Python爬虫-代理池-爬取代理入库并测试代理可用性
目的:建立自己的代理池。可以添加新的代理网站爬虫,可以测试代理对某一网址的适用性,可以提供获取代理的 API。
整个流程:爬取代理 ----> 将代理存入数据库并设置分数 ----> 从数据库取出代理并检测 ----> 根据响应结果对代理分数进行处理 ----> 从 API 取出高分代理 ----> 用高分代理爬取目标网站
分析:
1、爬虫类的编写:负责抓取代理并返回。
- 因为不同的代理网站的网页结构不同,所以需要单独为每一个代理网页写爬虫。
- 调用每个爬取方法,依次返回结果。
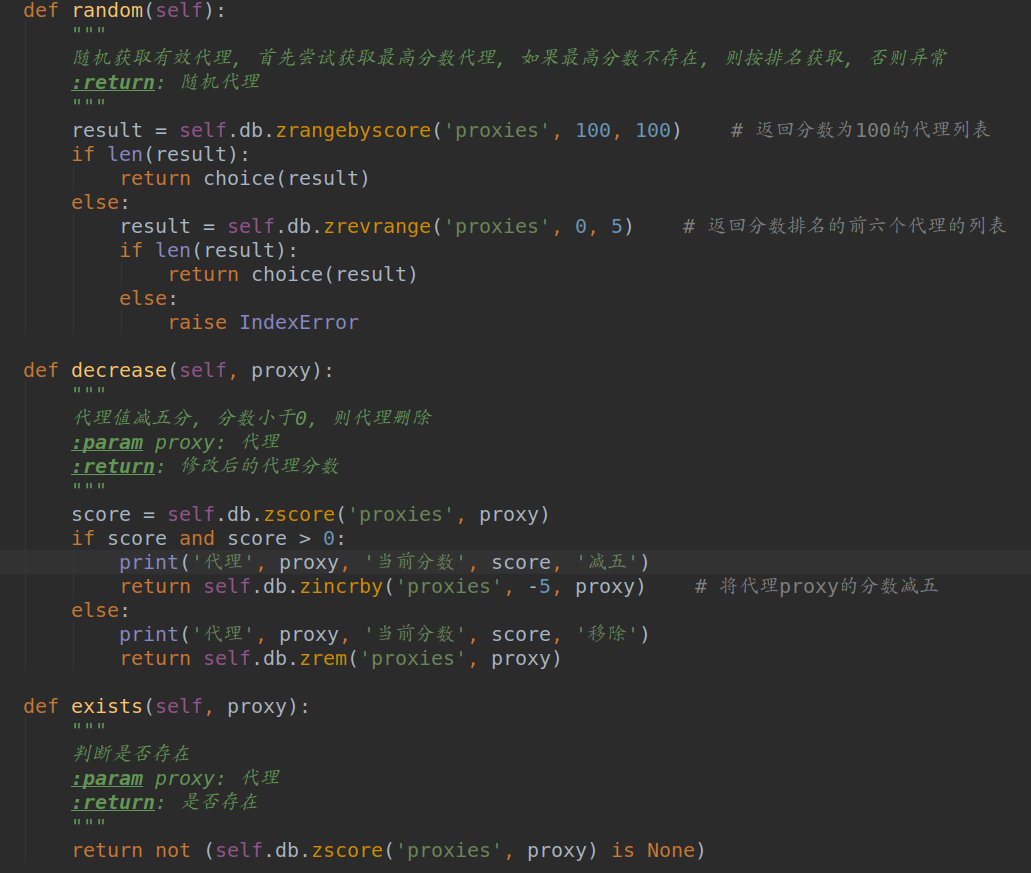
2、数据库类的编写:负责代理的存取与代理分数的设置。
- 判断待存入代理是否存在,不存在便存入数据库。
- 将代理存入数据库,首次入库的代理分数设置为100。
- 代理测试失败时,代理分数做相应的扣除,分数低于指定值时从数据库中移除。代理测试成功时,将代理分数重新设置为100。
- 需要使用代理时,从数据库中随机取出高分代理。
3、保存类的编写:负责执行爬取,并将结果存入数据库。
- 判断数据库是否已经达到满足值,根据返回值决定是否执行爬取。
- 将爬取得到的结果存入数据库
4、测试代理类的编写:负责测试代理对目标网站的可用性。
- 用每一个代理爬取目标网站,根据响应状态码对代理分数进行设置。
5、提取代理 API 的编写:负责提供获取代理信息的接口。
具体实现:
1、Crawler:

2、RedisClient:
3、Saver:

4、Tester:

5、API:

总结:这里我只爬取了两个代理网站的代理,西刺和快代理,可以在 Crawler 类中添加名称以 crwal_ 开始的方法来扩充。详细代码我放到 Github上了,https://github.com/ysl125963/proxy-pool
Python爬虫-代理池-爬取代理入库并测试代理可用性的更多相关文章
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
随机推荐
- Ubuntu 设置文件默认打开的应用
右键单击该文件,然后点击属性,打开属性面板 然后进入open with的选项,选择应用后,点击 set as default
- Almost Acyclic Graph Codeforces - 915D
以前做过的题都不会了.... 此题做法:优化的暴力 有一个显然的暴力:枚举每一条边试着删掉 注意到题目要求使得图无环,那么找出图上任意一个环,都应当要在其某一处断开(当然没有环是YES) 因此找出图中 ...
- jmeter(十九)调试工具Debug Sampler
一.Debug Sampler介绍: 使用Jmeter开发脚本时,难免需要调试,这时可以使用Jmeter的Debug Sampler,它有三个选项:JMeter properties,JMeter v ...
- CentOS 7.2安装pip
CentOS 7.2默认安装的python版本为python2.7.5,我的系统里面默认是没有安装pip 的,搜了下网上各路大侠的解决办法,如下: 使用yum安装python-pip,但是报错,说没有 ...
- 【solr filter 介绍--转】http://blog.csdn.net/jiangchao858/article/details/54989025
Solr的Analyzer分析器.Tokenizer分词器.Filter过滤器的区别/联系 Analyzer负责把文本字段转成token stream,然后自己处理.或调用Tokenzier和Filt ...
- slimScroll的应用(一)
本类文章依旧是针对初学者来说的,希望大家看到后觉得有用的能给个赞~~ 什么是slimScroll? 一.官网介绍: slimScroll is a small (4.6KB) jQuery plugi ...
- Spring-bean(一)
配置形式:基于xml文件的方式:基于注解的方式 Bean的配置方式:通过全类名(反射),通过工厂方法(静态工厂方法&实例工厂方法),FactoryBean 依赖注入的方式:属性注入,构造器注入 ...
- 教你如何配置WampServer
httpdconfig 搜索deny 268行 Deny 换成Allow 在本机cmd 搜索 ipconfig 找到 本机的ip 地址 239 行 DocumentRoot "e:/mywe ...
- Spring中@Value的使用
- Linux系统使用iftop查看带宽占用情况
Linux系统下如果服务器带宽跑满了,查看跟哪个ip通信占用带宽比较多,可以通过iftop命令进行查询,使用方法如下: 1 安装方法[软件官网地址:http://www.ex-parrot.com/~ ...