noip2018——题解&总结
近期正在疯狂复习某些东西,这篇博客尽量年底更完……(Day2T2除外)
好了,所有的希望都破灭了,原来这就是出题人的素质。——一个被欺骗的可怜 $OIer$
人生中倒数第三次 $noip$ (Maybe it is),好好珍惜这快乐的一段人生吧……
$OYYP$ 和 $WXJ$ 神仙都考得很好,然后快乐地回广州二中继续修仙了……其他大佬们也都稳稳地游冬令营了吧……我可能是要单独留守北京的最菜选手了……
想看 $Day1$ 各种段子的可以空降。
游记
Day 0
啥都没复习,慌得一批。
打了个自闭模拟赛,第一题输入写错了,第二题推不出来,准备退役,yeah。
下午跟大佬们去听听 CXM 的考前叮嘱,又给我们讲了一遍 $NOILinux$ 的相关操作,尤其是终端编译(我考试用了吗?……)我顺便记了一波。
然后去借(抢)$LHC$ 的电脑,用他装的虚拟机练了一波终端。
虚拟机真卡,喷。
用了两遍命令行发现没啥问题,就放心了。
晚上早早回到家,瞎**复习了一波简单题,又看了看数据结构模板。诶,越看越虚,我要是连相对简单的 $Day1$ 都不会做我我就有望退役了。
吃完饭先装 $NOILinux$。
装了好长时间(二十分钟?),发现虚拟机进不去导入的 $ubuntu$。
上网查错误信息无果。
我换家里的台式电脑,又装了半天,发现还是进不去?
为啥啊?……
我上 $NOI$ 官网下载 $iso$ 试试。
结果官网下载特别慢,显示要用 $40$ 多分钟。
不对啊,我之前从邮箱传回来的 $iso$ 文件只要 $10$ 多分钟啊?
我就大胆猜想是邮箱传坏了。
于是等官网的 $iso$ 下完了,我再导入虚拟机,诶,能用。
然后我就用低端的虚拟机写了道联合权值,练了下对拍等操作,就睡觉去了。
Day 1
早早地起来去北师大附,路上还挺虚的,用手机复习了一遍逛公园那道题用拓扑排序方法怎么做来着。
到了考场大门,发现我的几个同学也都刚好到。然后我就 $\%\%\%$ 他们咯。
俗话说“膜高一尺,分高一丈”嘛!向大佬膜拜,分能越膜越高。
进了考场,找到我的位置就坐下啦。
噗……这显示屏的屏幕分辨率不对啊……显示的东西都是扁扁的,配置真垃圾。
公布了电脑密码之后我就找设置,想改屏幕分辨率,然后发现这是最高的了,而且只能调三种分辨率……另外两种更可怕……
电脑配置差真的很无语。
$SYF$ 大佬坐在靠窗户的位置,我望了一下她,继续 $\%$ 了起来。
考前几分钟公布了试题密码,只让看题,不让写。
打开压缩文件,我把东西全拖出到主文件夹。
先看了下规则文档,今年开始改规则了,每道题的程序要放在不同的文件夹下,以前就给个考号文件夹,三道题的程序啥的一起放进去就可以了。
然后去看题。三道 $1s/512MB$ 的题,突然感觉很虚。
先看 $T1$,好像不太难,扫了一分钟就看 $T2$ 了。
看完 $T2$ 又虚了,好像没什么思路,跟去年的 $D1T1$ 小凯的疑惑 差不多的感觉……
三分钟之后去看 $T3$,来回看样例和数据,只能上来就想到二分答案,然后还不会判断。
凉,看完今天三道题感觉好虚啊,我怎么什么都不会。
到点可以写代码了,我先敲了缺省源,存到每道题的目录下。
然后做 $T1$。
然后我发现 $T1$ 暴力好像是 $O(n^2)$ 级别的??
也就是说我连 $T1$ 都不会做了?
凉,当时想退役了。
周围已经响起啪啪的键盘声了,然后我就慌了,赶紧拿笔推样例。
然后就猜想,是不是可以做个倍增,快速求区间最小值,然后在分治的时候把区间所有数都减掉它。再以这个被减成 $0$ 的最小值为分界,继续分治,减两边的区间?
但是怎么找到最小值的位置?要以那个位置为切割点,分治递归两边呀!
我当时想着 $ST$ 表好像只能求最小值,求不了位置……然后以为不可做……(后文的题解证实最小值的位置连个 $sb$ 都会找)
然后发现可以反过来做:把相邻且相同的数的区间记为同一个区间,然后每次找数最大的区间,把它减成与它相邻的区间中,数最大的那个。
这样倒是可以,把分治转成合并,就不用考虑那些 zz 问题了。
然后码了一波,发现自己写区间合并的代码能力真差……
合并的时候,只要改被减区间的两端点的归属就可以了。
无脑码了挺久,大概写到 $9:20$ 吧。小样例很快测过了。
再次看到 $T3$,回想了一下老师讲过的那些 树上 $dp$ 的特征,然后注意到这题跟 树上 $dp$ 的性质很像,对于一个点,赛道要么经过这个点和它的两条儿子链,要么经过这个点、它的一条儿子链和它的祖先链(并且只能向祖先传一条儿子链)。
那就是贪心了吧?把一个点的所有儿子传来的链长排序,对于每一条儿子链,把它删掉(防止另一条链取到它自己),贪心取另一条 与它相接的长度大于等于 二分的答案$mid$ 的一条儿子链,再把那条链删掉,记赛道数 $+1$;如果没有能与它连成合法赛道的另一条儿子链,就把它传给祖先链。祖先链只能选一条最长的儿子链传上去。
当然特判一下所有长度 $\ge mid$ 的儿子链,把它们自组成赛道就行了。
这不是 $dp$ 啊?贪心??
但是又推了一下,好像这么做就可以了,确实不用 $dp$。
于是我就尝试了一波,$10$ 几分钟后写完了。当然我比较懒,直接用了一种支持加数、二分查找(lower_bound)和删数的 $STL$:$set$(其实不是这个,后面会提到)。
试了一下前两个小样例,都过了。此时 $10:10$ 左右,转战 $T2$。
一看到 $T2$ 又懵了一下,发现还是不会做。好像很结论啊
于是我手写了一组小数据($2\space 5\space 7$),发现可以不要 $7$,因为它能被 $2,5$ 表示出来。
这样答案 $m$ 就是 $2$ 了。答案肯定不会是 $1$,因为这个集合能表示的数的集合是 $2,4,5,6,7,8,9,……$。
那还有 $m=2$ 的方案吗?经过尝试发现没有。
好像不能用 不在原集合的数 表示出等价的货币系统啊?
感觉这个结论很显然,简单想想大概是因为一个数能表示的集合只与自己等价,再深入证明我当时也不清楚了。
进一步推,也就是说只需要看一下原集合中一个数是否能被原集合中其它一些数表示出来
然后看了一下数据范围,$T\times n\times a_i=5000w$,且 $a_i$ 是正整数。那就 排序+背包转移?
**,感觉 $T2$ 比 $T1$ 还简单了。
**,感觉刚开考时自己就是个傻逼。
$5$ 分钟抓紧码完代码。
$10:30$ 的时候三道题就都写完了。
然而三道题都还没测大样例,我就着手先测 $T2$ 大样例了。
一测,没过!什么情况啊?
很快发现背包转移写错了,能把转移的 $true$ 重新刷成 $false$。
迅速改了一下就对了。
然后去测 $T1$。
一测就死循环了,我瞬间懵了。
看了下优先队列的判退出是怎么写的。
然后发现我又 sb 了:$if(l[u]==1\space \&\&\space r[u]==6)\space break;$
$r[u]$ 应该判等于 $n$,我测第一组样例的时候直接把样例的 $n=6$ 写上去了。
然而改完了还是死循环。
为什么??合并区间有问题吗?按理说合并区间最多只要 $n-1$ 次啊,最后就只剩下一个区间 $[1,n]$,然后退出去。
我加了个调试特判,让优先队列跑 $10w$ 次就中途退出输出累积得答案。
然后惊奇的发现答案对了?!
那为什么会死循环?
这个问题坑了我好久。调了无数遍,才发现原来我没判区间位于左右边界的情况,导致区间向下标为 $0$ 的位置(左边界之外)合并,最终合并出的区间的左端点就小于 $1$,就出不去了。
其实好像预处理也写的不太对,但这里不好描述是怎么改的。
大概 $11:15$ 的时候终于过了 $T1$ 的大样例。由于代码的调试输出太多,弄得伤痕累累,我特意重新码了一下格式。
最后测 $T3$ 的大样例。
不出所料,又没过。
但是我盯了半天代码没看出哪里有问题,好像写的都没错啊?
