3hxko6uxbj20go0b30t9.jpg" class="pic"><div class="pic_intro">头条新闻今日快讯 | 华为在美提起诉讼.....}
这样我们就通过分析Ajax请求并编写爬虫获取到微博数据,当然代码还可更优化,还可以解析具体的标题、内容,这里只是演示Ajax请求的模拟过程,爬取结果并不是重点。
爬虫—Ajax数据爬取的更多相关文章
- Ajax数据爬取
Ajax的基本原理 以菜鸟教程的代码为例: XMLHTTPRequest对象是JS对Ajax的底层实现: var xmlhttp; if (window.XMLHttpRequest) { // IE ...
- python3编写网络爬虫13-Ajax数据爬取
一.Ajax数据爬取 1. 简介:Ajax 全称Asynchronous JavaScript and XML 异步的Javascript和XML. 它不是一门编程语言,而是利用JavaScript在 ...
- 第十四节:Web爬虫之Ajax数据爬取
有时候在爬取数据的时候我们需要手动向上滑一下,网页才加载一定量的数据,但是网页的url并没有发生变化,这时我们就要考虑使用ajax进行数据爬取了...
- Python爬虫 股票数据爬取
前一篇提到了与股票数据相关的可能几种数据情况,本篇接着上篇,介绍一下多个网页的数据爬取.目标抓取平安银行(000001)从1989年~2017年的全部财务数据. 数据源分析 地址分析 http://m ...
- Ajax数据爬取--爬取微博
Ajax Ajax,即异步的JaveScript和XML.它不是一门编程语言,而是利用JaveScript在保证页面不被刷新,页面链接不改变的情况下与服务器交换数据并更新部分网页的技术. 对于传统的网 ...
- python-day7爬虫基础之Ajax数据爬取
前几天一直在忙老师的项目,就没有继续学python,也没有写什么收获,今天晚上有空看看书,边看边理解着写吧: 首先说一下,我对Ajax的理解,就是有时候我们在浏览某个网页的时候,只要我们鼠标一直往下滑 ...
- 第7章 Ajax数据爬取
Ajax 简介 Ajax 分析方法 Ajax 结果提取
- 爬虫1.5-ajax数据爬取
目录 爬虫-ajax数据爬取 1. ajax数据 2. selenium+chromedriver知识准备 3. selenium+chromedriver实战拉勾网爬虫代码 爬虫-ajax数据爬取 ...
- 爬虫(十):AJAX、爬取AJAX数据
1. AJAX 1.1 什么是AJAX AJAX即“Asynchronous JavaScript And XML”(异步JavaScript和XML)可以使网页实现异步更新,就是不重新加载整个网页的 ...
随机推荐
- CentOS7.x的DNS服务的基础配置
一.bind服务器安装 bind:开源.稳定.应用广泛的DNS服务.bind的软件包名bind,服务名称named. 查看是否安装bind, 安装bind包: rpm -qa bind yum -y ...
- Linux之iptables(五、firewall命令及配置)
firewalld服务 firewalld是CentOS 7.0新推出的管理netfilter的工具 firewalld是配置和监控防火墙规则的系统守护进程.可以实现iptables,ip6table ...
- python3.x Day1 菜单程序练习
三级菜单: 1. 运行程序输出第一级菜单 2. 选择一级菜单某项,输出二级菜单,同理输出三级菜单 3. 菜单数据保存在文件中 4. 让用户选择是否要退出 5. 有返回上一级菜单的功能 类定义:menu ...
- LVS集群的三种工作模式
LVS的三种工作模式: 1)VS/NAT模式(Network address translation) 2)VS/TUN模式(tunneling) 3)DR模式(Direct routing) 1.N ...
- 【Codeforces 300C】Beautiful Numbers
[链接] 我是链接,点我呀:) [题意] 让你找到长度为n的数字 这个数字只由a或者b组成 且这n个数码的和也是由a或者b组成的 求出满足这样要求的数字的个数 [题解] 枚举答案数字中b的个数为y,那 ...
- Python学习笔记 (2.1)标准数据类型之Number(数字)
Python3中,数字分为四种——int,float,bool,complex int(整型) 和数学上的整数表示没啥区别,没有大小限制(多棒啊,不用写整数高精了),可正可负.还可表示16进制,以 0 ...
- cogs——1578. 次小生成树初级练习题
1578. 次小生成树初级练习题 ☆ 输入文件:mst2.in 输出文件:mst2.out 简单对比时间限制:1 s 内存限制:256 MB [题目描述] 求严格次小生成树 [输入格式 ...
- Mabatis错误--Parameter index out of range
昨天遇到一个错误,之前也遇到过,但是之前遇到很快就解决了,昨天遇到这个错误当时看了大概10来分钟,还是没搞好,今天才来搞好了. 错误信息如下 08:34:43,302 DEBUG getTeacher ...
- 友盟 个推 微信sdk spring boot
友盟 个推 微信sdk spring boot ngix mongodb memory cache
- Neutron中的网络I/O虚拟化
为了提升网络I/O性能.虚拟化的网络I/O模型也在不断的演化: 1,全虚拟化网卡(emulation).如VMware中的E1000用来仿真intel 82545千兆网卡,它的功能更完备,如相比一些半 ...