selenium对51job进行职位爬虫
selenium 爬虫流程如下:
1、对某职位进行爬虫 ---如:自动化测试
2、用到IDE为 pycharm
3、爬虫职位导入到MongoDB数据库中
4、在线安装 pip install pymongo
5、本次使用到脚本化无头浏览器 --- PhantomJS MongoDB安装说明连接:https://www.twblogs.net/a/5c27009bbd9eee16b3dba7bc/zh-cn
PhantomJS 下载地址和API连接:http://phantomjs.org/download.html , http://phantomjs.org/api/下载后添加path中 --- CMD窗口输入 PhantomJS 按回车 --- 出现 phantomjs> 说明配置成功 如下为 51job.py 截图:

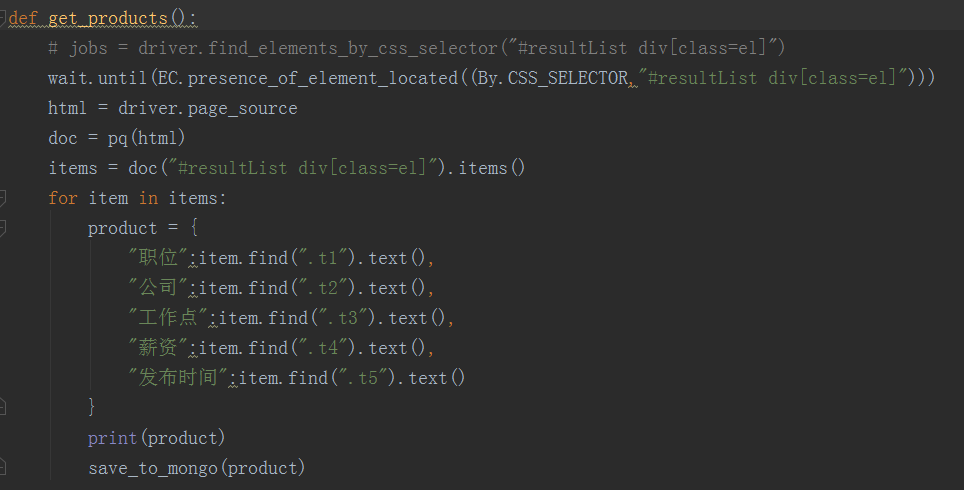
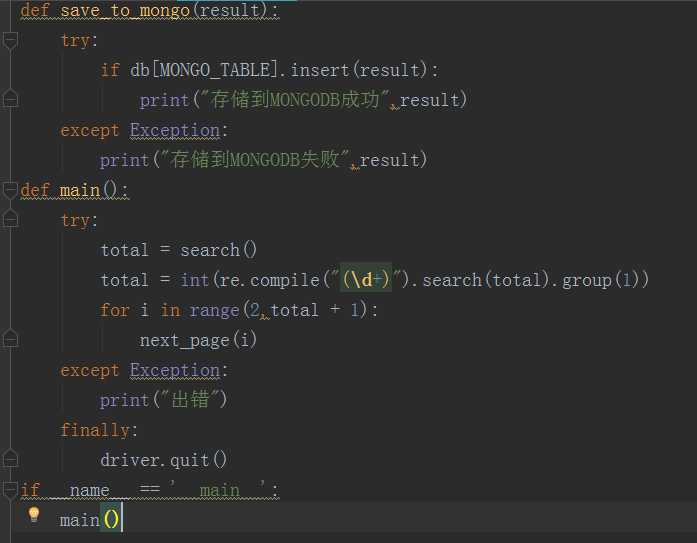
config配置文件如下:

pycharm 运行结果:

MongoDB 数据库截图:
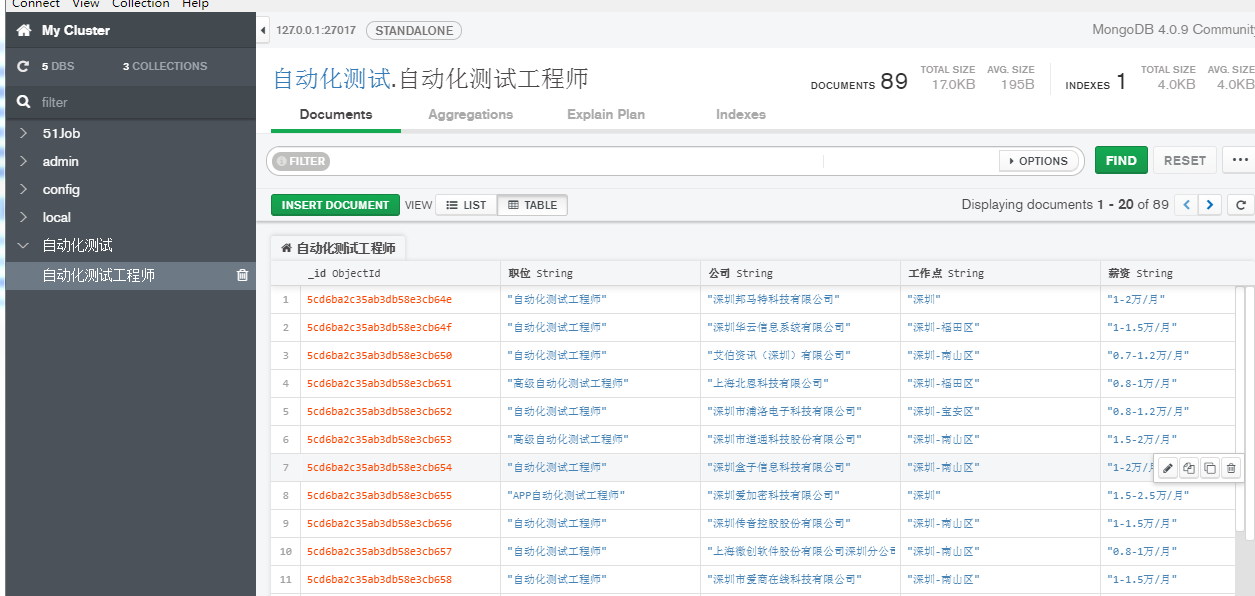
如下为config 配置文件:
MONGO_URL = "mongodb://127.0.0.1:27017/" MONGO_DB = "自动化测试"
MONGO_TABLE = "自动化测试工程师" KEYWORD = "自动化测试工程师" SERVICE_ARGS = ["--load-images=false","--disk-cache=true"] #忽略缓存和图片加载
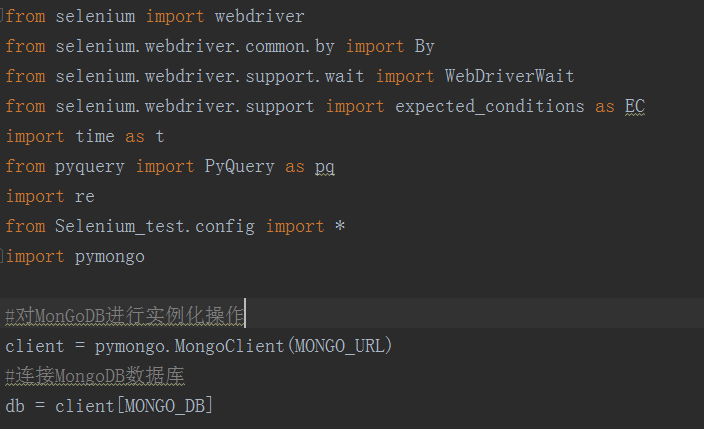
爬虫源码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time as t
from pyquery import PyQuery as pq
import re
#config -- 上面已展示
from Selenium_test.config import *
import pymongo #对MonGoDB进行实例化操作
client = pymongo.MongoClient(MONGO_URL)
#连接MongoDB数据库