于是我赶紧yy起了 $hack$ 数据。
然后第二组数据就 $hack$ 掉了:
4 1
1 2 1
2 3 2
2 4 2
答案明显是 $4$,然后我的程序输出 $3$。
我就疑惑了,下面两条边怎么没有合并?
我输出了一下在 $2$ 号点合并儿子链时,记录链长的 $set$ 存了多少个数。
然后发现只有 $1$ 个数。
不是插入了两个 $2$ 吗?
想了半天,我突然意识到了:$set$ 是不可重集,相同的数只存一个。(这就是之前为什么说其实不是 $set$)
我赶紧改成 $multiset$,再测大样例,还行,跟自己想的一样过了。
再过几分钟就 $11:30$ 了吧。
也就是说我可以装作今天 $AK$ 了?
不过我没有立刻放松,反复地查文件名、输入输出、编译是否还能过等各种细节,防止又翻车了。(我去年 $D1T2$ 打错大小写然后爆零了)
多亏最后 $10$ 分钟发现并删除了 $T3$ 一堆调试用的 $getchar$, 不然我直接交上去就可能 $T$ 了。(不知道为什么本机测就没事)
呼,累+虚+紧张。等着收卷吧。
出了考场之后意识到一个问题:$T3$ 用 $STL$ 貌似会被卡常。我考试的时候没用终端,也没注意跑的速度。
众所周知,在不开 $O2$ 的 $noip$ 老爷机上跑 $STL$ 有多慢。
算算时间,$5\times 10^4\times log(5*10^8)\times log(?) = 150w\times 玄学$??
树上的总复杂度姑且认为是 $O(n\times 玄学)$ 级别的?
均摊复杂度是 $O(玄学)$ 级别的?
诶,心态崩了。测评的时候 极限数据要是真被卡常 我就虚上天了。
考后发现 $D1T1$ 居然是 $noip2013\space D2T1$ 原题??人名都不改??
而且我还没复习那道题??
$noip$ 出原题真的没事吗,不违反规定吗,
等等……中国信竞规定都是他们出的,他们就算真做的有出入,谁敢管啊
总之 $I'm\space so\space moved$。
回到家之后我就惊奇地发现:只是这样吗?
Day1三道原题(或近似)
$Day1$ 就出成这样?几乎是三道原题,sdyg去吧。
三年OI一场空,三道原题见祖宗。NOIP=POI*N。
更可笑的是,有人在考前几天发现某些网站上(如bzoj)的原题被关闭了,然后就猜出了是NOIP原题。
行了,准备禁他们的赛。
出题组疑似在 $2013$ 年泄露 $noip2018$ 的试题,严重违反公平竞赛原则,也禁赛三年。
对了,验题组也禁赛三年。
一觉睡到晚上。诶,起来接着复习。
……看点啥?
再考原题怎么办,所以先看看 $noip2012$ 的同余方程。
剩下的可能就是复习板子题了?
看了看去年的状压、$splay$、替罪羊树等知识点,然后……了一些事情,就接着睡了。
Day 2
今天到了考点依然先恶膜大佬们。不过今天是不是反向膜拜了,感觉 $rp$ 都膜没了。
诶,好虚啊。
公布题目密码后就按顺序看题。
$T1$ 题目我一上来就看错了,以为题目的意思是边可以任意重复走。
$T2$……什么东西……为什么 $n,m$ 差这么多……
$T3$……更没想法了,似乎不是数据结构题。
我突然意识到前一天晚上的复习可能没用了。
这就是考前复习的内容必不考的定理?
很快就到点开考了。我画了画图,题目给的两组样例都对了,于是我按照我看错的题意码了 优先队列 $bfs$。
一测,前两组样例没啥问题。
我想,$T1$ 应该不用太花心思调了吧?
然后大样例直接 $WA$ 上天了。
我想:不可能啊,这做法都有问题吗?
我查了一下我怎么跑错的大样例,一段时间后发现自己读错题了:每条边经过一次后,就不能再以第一次的方向走这条边了。
这导致我很慌 OwO
我又手算了一波,发现如果是树的话依然很好做,只要优先跑编号小的儿子,然后把以这个儿子为根的子树跑完再出来就可以了。
那为什么会有 $n=m$ 的数据?
也就是说要删一条边?
当时我并没有想到可以枚举删哪条边,因为我没想到可以预处理把每个点的所有儿子排序,以为枚举套树上排序是 $O(n^2\times log(n))$ 的,实际上分开做就是 $O(n^2)$ 的了……(这个故事证明了我在暴力方面思想僵化)
就因为这一点我苦算了好久 $T1$……心态爆炸
最后我yy出了一个预处理删掉哪条边的方法,具体就是找到那个唯一的环,然后模拟跑一遍环,看准备沿环边走到哪个儿子点时,退回去走环的另一侧 比 继续走下去 更优即可。把这条边删掉就行了(别忘了是无向图,要删两条单向边)。(考后发现这个做法有问题,具体见题解部分)
最后调过了各种奇怪的问题,终于过大样例了。
此时已经 $9:50$ 了吧……好气啊……
看了下 $T2$,按理说这个位置该放状压 $dp$ 了。
好像 $n=8$ 很可以入手的样子。
但我算了一波就发现根本就没法入手……
然后我可能见了鬼了,无脑推了一波式子,猜想答案跟 $2^n$ 的很多倍有关……
但很快我意识到上面的数要比下面的对应位置的数小,所以我改了推法。
推了一小时,我成功推翻了我yy的式子。原因是如果 上面的路径在前面某一位的数 比 下面的路径在对应位的数 小,那上面的路径的后面所有数貌似是可以随便填的。
浪费时间的我最终自闭了。
我闷声码了 $20$ 分暴力,看 $T3$ 去了。
此时已经过 $11:00$ 了。
$T3$ 还想正解吗?不存在的。
想了想感觉不可做,于是就写了写 $2000$ 规模的暴力树上 $dp$ ,复杂度 $O(nm)$ 吧。
至于 $-1$ 的情况,只要判断 国王是否要求一条边连接的两个点都不驻扎军队 就可以了,只有这种情况输出 $-1$。
都码完了,再检查一下文件名什么的,作为暴力选手的我就遗憾滚粗了。
$Day2$ 的期望得分…… $100+20+44=164$ ?
我好菜啊,$T2$ 没有强行打表,$T3$ 也没杠什么特殊情况。
其他选手至少都有思路吧,至少也是写挂了,总比我这个一点没写的蒟蒻强。
唉,果然还是我太菜。$noip2018$ 就这么遗憾地考完了。
回去看钟子谦发知乎消息说 $T2$ 是找规律?前 $65$ 分找规律可白送?不是状压 $dp$?
我**,我 $T2$ 好像 $20$ 分滚粗了……
$T3$ 是动态 $dp$?每个点维护一个转移矩阵?
11.19 update:
$D2T2$ 我打错了暴力??我把判边界的 $m$ 打成了 $n$?而且数据太水导致现场没发现?我去年的 $D2T3$ 发生过类似的暴力打挂事件??完了 $2\space 3$ 这组数据就把我卡了,看来我要因暴力退役了。
$D2T3$ 树高 $\le 100$ 的 $8$ 分额外数据是白送的?……暴力修改两点简单路径上的 $dp$ 值就可以了??行吧***(自动和谐)这特殊点我在考场上直接没看见。其实即使看到了也不一定有时间调出来了吧……
完了完了……我还是这么不会打 $OI$……看来我只能拿够大众分退役辣。
看他们都聊得好开心(充满了 $AK$ 的气氛)
(我太菜了,所以这里没有我的发言)
晕,这是可做的找规律题吗……动态 $dp$ 什么时候成 $noip$ 考点了……
我不会写啊……瑟瑟发抖……
看来今年又是一次教训了,等出了成绩之后我发一下吧(爆零预定)。
11.20 update:
$luogu$ 民间数据:$100+100+95+84+15+44=438$
$CCF$ 官方数据:$100+100+100+92+15+44=451$
我太菜了……大佬保佑我卡上 $PKUWC$ 的线吧……(12.?? update:我卡个毛,今年北大和清华的分数线居然一样,都是 $480$)
11.28 update:
前几天终于知道为什么这次的 $Day2T2$ 是这么一道垃圾题了……
原 $T2$ 出题人被张哥哥骗到一个小地方去讲课了(他以为是 $ccf$ 办的课),但根据 $ccf$ 规定,$NOI$ 系列比赛的出题人在期间是不能出去代课的,结果官方因为怕泄题,把原 $Day2T2$ 给删了,然后草草地翻书翻了这么一道垃圾数学题,就赶紧补上去了。
$ccf$ 达成新成就——$2018$ 全年比赛全部出锅($CTSC$ 收程序时关机导致丢了 $85$ 个人的程序 及 $Day2T2$ 正解被 $hack$,$NOI$ $Day1T2$ 卡特兰数数据出错,等等)。
题解
1.积木大赛
题目描述
春春是一名道路工程师,负责铺设一条长度为 $n$ 的道路。
铺设道路的主要工作是填平下陷的地表。整段道路可以看作是 $n$ 块首尾相连的区域,一开始,第 $i$ 块区域下陷的深度为 $d_i$ 。 春春每天可以选择一段连续区间 $[L,R]$,填充这段区间中的每块区域,让其下陷深度减少 $1$。在选择区间时,需要保证,区间内的每块区域在填充前下陷深度均不为 $0$ 。春春希望你能帮他设计一种方案,可以在最短的时间内将整段道路的下陷深度都变为 $0$。
输入输出格式
输入格式
输入文件包含两行,第一行包含一个整数 $n$,表示道路的长度。第二行包含 $n$ 个整数,相邻两数间用一个空格隔开,第 $i$ 个整数为 $d_i$。
输出格式
输出文件仅包含一个整数,即最少需要多少天才能完成任务。
输入输出样例
输入样例#1
6
4 3 2 5 3 5
输出样例#1
9
说明
一种可行的最佳方案是,依次选择: [1,6]、[1,6]、[1,2]、[1,1、[4,6]、[4,4]、[4,4]、[6,6]、[6,6]。
对于 $30\%$的数据,$1≤n≤10$;
对于 $70\%$ 的数据,$1≤n≤1000$;
对于 $100\%$ 的数据,$1≤n≤100000,\space 0≤d_i≤10000$。
noip2013 积木大赛原题。
但是我在考场上并没看出来,于是yy了很愚蠢的算法(游记口胡过了)。
方法1(我的考场做法):
就是我们手玩这道题的话,如果是按照往下减的思路做的话,肯定会把最大的数先往下减,这样就能把更长的一段数减到一样小,使以后同时减的区间更大。
什么意思?就是这段数既然都一样了,它们就可以缩成一个数。因为它们以后一直都可以同时减,最终减到 $0$。
比如 $5\space 4\space 4\space 4\space 3$,先把最大的 $5$ 减到 $4$ 后,我们就可以把前 $4$ 个 $4$ 同时减到 $3$,再把 $5$ 个 $3$ 同时减到 $0$。容易发现任何一段连续且相同的数以后都可以同时减。
然后就想出比较贪心的做法了?
具体做法呢,为了方便调试(也就是正好合并 $n-1$ 次区间),我开始时直接建立 $n$ 个区间,第 $i$ 个区间的左右端点都设为 $i$(表示初始时每个区间各自只有 $1$ 个数),也就是可以不用在预处理时 把连续的几个相等的数合为一个区间。
然后用一个优先队列存储当前值最大的区间,每次把它减为 与它相邻的两个区间中值较大的那个区间的数,这样可以保证合并的有序性(从大到小)。在每个区间的左右端点上记录一下它们的属于哪个区间,这样要找一个区间的左右两个区间的话,直接取。别忘了特判左端点是 $1$ 和右端点是 $n$ 的情况(考场上的悲惨调试)。
最终判一下
时间复杂度:由于初始时最多有 $n$ 个区间,最终合并成一个 左端点为 $1$,右端点为 $n$,的区间,且每次合并两个区间必定使区间数 $-1$,所以最多合并 $n-1$ 次,套优先队列是 $n\times log(n)$。
方法2:
就是你只想用分治……这样重点就是找到区间内最小值的位置。
其实这完全可以做到啊 $QoQ$,至少线段树就可以了(这就是为什么我在之前的游记的这题部分说道 区间最小值的位置连个 $sb$ 都会求),大不了 $D1T1$ 写个线段树,虽然难度明显不对应,但线段树也挺好写的,人家也没规定你简单题就不能写数据结构了(像 $OYYP$ 神仙就这么做了)。
当然 $SYF$ 直接yy了 $ST$ 表做法,就是你的 $ST$ 表直接记录区间内最小值的位置,如果有多个最小值,记最左边那个。
倍增的时候直接取两边记录的位置的值,比较大小,然后把值小的位置 赋给倍增合并后的区间。
这样就可以分治了……也没绕什么弯,死磕一下也能磕出来。
方法3:
没错就是积木大赛那题的做法。他们说是差分?
其实不用说的那么高端吧,这种题就是个思维递推,因为后面的数无法影响 前面的数减到 $0$ 的次数。
所以我们只考虑 一个数与它之前所有的数 都减到 $0$ 所需的总次数。对于一个数,
如果它比前一个小,那它只需要一直跟前面相邻的数一起减,就能减到 $0$,所以不用加次数;
如果它比前一个大,那它需要比前面相邻的数多减 $d_i-d_{i-1}$ 次。
这是我的考场代码(方法1)
#include<cmath>
#include<cctype>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<iostream>
#include<algorithm>
#include<queue>
#define mp make_pair
using namespace std;
inline int read(){
int x=; bool f=; char c=getchar();
for(;!isdigit(c);c=getchar()) if(c=='-') f=;
for(; isdigit(c);c=getchar()) x=(x<<)+(x<<)+(c^'');
if(f) return x;
return -x;
}
int n,a[],cnt,part[],v[],l[],r[];
//int st[100010][20];
int gs[];
priority_queue<pair<int,int> >Q;
bool inq[];
//int hd=1,tl;
long long ans;
int main(){
//freopen("road.in","r",stdin);
//freopen("road.out","w",stdout);
n=read();
int i,j;
for(i=;i<=n;++i){
a[i]=read();
part[++cnt]=cnt, v[cnt]=a[i], l[cnt]=r[cnt]=i, Q.push(mp(a[i],cnt)), inq[cnt]=;
gs[i]=cnt;
/*
st[i][0]=a[i];
for(j=1;j<=Log[i];++j)
st[i][j]=min(st[i][j-1],st[i-(1<<(j-1))][j-1]);*/
}
int u;//,P=0; while(!Q.empty()){
u=Q.top().second,Q.pop();
inq[u]=; ans+=(long long)v[u];
if(l[u]== && r[u]==n) break;
if(l[u]!= && (r[u]==n || v[gs[l[u]-]]>v[gs[r[u]+]])){
r[gs[l[u]-]]=r[part[u]];
gs[r[u]]=part[l[u]-];
//if(part[l[u]-1]==0){printf("aki:%d->%d %d %d->%d\n",u,part[u],l[u],v[u],v[part[u]]); break;}