db = client[MONGO_DB] #浏览器实例化
driver = webdriver.PhantomJS(service_args=SERVICE_ARGS)
# driver = webdriver.Chrome()
driver.set_window_size(1400,900)
driver.maximize_window()
driver.implicitly_wait(10)
#显示等待
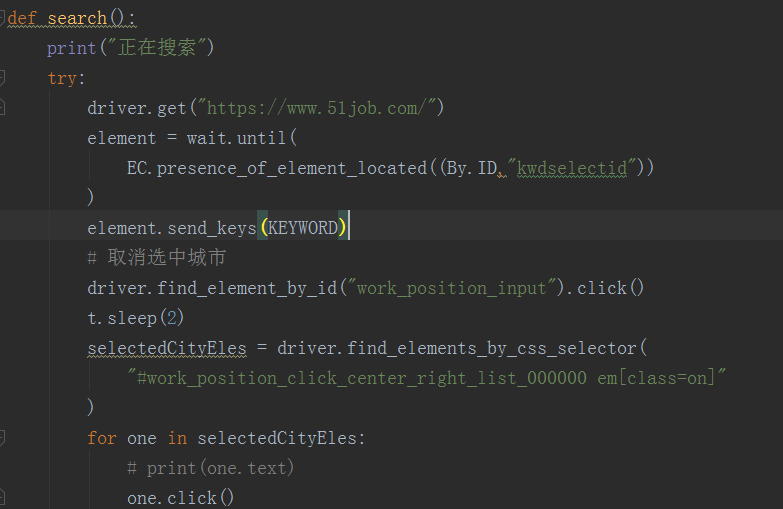
wait = WebDriverWait(driver,10) def search():
print("正在搜索")
try:
driver.get("https://www.51job.com/")
element = wait.until(
EC.presence_of_element_located((By.ID,"kwdselectid"))
)
element.send_keys(KEYWORD)
# 取消选中城市
driver.find_element_by_id("work_position_input").click()
t.sleep(2)
selectedCityEles = driver.find_elements_by_css_selector(
"#work_position_click_center_right_list_000000 em[class=on]"
)
for one in selectedCityEles:
# print(one.text)
one.click()
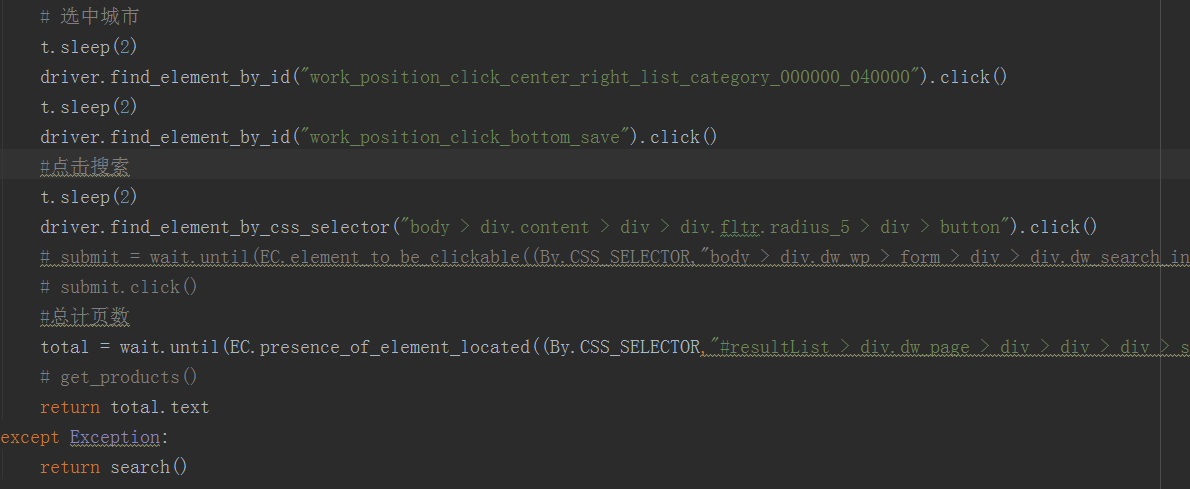
# 选中城市
t.sleep(2)
driver.find_element_by_id("work_position_click_center_right_list_category_000000_040000").click()
t.sleep(2)
driver.find_element_by_id("work_position_click_bottom_save").click()
#点击搜索
t.sleep(2)
driver.find_element_by_css_selector("body > div.content > div > div.fltr.radius_5 > div > button").click()
# submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,"body > div.dw_wp > form > div > div.dw_search_in > button")))
# submit.click()
#总计页数
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,"#resultList > div.dw_page > div > div > div > span:nth-child(2)")))
# get_products()
return total.text
except Exception:
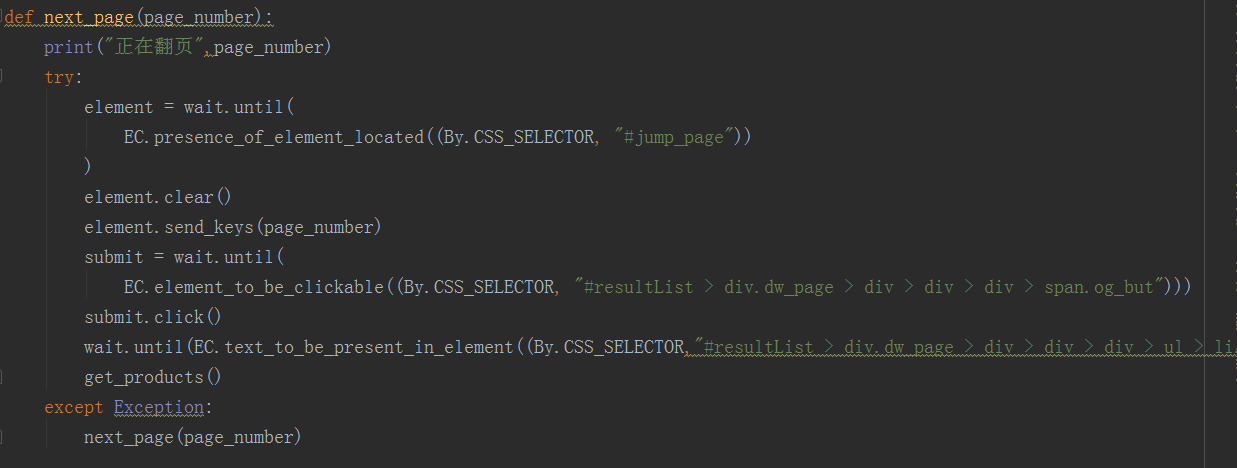
return search() def next_page(page_number):
print("正在翻页",page_number)
try:
element = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#jump_page"))
)
element.clear()
element.send_keys(page_number)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#resultList > div.dw_page > div > div > div > span.og_but")))
submit.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,"#resultList > div.dw_page > div > div > div > ul > li.on"),str(page_number)))
get_products()
except Exception:
next_page(page_number) def get_products():
# jobs = driver.find_elements_by_css_selector("#resultList div[class=el]")
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,"#resultList div[class=el]")))