part[u]=gs[l[u]-];
ans-=(long long)v[part[u]];
//if(P%100==0) printf("%d\n",v[part[u]]);
//printf("merge:%d %d %d\n",part[u],l[part[u]],r[part[u]]);
if(!inq[part[u]]) Q.push(mp(v[part[u]],part[u]));
}
else{
l[gs[r[u]+]]=l[part[u]];
gs[l[u]]=part[r[u]+];
//printf("%d %d\n",r[u],gs[r[u]+1]);
//if(part[r[u]]==0){printf("%d->%d %d %d->%d\n",u,part[u],r[u],v[u],v[part[u]]); break;}
part[u]=gs[r[u]+];
ans-=(long long)v[part[u]];
//if(P%100==0) printf("%d\n",v[part[u]]);
//printf("merge:%d %d %d\n",part[u],l[part[u]],r[part[u]]);
if(!inq[part[u]]) Q.push(mp(v[part[u]],part[u]));
}
}
printf("%lld\n",ans);
return ;
}
2.货币系统
题目描述
在网友的国度中共有 $n$ 种不同面额的货币,第 $i$ 种货币的面额为 $a[i]$,你可以假设每一种货币都有无穷多张。为了方便,我们把货币种数为 $n$、面额数组为 $a[1..n]$ 的货币系统记作 $(n,a)$。
在一个完善的货币系统中,每一个非负整数的金额 $x$ 都应该可以被表示出,即对每一个非负整数 $x$,都存在 $n$ 个非负整数 $t[i]$ 满足 $a[i] \times t[i]$ 的和为 $x$。然而, 在网友的国度中,货币系统可能是不完善的,即可能存在金额 $x$ 不能被该货币系统表示出。例如在货币系统 $n=3$, a=[2,5,9]$ 中,金额 $1,3$ 就无法被表示出来。
两个货币系统 $(n,a)$ 和 $(m,b)$ 是等价的,当且仅当对于任意非负整数 $x$,它要么均可以被两个货币系统表出,要么不能被其中任何一个表出。
现在网友们打算简化一下货币系统。他们希望找到一个货币系统 $(m,b)$,满足 $(m,b)$ 与原来的货币系统 $(n,a)$ 等价,且 $m$ 尽可能的小。他们希望你来协助完成这个艰巨的任务:找到最小的 $m$。
输入输出格式
输入格式
输入文件的第一行包含一个整数 $T$,表示数据的组数。
接下来按照如下格式分别给出 $T$ 组数据。 每组数据的第一行包含一个正整数 $n$。接下来一行包含 $n$ 个由空格隔开的正整数 $a[i]$。
输出格式:
输出文件共有 $T$ 行,对于每组数据,输出一行一个正整数,表示所有与 $(n,a)$ 等价的货币系统 $(m,b)$ 中,最小的 $m$。
输入输出样例
输入样例#1
2
4
3 19 10 6
5
11 29 13 19 17
输出样例#1
2
5
说明
在第一组数据中,货币系统 $(2,[3,10])$ 和给出的货币系统 $(n,a)$ 等价,并可以验证不存在 $m<2$ 的等价的货币系统,因此答案为 $2$。 在第二组数据中,可以验证不存在 $m<n$ 的等价的货币系统,因此答案为 $5$。
数据范围与约定
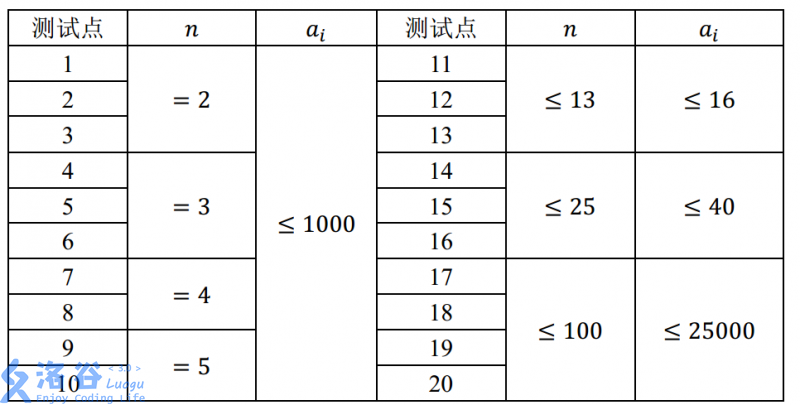
对于 $100\%$的数据,满足 $T≤20,n,a[i]≥1$。
首先可以把原集合的数从小到大排序,这样就能快速找到并删除 原集合中 能被集合中的一些数表示出来的数,它们一定是无用的。
那为什么这样做完后就得到了最终答案集合呢?
这里介绍一个容易理解的证明方法:
如果想找到一个更小的 $m$,那至少需要在集合中删掉 $k$ 个数($k\gt 1$),再加上最多 $k-1$ 个数,等价代替删掉的那些数的表示情况。保证删除的数不会再被加入,因为这样的一对操作没对集合做出改变。
但这样做一定搞不出与原集合等价的更优新集合。原因是:
假设删除的 $k$ 个数的最小值为 $x$,你加入的数至少有一个是 $x$ 的因子(且这个因子不等于自己,上面已经保证过)。
而原集合中存在 $x$,说明原集合中没有其它一个或一些数能表示出 $x$,也就必定没有 $x$ 的因子(否则那个 $x$ 的因子直接表示出 $x$ 了)。
但你加入了一个 $x$ 的因子,这样就一定不与原集合等价,因为你至少新表示了加入的 $x$ 的因子本身,而原集合不能表示这个数。
综上,已经搞不出与原集合等价的更优新集合。
看一下数据范围就知道是 排序+背包转移了……
不过数据比较水,写个爆搜判断一个数是否能被表示出来,瞎搞些优秀的剪枝,都可以过(比如 $SYF$)。
#include<cmath>
#include<cctype>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
inline int read(){
int x=; bool f=; char c=getchar();
for(;!isdigit(c);c=getchar()) if(c=='-') f=;
for(; isdigit(c);c=getchar()) x=(x<<)+(x<<)+(c^'');
if(f) return x;
return -x;
}
int T,n,a[];
bool vis[];
int main(){
//freopen("money.in","r",stdin);
//freopen("money.out","w",stdout);
T=read();
while(T--){
int ans;
n=ans=read();
int i,j;
for(i=;i<=n;++i) a[i]=read();
sort(a+,a+n+);
memset(vis,,sizeof vis);
for(i=;i<=n;++i){
if(vis[a[i]]){--ans; continue;}
vis[a[i]]=;
for(j=a[i]+;j<=;++j) vis[j]|=vis[j-a[i]];
}
printf("%d\n",ans);
}
return ;
}
3.赛道修建
题目描述
C 城将要举办一系列的赛车比赛。在比赛前,需要在城内修建 $m$ 条赛道。
C 城一共有 $n$ 个路口,这些路口编号为 $1,2,…,n$,有 $n−1$ 条适合于修建赛道的双向通行的道路,每条道路连接着两个路口。其中,第 $i$ 条道路连接的两个路口编号为 $a_i$ 和 $b_i$ ,该道路的长度为 $l_i$。借助这 $n−1$ 条道路,从任何一个路口出发都能到达其他所有的路口。
一条赛道是一组互不相同的道路 $e_1,e_2,…,e_k$,满足可以从某个路口出发,依次经过道路 $e_1,e_2,…,e_k$(每条道路经过一次,不允许调头)到达另一个路口。一条赛道的长度等于经过的各道路的长度之和。为保证安全,要求每条道路至多被一条赛道经过。
目前赛道修建的方案尚未确定。你的任务是设计一种赛道修建的方案,使得修建的 $m$ 条赛道中长度最小的赛道长度最大(即 $m$ 条赛道中最短赛道的长度尽可能大)。
输入输出格式
输入格式
输入文件第一行包含两个由空格分隔的正整数 $n,m$,分别表示路口数及需要修建的 赛道数。
接下来 $n−1$ 行,第 $i$ 行包含三个正整数 $a_i,b_i,l_i$,表示第 $i$ 条适合于修建赛道的道路连接的两个路口编号及道路长度。保证任意两个路口均可通过这 $n-1$ 条道路相互到达。每行中相邻两数之间均由一个空格分隔。
输出格式
输出共一行,包含一个整数,表示长度最小的赛道长度的最大值。
输入输出样例
输入样例#1
7 1
1 2 10
1 3 5
2 4 9
2 5 8
3 6 6
3 7 7
输出样例#1
31
输入样例#2
9 3
1 2 6
2 3 3
3 4 5
4 5 10
6 2 4
7 2 9
8 4 7
9 4 4
输出样例#2
15
说明
【输入输出样例 1 说明】
所有路口及适合于修建赛道的道路如下图所示:
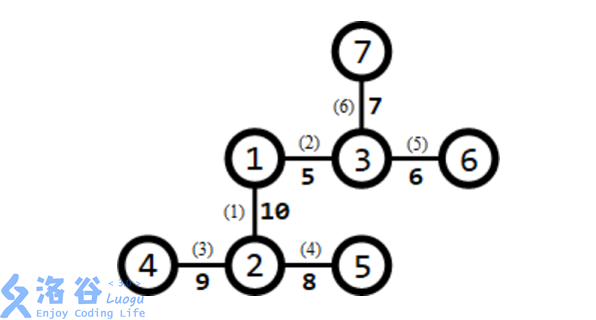
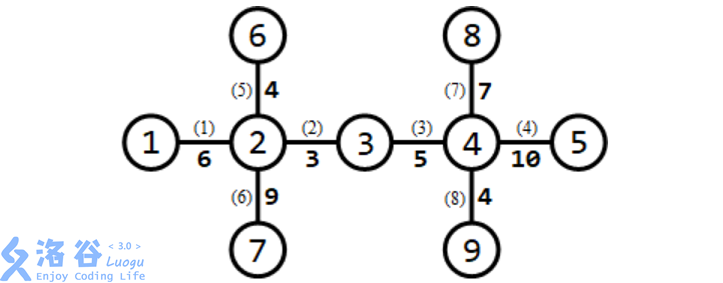
需要修建 $3$ 条赛道。可以修建如下 $3$ 条赛道:
1. 经过第 $1,6$ 条道路的赛道(从路口 $1$ 到路口 $7$),长度为 $6+9=15$;
2. 经过第 $5,2,3,8$ 条道路的赛道(从路口 $6$ 到路口 $9$),长度为 $4+3+5+4=16$;
3. 经过第 $7,4$ 条道路的赛道(从路口 $8$ 到路口 $5$),长度为 $7+10=17$。 长度最小的赛道长度为 $15$,为所有方案中的最大值。
【数据规模与约定】
所有测试数据的范围和特点如下表所示 :
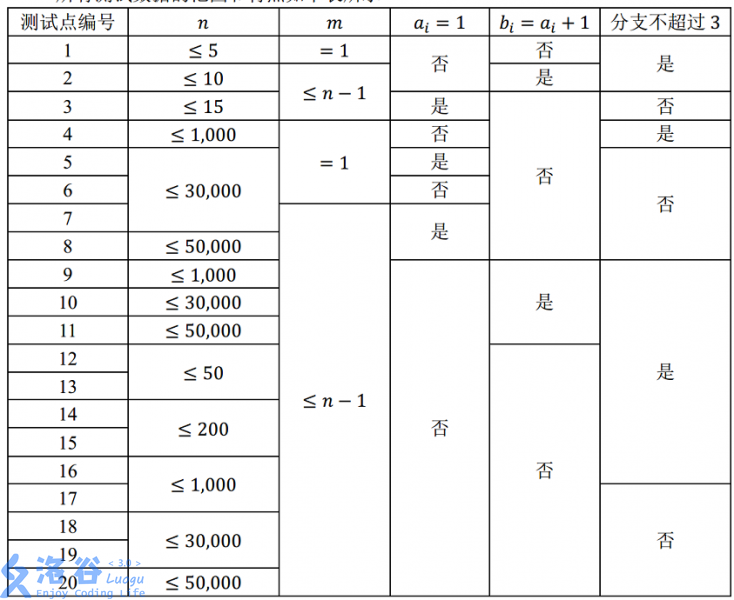
其中,“分支不超过 $3$”的含义为:每个路口至多有 $3$ 条道路与其相连。 对于所有的数据, $2 ≤ n ≤ 50,000,\space 1 ≤ m ≤ n-1,\space 1 ≤ a_i,b_i ≤ n,\space 1 ≤ l_i ≤ 10,000$。
看到“长度最小的赛道长度最大”就知道外层要二分答案了……
那怎么判断呢?运用一些树形 $dp$ 的思想就可以了。
设当前二分的答案为 $x$。
考虑树上的一个点,我们已经从下往上处理完了 以这个点为根的子树中 能修建的赛道数量,每个儿子上传了一个未完成的赛道,它们要么自己就是一条合法的赛道(直接把它们解决了),要么选出两条相连成一条合法的赛道(也称配对,即两条赛道长度和 $\ge x$),要么上传一条最大的无法完成的赛道(即长度 $\lt x$ 的未完成赛道,上传时加上父边长)。只能上传一条未完成赛道是因为父边只有一条,也只能让一条赛道经过,那我们当然贪心选尽量长的,剩下的没法两两配对的未完成赛道就不用了。
所以内层贪心做法比较显然:把一个点的所有儿子上传的未完成的赛道长 从小到大排序,然后每次取出并删除最短的一条,二分找出并删除 能与它拼成长度和 $\ge x$ 的一条赛道,总赛道数 $+1$;如果不存在这样的赛道,就更新要上传的赛道 为这条赛道——因为是按长度从小到大取,所以后取的未完成的赛道的长度一定更大,也就更应该上传。
这样贪心的正确性也是显然的。证明:假如现在你任意舍弃若干对 能连成合法赛道的未完成赛道 中最长的一个上去,最好情况下也就是在这棵子树中少弄出一条赛道,回到以某个祖先为根的子树时多弄出一条赛道(因为上传的未完成赛道的配对是一次性的),而不可能弄出更多。
在内层,只要凑够 $m$ 条合法赛道就直接退出,回到外层二分。如果不迅速退出的话,树的剩下部分都是白跑。这甚至不算“优化”,因为不这么做的话无论如何都稳稳的 $TLE$。
补充:注意一定要按长度从小到大取,而不能从大到小取,因为我们要尽量把一对短的未完成赛道 相连成合法赛道,而留长的未完成赛道 上传上去,因此大的赛道可能并不需要配对。
举个例子(每条边上的数表示对应儿子上传的未完成赛道的长度):
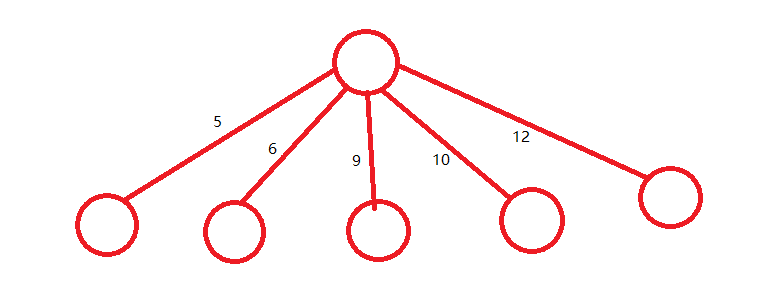
当 $x=15$ 时,第 $1,4$ 和 $2,3$ 个儿子明显可以配对成 $2$ 条赛道,然后上传那一条最长的长度为 $12$ 的未完成赛道。
总之在最优情况下,长的未完成赛道是配对还是上传 只受短赛道的需求情况的影响,如果短赛道不需要它,这条长赛道完全可以上传。因此从长到短取的话 不能确定取出的未完成赛道是配对更优还是上传更优,而从短到长取就能确定(它还存在就说明短赛道不需要它,尝试配对呗)。
所以这道题的重点:快速查数?删数?线段树?这题就要写数据结构了吗我的叔叔?
其实这些操作 $STL:multiset$ 都有……这种做法的时间复杂度在前面的游记中已经说过,是 $O(n\times log(n)\times log(5e8))$ 的,但 $multiset$ 的常数比较大。
// luogu-judger-enable-o2
#include<cmath>
#include<cctype>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<iostream>
#include<algorithm>
#include<set>
#define N 50010
using namespace std;
inline int read(){
int x=; bool f=; char c=getchar();
for(;!isdigit(c);c=getchar()) if(c=='-') f=;
for(; isdigit(c);c=getchar()) x=(x<<)+(x<<)+(c^'');
if(f) return x;
return -x;
} int n,m;
struct edge{int v,w,nxt;}e[N<<];
int head[N],cnt;
inline void add(int u,int v,int w){e[++cnt]=(edge){v,w,head[u]}, head[u]=cnt;}
int lim,num;
int dp[N];
multiset<int>s;
multiset<int>::iterator it,tmp;
bool flag;
void dfs(int u,int fa){
dp[u]=;
for(int i=head[u];i;i=e[i].nxt)
if(e[i].v^fa){
dfs(e[i].v,u);
if(flag) return;
}
s.clear();
//printf("dfs:%d %d\n",u,lim);
for(int i=head[u];i;i=e[i].nxt){
if(e[i].v^fa){
//printf("it son:%d %d %d\n",e[i].v,dp[e[i].v],e[i].w);
if(dp[e[i].v]+e[i].w>=lim) ++num;
else s.insert(dp[e[i].v]+e[i].w);
//printf("%d\n",s.size());
if(num>=m){flag=; return;}
}
}
int cur,pd;
//printf("%d\n",s.size());
for(it=s.begin();it!=s.end();it=s.begin()){
cur=*it;
s.erase(it);
if(!s.size()){if(cur>dp[u]) dp[u]=cur; break;}
tmp=s.lower_bound(lim-cur);
//printf("%d %d %d %d %d\n",s.size(),lim,cur,*tmp,tmp==s.begin());
if(tmp==s.end()){
if(cur>dp[u]) dp[u]=cur;
}
else{
s.erase(tmp);
++num;
if(num>=m){flag=; return;}
}
}
//printf("ret:%d %d %d\n",u,dp[u],num);
}
bool check(int mid){
lim=mid, num=, flag=;
dfs(,);
return flag;
}
int main(){
//freopen("track.in","r",stdin);
//freopen("track.out","w",stdout);
n=read(),m=read();
int i,u,v,w;
int l=,r=,mid,ans;
for(i=;i^n;++i) u=read(), v=read(), w=read(), r+=w, add(u,v,w), add(v,u,w);
while(l<=r){
mid=(l+r)>>;
//printf("binary:%d\n",mid);
if(check(mid)) ans=mid, l=mid+;
else r=mid-;
}
printf("%d\n",ans);
return ;
}
/*
4 1
1 2 2
2 3 2
2 4 1
*/
实测 $multiset$ 就可以通过官方数据了,可能是官方数据比较水吧。
这里介绍三个优化(我考场上都没用):
1. 提前判断“未完成赛道长度 $\ge x$ 的情况”
之前说过,儿子上传的未完成赛道 可能本身就是一条合法的赛道。所以可以在儿子处做上传时就判断它们。这样可能提前凑够赛道数,从而提早退出,再少跑树的一些部分。
2. 搞掉常数,变成严格 $O(n\times log^2)$
如果仔细读题,就会发现那些保证全部 $a_i=1$ 的点是菊花图,实践证明菊花图状的极端数据可以卡 $multiset$ 做法的常数(这就是为什么我luogu数据被卡了 $5$ 分)。所以我们考虑消掉常数。
当然这就不用 $multiset$ 了。
注意到一个长度序列从小到大排序后依次取,对于一个取出的长度 $x$,如果最小的能与它连成合法赛道的长度为 $y$,那对于下一个取到的长度 $x'$,因为 $x'\ge x$,所以 $y'\le y$。
然后你发现了什么?单调性!