html = driver.page_source
doc = pq(html)
items = doc("#resultList div[class=el]").items()
for item in items:
product = {
"职位":item.find(".t1").text(),
"公司":item.find(".t2").text(),
"工作点":item.find(".t3").text(),
"薪资":item.find(".t4").text(),
"发布时间":item.find(".t5").text()
}
print(product)
save_to_mongo(product) def save_to_mongo(result):
try:
if db[MONGO_TABLE].insert(result):
print("存储到MONGODB成功",result)
except Exception:
print("存储到MONGODB失败",result) def main():
try:
total = search()
total = int(re.compile("(\d+)").search(total).group(1))
for i in range(2,total + 1):
next_page(i)
except Exception:
print("出错")
finally:
driver.quit() if __name__ == '__main__':
main()
selenium对51job进行职位爬虫的更多相关文章
- Selenium + PhantomJS + python 简单实现爬虫的功能
Selenium 一.简介 selenium是一个用于Web应用自动化程序测试的工具,测试直接运行在浏览器中,就像真正的用户在操作一样 selenium2支持通过驱动真实浏览器(FirfoxDrive ...
- 基于selenium爬取拉勾网职位信息
1.selenium Selenium 本是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.而这一特性为爬虫开发提供了一个选择及方向,由于其本身依赖 ...