所以把长度序列排序,在两端各设一个指针,然后两个指针相向扫就可以了,要确保左指针扫到的每个长度 都要通过右指针往左扫 尽量找到一个能与它配对的长度。
上传的未完成赛道的长度是 右指针第一个跳过的长度。
- 当然 $SYF$ 还有一个复杂度、常数相同的做法。
3. 改小二分范围
其实不用优化 $2$,只用这种优化也可以让 $multiset$ 卡过菊花图的极端数据!
你会发现菊花图的答案很小,原因是最大答案不会超过树的直径。
而树的直径可以 $O(n)$ 求出(从根开始求两次最远点),所以把二分答案的初始上界改为树的直径即可卡过像菊花图这样的数据。
像我这种不爱思考的选手,考场上直接把二分初始上界设为所有边权的和,出了考场后瑟瑟发抖怕被吊着卡。
以后还是得注意呀!毕竟这只是 $noip$。
人生中第一次 $AK$ 了一天正式比赛,留个纪念没啥问题吧~(虽然这可能是全世界都 $AK$ 系列)
4. 旅行
题目描述
小 Y 是一个爱好旅行的 OIer。她来到 X 国,打算将各个城市都玩一遍。
小Y了解到, X国的 $n$ 个城市之间有 $m$ 条双向道路。每条双向道路连接两个城市。不存在两条连接同一对城市的道路,也不存在一条连接一个城市和它本身的道路。并且, 从任意一个城市出发,通过这些道路都可以到达任意一个其他城市。小 Y 只能通过这些道路从一个城市前往另一个城市。
小 Y 的旅行方案是这样的:任意选定一个城市作为起点,然后从起点开始,每次可 以选择一条与当前城市相连的道路,走向一个没有去过的城市,或者沿着第一次访问该 城市时经过的道路后退到上一个城市。当小 Y 回到起点时,她可以选择结束这次旅行或 继续旅行。需要注意的是,小 Y 要求在旅行方案中,每个城市都被访问到。
为了让自己的旅行更有意义,小 Y 决定在每到达一个新的城市(包括起点)时,将 它的编号记录下来。她知道这样会形成一个长度为 $n$ 的序列。她希望这个序列的字典序最小,你能帮帮她吗? 对于两个长度均为 $n$ 的序列 $A$ 和 $B$,当且仅当存在一个正整数 $x$,满足以下条件时,我们说序列 $A$ 的字典序小于 $B$。
- 对于任意正整数 $1≤i<x$,序列 $A$ 的第 $i$ 个元素 $A_i$ 和序列 $B$ 的第 $i$ 个元素 $B_i$ 相同。
- 序列 $A$ 的第 $x$ 个元素的值小于序列 $B$ 的第 $x$ 个元素的值。
输入输出格式
输入格式
输入文件共 $m+1$ 行。第一行包含两个整数 $n,m(m≤n)$,中间用一个空格分隔。
接下来 $m$ 行,每行包含两个整数 $u,v(1≤u,v≤n)$ ,表示编号为 $u$ 和 $v$ 的城市之间有一条道路,两个整数之间用一个空格分隔。
输出格式
输出文件包含一行,$n$ 个整数,表示字典序最小的序列。相邻两个整数之间用一个 空格分隔。
输入输出样例
输入样例#1
6 5
1 3
2 3
2 5
3 4
4 6
输出样例#1
1 3 2 5 4 6
输入样例#2
6 6
1 3
2 3
2 5
3 4
4 5
4 6
输出样例#2
1 3 2 4 5 6
说明
【数据规模与约定】
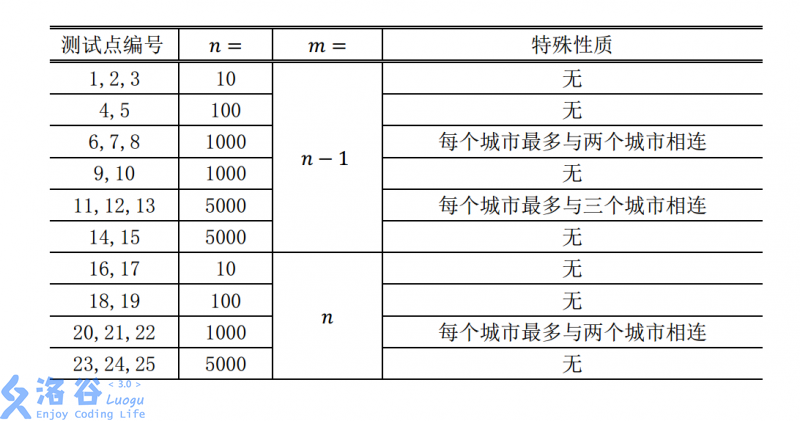
对于 $100\%$ 的数据和所有样例, $1 \le n \le 5000$ 且 $m = n − 1$ 或 $m = n$。
对于不同的测试点, 我们约定数据的规模如下:
估计是 $Day1$ 难度的原因,$Day2$ 上来就送了大礼包——怎么 $D2T1$ 就可以出有难度的题了!……
嗷,原来 $n=m$ 的简单连通图叫基环树啊(“基”就是简单、$simple$、一个的意思),我甚至还不知道。
题目意思不要看错了……如果是一棵树,你经过一条边再回来之后,就不能再经过这条边了。
也就是说你经过了这条边,就要把这条边下面的子树跑完再回来。
根据字典序的性质,前面的数越小越好,所以优先跑编号小的儿子就最优了,排个序就可以。
那如果是基环树呢?可以删一条边,因为我们发现环上一定有一条边是不用经过的。
那哪一条边不用经过呢?
方法1:枚举
就是枚举删去哪条边,然后跑一遍剩下的朴素树即可。时间复杂度 $O(n^2\times log(n))$。
然而这个时间会被卡,我们发现不用每次跑树时都进行排序,所以可以预处理每个点的所有儿子排序后的顺序。时间复杂度 $O(n\times log(n)+n^2)$。其实这个在考场上是最稳的……
方法2:use your brain to find it
我们知道,环的根(就是整棵树的根到环上距离最近的那个点)一定与环上的两个儿子连接,设小的那个为 $x$,那么在贪心遍历这个环时(即从根往编号小的儿子那边走),遇到的第一个编号 $\gt x$ 的点就停下,因为新到这个点 不如退回去新到那个编号为 $x$ 的点更优,所以下一步不应该走这个点,删掉它的父边就可以了(别忘了无向图要删两条有向边)。
但是考后发现,这个做法是错的,却艹了官方数据的 $92$ 分……
错的原因是,它没有考虑环上长的毛的影响。
比如这样一个图
按照如上做法,从环的根($1$ 号点)跑到 $2$ 号点,因为 $2$ 号店在环上的儿子 $4$ 比 $1$号点在环上的另一个儿子(没跑的那个)$3$ 号点小,所以会断掉 $2,4$ 号点的连边。
但实际上这样做不对,因为 如果 $2$ 号点下一步不走 $4$ 号点,那它得先走比 $4$ 号点大的 $5$ 号点(因为 $5$ 号点是环长出来的毛,也就是一棵树的根节点,所以必须要跑完这棵树才能回去),显然更不优。
所以更正上述算法,把环上那个儿子点 跟已经跑的环路径上的(包括当前点) 上一个长了比环路径上同层点更大的毛的点的 最小的一个 比较(因为如果割掉当前点与环上儿子点的连边,下一个新到的点就是上面那一堆黑字所述的点,也就是说两种路径的字典序大小 就取决于上述两点的大小了)。
理论时间复杂度为 $O(n\times log(n))$,但实际上对树上每个点的儿子排序的时间复杂度是略超过这个的,因为分批的 $log$ 级别排序的复杂度 $>$ 所有点的 $log$ 级别排序的复杂度,大概就是 $2$ 的次方数越大增长越快的缘故。若把排序改为基数排序可把复杂度降至 $O(n)$ 带点常数(我没写)。
#include<bits/stdc++.h>
#define N 500005
using namespace std;
inline int read(){
int x=; bool f=; char c=getchar();
for(;!isdigit(c);c=getchar()) if(c=='-') f=;
for(; isdigit(c);c=getchar()) x=(x<<)+(x<<)+(c^'');
if(f) return x;
return -x;
}
int n,m;
struct edge{int v,nxt;}e[N<<];
int head[N],cnt;
inline void add(int u,int v){e[++cnt]=(edge){v,head[u]}, head[u]=cnt;}
bool inq[N],vis[N],delVis[N];
int f[N];
int futa_u,futa_v,del1,del2;
int Min=,End=-,SecWay=; void delEdge(int u,int fa){
if(u==End){
for(int i=head[u];i;i=e[i].nxt){
del1=i;
if(del1&) del2=del1+;
else del2=del1-;
return;
}
}
int tmpMin=, tmpE;
bool out=;
for(int i=head[u];i;i=e[i].nxt)
if(e[i].v^fa && delVis[e[i].v]){tmpMin=e[i].v, tmpE=i; break;}
for(int i=head[u];i;i=e[i].nxt){
if(e[i].v^fa && !delVis[e[i].v] && e[i].v>tmpMin){
if(!out) out=, SecWay=;
SecWay=min(SecWay,e[i].v);
}
}
//printf("%d %d %d\n",u,tmpMin,SecWay); system("pause");
if(tmpMin>=SecWay){
//printf("%d %d %d\n",u,tmpMin,SecWay);
del1=tmpE;
if(del1&) del2=del1+;
else del2=del1-;
return;
}
delEdge(tmpMin,u);
}
bool gotR(int u,int fa){
//printf("%d\n",u);
if(vis[u]){
//printf("faq\n");
int x=fa, go=;
delVis[u]=;
while(x!=u) delVis[x]=, x=f[x], ++go; if(go>){
for(int i=head[u];i;i=e[i].nxt) if(delVis[e[i].v]){
//printf("%d\n",e[i].v);
Min=min(Min,e[i].v), End=max(End,e[i].v);
}//printf("root:%d\n",u);
SecWay=End;
delEdge(Min,u);
}
return ;
}
vis[u]=, f[u]=fa;
for(int i=head[u];i;i=e[i].nxt)
if(e[i].v^fa){
//printf("set_fa:%d %d %d\n",u,e[i].v,u);
if(gotR(e[i].v,u)) return ;
//printf("faq\n");
}
return ;
}
int v[N];
void dfs(int u,int fa,int l,int r){
if(u==) printf("");
else printf(" %d",u);
for(int i=head[u];i;i=e[i].nxt)
if(e[i].v^fa && del1^i && del2^i)
v[++r]=e[i].v;
sort(v+l,v+r+);
for(int i=l;i<=r;++i) dfs(v[i],u,r+,r);
}
//set<pair<int,int> >s;
int main(){
//freopen("testdata.in","r",stdin);
//freopen("travel.out","w",stdout);
n=read(),m=read();
int i,u,v;
for(i=;i<=m;++i){
u=read(),v=read(),add(u,v),add(v,u);
}
if(m==n) gotR(,);
dfs(,,,);
return ;
}
Extra:某些省的某些大佬写的朴素树的做法
5. 填数游戏
此题征集规律证明,如有知道的大佬请在评论里回复,谢谢^_^
6. 保卫王国
题目描述
Z 国有 $n$ 座城市,$n−1$ 条双向道路,每条双向道路连接两座城市,且任意两座城市都能通过若干条道路相互到达。
Z 国的国防部长小 Z 要在城市中驻扎军队。驻扎军队需要满足如下几个条件:
- 一座城市可以驻扎一支军队,也可以不驻扎军队。
- 由道路直接连接的两座城市中至少要有一座城市驻扎军队。
- 在城市里驻扎军队会产生花费,在编号为i的城市中驻扎军队的花费是 $p_i$。
在城市里驻扎军队会产生花费,在编号为i的城市中驻扎军队的花费是 $p_i$。
小 Z 很快就规划出了一种驻扎军队的方案,使总花费最小。但是国王又给小 Z 提出 了 $m$ 个要求,每个要求规定了其中两座城市是否驻扎军队。小 Z 需要针对每个要求逐一给出回答。具体而言,如果国王提出的第 $j$ 要求能够满足上述驻扎条件(不需要考虑第 $j$ 个要求之外的其它要求),则需要给出在此要求前提下驻扎军队的最小开销。如果国王提出的第 $j$ 个要求无法满足,则需要输出 $-1(1≤j≤m)$。现在请你来帮助小 Z。
输入描述
第 $1$ 行包含两个正整数 $n,m$ 和一个字符串 $type$,分别表示城市数、要求数和数据类型。$type$ 是一个由大写字母 $A$,$B$ 或 $C$ 和一个数字 $1$,$2$,$3$ 组成的字符串。它可以帮助你获得部分分。你可能不需要用到这个参数。这个参数的含义在【数据规模与约定】中 有具体的描述。
第 $2$ 行 $n$ 个整数 $p_i$,表示编号 $i$ 的城市中驻扎军队的花费。
接下来 $n−1$ 行,每行两个正整数 $u,v$,表示有一条 $u$ 到 $v$ 的双向道路。
接下来 $m$ 行,第 $j$ 行四个整数 $a,x,b,y(a≠b)$,表示第 $j$ 个要求是在城市 $a$ 驻扎 $x$ 支军队, 在城市 $b$ 驻扎 $y$ 支军队。其中,$x$、$y$ 的取值只有 $0$ 或 $1$:若 $x$ 为 $0$,表示城市 $a$ 不得驻扎军队,若 $x$ 为 $1$,表示城市 $a$ 必须驻扎军队;若 $y$ 为 $0$,表示城市 $b$ 不得驻扎军队,若 $y$ 为 $1$,表示城市 $b$ 必须驻扎军队。
输入文件中每一行相邻的两个数据之间均用一个空格分隔。
输出描述
输出共 $m$ 行,每行包含 $1$ 个整数,第jj行表示在满足国王第 $j$ 个要求时的最小开销, 如果无法满足国王的第 $j$ 个要求,则该行输出 $-1$。
输入输出样例
输入样例#1
5 3 C3
2 4 1 3 9
1 5
5 2
5 3
3 4
1 0 3 0
2 1 3 1
1 0 5 0
输出样例#1
12
7
-1
说明
【样例解释】
对于第一个要求,在 $4$ 号和 $5$ 号城市驻扎军队时开销最小。
对于第二个要求,在 $1$ 号、$2$ 号、$3$ 号城市驻扎军队时开销最小。
第三个要求是无法满足的,因为在 $1$ 号、$5$ 号城市都不驻扎军队就意味着由道路直接连接的两座城市中都没有驻扎军队。
【数据规模与约定】
对于 $100\%$ 的数据,$n,m≤100000, 1≤p_i≤100000$。
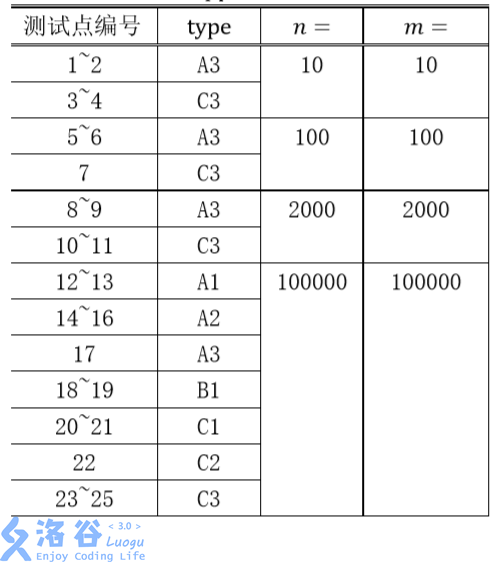
数据类型的含义:
$A$:城市 $i$ 与城市 $i+1$ 直接相连。
$B$:任意城市与城市 $1$ 的距离不超过 $100$(距离定义为最短路径上边的数量),即如果这棵树以 $1$ 号城市为根,深度不超过 $100$。