- Selenium结合BeautifulSoup4编写简单爬虫
在学会了抓包,接口请求(如requests库)和Selenium的一些操作方法后,基本上就可以编写爬虫,爬取绝大多数网站的内容. 在爬虫领域,Selenium永远是最后一道防线.从本质上来说,访问网页 ...
- selenium+chromdriver 动态网页的爬虫
# 获取加载更多的数据有 2 种方法# 第一种就是直接找数据接口, 点击'加载更多' 在Network看下, 直接找到数据接口 # 第二种方法就是使用selenium+chromdriver # se ...
- python+selenium实现网页自动化与爬虫技术
举例某购物网站,通过selenium与python,实现主页上商品的搜索,并将信息爬虫保存至本地excel表内. 一.python环境与selenium环境安装 python在官网下载并安装并且设置环 ...
- selenium+BeautifulSoup实现强大的爬虫功能
sublime下运行 1 下载并安装必要的插件 BeautifulSoup selenium phantomjs 采用方式可以下载后安装,本文采用pip pip install BeautifulSo ...
- [python爬虫] Selenium常见元素定位方法和操作的学习介绍
这篇文章主要Selenium+Python自动测试或爬虫中的常见定位方法.鼠标操作.键盘操作介绍,希望该篇基础性文章对你有所帮助,如果有错误或不足之处,请海涵~同时CSDN总是屏蔽这篇文章,再加上最近 ...
- python爬虫积累(一)--------selenium+python+PhantomJS的使用
最近按公司要求,爬取相关网站时,发现没有找到js包的地址,我就采用selenium来爬取信息,相关实战链接:python爬虫实战(一)--------中国作物种质信息网 一.Selenium介绍 Se ...
- 使用Python + Selenium打造浏览器爬虫
Selenium 是一款强大的基于浏览器的开源自动化测试工具,最初由 Jason Huggins 于 2004 年在 ThoughtWorks 发起,它提供了一套简单易用的 API,模拟浏览器的各种操 ...
随机推荐
- java读utf8 的txt文件,第一个字符为空或问号问题
参考:https://blog.csdn.net/yangzhichao888/article/details/79529756 https://blog.csdn.net/wangzhi291/ar ...
- JDK的安装和环境变量配置
1.安装JDK开发环境 下载网站: http://www.oracle.com/technetwork/java/javase/downloads/index.html 进入后选择Accept Lic ...
- Linux操作系统下IPTables配置
filter表的防火墙 1.查看本机关于IPTABLES的设置情况 [root@tp ~]# iptables -L -n Chain INPUT (policy ACCEPT) target pro ...
- linux shell 获得当前程序的路径
filepath=$(cd "$(dirname "$0")"; pwd) 脚本文件的绝对路径存在了环境变量filepath中,可以用 echo $filepa ...
- 安装adt-bundle-windows-x86-20130917时遇到的问题及解决方法
最近在上安卓课,老师让我们下载此软件(adt-bundle-windows-x86-20130917.下载压缩后,打开eclipse的时候,会出现以下情况: 这时说明你的jdk还没下载或者下载错位置了 ...
- spring boot项目自定义数据源,mybatisplus分页、逻辑删除无效解决方法
Spring Boot项目中数据源的配置可以通过两种方式实现: 1.application.yml或者application.properties配置 2.注入DataSource及SqlSessio ...
- laravel有用的方法
1.tinker 造假数据 factory('App\User',3)->create(); DB::table 返回collection,可以用collection中的很多方法 比如-> ...
- SDUT--找朋友(BFS&&DFS)
找朋友 Time Limit: 1000ms Memory limit: 65536K 有疑问?点这里^_^ 题目描写叙述 X,作为户外运动的忠实爱好者,总是不想呆在家里.如今,他想把死宅Y从家 ...
- psping
psping工具功能主要包括:ICMP Ping.TCP Ping.延迟测试.带宽测试,是微软出品. 下载地址:https://download.sysinternals.com/files/PSTo ...
- 工作总结 string数组 排序 string数组 比较
用到 工具类 Array 创建.处理.搜索数组并对数组进行排序 Enumerable 提供一组用于查询实现 System.Collections.Generic.IEnumerable<T ...