$C$:在树的形态上无特殊约束。
$1$:询问时保证 $a=1,x=1$,即要求在城市 $1$ 驻军。对 $b,y$ 没有限制。
$2$:询问时保证 $a,b$ 是相邻的(由一条道路直接连通)
$3$:在询问上无特殊约束。
某些人表示见过动态 $dp$ 板子……
然后就发现这题其实就是动态 $dp$ 板子题的弱化版(不带修改)。
然后就不会打动态 $dp$,陷入自闭
然而,还是那句话,$noip$ 的官方正解不会是一些太变态的内容的(不过我个人为打表找规律就很变态)。
所以这题是倍增 $dp$(动态 $dp$ 的做法后面也会说)。
不过这题的无解很好判,只有强制一条边连接的两个点同时不驻防时,才会无解。
前44pts:
对于每组询问暴力重做一遍 $dp$。
#include<cmath>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<iostream>
#include<algorithm>
#define N 2005
const long long inf=300010ll*;
using namespace std;
inline int read(){
int x=; bool f=; char c=getchar();
for(;!isdigit(c);c=getchar()) if(c=='-') f=;
for(; isdigit(c);c=getchar()) x=(x<<)+(x<<)+(c^'');
if(f) return x;
return -x;
}
int n,m,p[N],a,x,b,y; char ch[]; bool Mat[N][N];
struct edge{int v,nxt;}e[N<<];
int head[N],cnt;
inline void add(int u,int v){e[++cnt]=(edge){v,head[u]}, head[u]=cnt;}
long long dp[N][]; void DP(int u,int fa){
//printf("%d %d\n",u,fa);
for(int i=head[u];i;i=e[i].nxt) if(e[i].v^fa) DP(e[i].v,u);
if(!(u==a && x==) && !(u==b && y==)){
long long jia;
for(int i=head[u];i;i=e[i].nxt)
if(e[i].v^fa){
jia=min(dp[e[i].v][],dp[e[i].v][]);
if(jia<inf) dp[u][]+=jia; //考后才发现,事实上可以证明 只有下面相邻两个点都被禁止驻军时才会出现这种情况,但这种情况在dp前已经判过了
}
dp[u][]+=p[u];
//printf("1 %d:%d\n",u,dp[u][1]);
}
else dp[u][]=inf;
if(!(u==a && x==) && !(u==b && y==)){
for(int i=head[u];i;i=e[i].nxt)
if(e[i].v^fa) dp[u][]+=dp[e[i].v][];
//printf("0 %d:%d\n",u,dp[u][0]);
if(dp[u][]>inf) dp[u][]=inf;
}
else dp[u][]=inf;
}
int main(){
//freopen("defense.in","r",stdin);
//freopen("defense.out","w",stdout);
n=read(),m=read();
scanf("%s",ch);
int i,j,u,v;
for(i=;i<=n;++i) p[i]=read();
for(i=;i^n;++i) u=read(),v=read(),Mat[u][v]=Mat[v][u]=,add(u,v),add(v,u);
while(m--){
a=read(),x=read(),b=read(),y=read();
if(Mat[a][b] && x== && y==) printf("-1\n");
else{
memset(dp,,sizeof dp);
DP(,);
printf("%lld\n",min(dp[][],dp[][]));
}
}
return ;
}
44分暴力
B1 8pts(这部分我在考场上直接没看见,太亏了):
不难发现,强制两点的状态 只可能对两点的所有祖先的 $dp$ 值有影响,像一个倒 $y$ 字形。
而 $B$ 的限制是树高不超过 $100$,所以我们可以暴力改这些祖先的 $dp$ 值。
实际上,由于还有 $1$ 的限制,有一个修改点必定是根,所以只需要改一条链就行了。
A 24pts(树是链):
100pts:
方法1:倍增dp
可以发现,
后记
noip2018——题解&总结的更多相关文章
- NOIP2018题解
Preface 联赛结束后趁着自己还没有一下子把题目忘光,所以趁机改一下题目. 没有和游记一起写主要是怕篇幅太长不美观. 因此这里我们直接讲题目,关于NOIP2018的一些心得和有趣的事详见:NOIP ...
- NOIP2018划水记
// 6次NOIP里最爽的一次 去年的NOIP的游记:https://www.cnblogs.com/GXZlegend/p/7880740.html Day 0 特意请了一天假复习NOIP 实际上是 ...
- WC2019 20天训练
Day -1 2019.1.2 初步计划: 0x60 图论 std 洛谷提高剩余练习 NOIP2018遗留题解 洛谷省选基础练习 数学: 1.数论 2.组合数学(练习:莫比乌斯反演) 3.概率(练习: ...
- [题解]NOIP2018(普及组)T1标题统计(title)
NOIP2018(普及组)T1标题统计(title) 题解 [代码(AC)] #include <iostream> #include <cstdio> #include &l ...
- 【NOIP2018】提高组题解
[NOIP2018]提高组题解 其实就是把写过的打个包而已 道路铺设 货币系统 赛道修建 旅行 咕咕咕 咕咕咕
- 竞赛题解 - NOIP2018 保卫王国
\(\mathcal{NOIP2018}\) 保卫王国 - 竞赛题解 按某一个炒鸡dalao名曰 taotao 的话说: \(\ \ \ \ \ \ \ \ \ "一道sb倍增题" ...
- 竞赛题解 - NOIP2018 旅行
\(\mathcal {NOIP2018} 旅行 - 竞赛题解\) 坑还得一层一层的填 填到Day2T1了 洛谷 P5022 题目 (以下copy自洛谷,有删减/修改 (●ˇ∀ˇ●)) 题目描述 小 ...
- 竞赛题解 - NOIP2018 赛道修建
\(\mathcal {NOIP2018}\) 赛道修建 - 竞赛题解 额--考试的时候大概猜到正解,但是时间不够了,不敢写,就写了骗分QwQ 现在把坑填好了~ 题目 (Copy from 洛谷) 题 ...
- NOIP2018初赛普及组原题&题解
NOIP2018初赛普及组原题&题解 目录 NOIP2018初赛普及组原题&题解 原题&答案 题解 单项选择题 第$1$题 第$2$题 第$3$题 第$4$题 第$5$题 第$ ...
随机推荐
- java冒泡排序和快速排序代码
冒泡排序: package nicetime.com; //基本思想:在要排序的一组数中,对当前还未排好序的范围内的全部数,自上而下对相邻的两个数依次进行比较和调整,// 让较大的数往下沉,较小的往上 ...
- 洛谷 P1330 封锁阳光大学
题目描述 曹是一只爱刷街的老曹,暑假期间,他每天都欢快地在阳光大学的校园里刷街.河蟹看到欢快的曹,感到不爽.河蟹决定封锁阳光大学,不让曹刷街. 阳光大学的校园是一张由N个点构成的无向图,N个点之间由M ...
- codevs 1146 ISBN号码
时间限制: 1 s 空间限制: 128000 KB 题目等级 : 白银 Silver 题目描述 Description 每一本正式出版的图书都有一个ISBN号码与之对应,ISBN码包括9位数字.1 ...
- codevs 1390 回文平方数 USACO
时间限制: 1 s 空间限制: 128000 KB 题目等级 : 青铜 Bronze 题目描述 Description 回文数是指从左向右念和从右像做念都一样的数.如12321就是一个典型的回文数 ...
- springmvc+maven搭建web项目
1.创建一个maven project 为spring1 2.进行项目的配置:默认的java 1.5 在properties中选择project facts项目进行配置,反选web之后修改java环境 ...
- Asp.Net Core 入门(六)—— 路由
Asp.Net Core MVC的路由在Startup.cs文件中的Configure方法中进行配置,使其加入到Http请求管道中,如果不配置,那么我们所发送的请求无法得到象应. 那么该怎么配置Asp ...
- mask rcnn和roi-align
faster-rcnn的github源码中是round四舍五入 但kaiming he的ppt是直接取整 1.讲roi-align和roi-pooling区别并且详细阐述roi-align过程的博客: ...
- Caused by: java.lang.ClassNotFoundException: java.com.bj186.ssm.controller.UserController
在搭建SpringMVC的时候,遇到的这个问题真的很奇葩, 找不到UserController这个类 这明明不就在工程目录下吗? 经过了一番艰苦卓绝的斗争, 才发现原来是包导少了 之前导入的包是: & ...
- python之道06
1,使⽤循环打印以结果: * *** ***** ******* ********* 答案: 方法一: for i in range(10): if i % 2 == 1: print(i*'*') ...
- MYSQL - 限制资源的使用
MYSQL - 限制资源的使用 1.MAX_QUERIES_PER_HOUR 用来限制用户每小时运行的查询数量 mysql> grant select on *.* to 'cu_blog'@' ...