anchor_target_layer层其他部分解读
inds_inside = np.where(
(all_anchors[:, 0] >= -self._allowed_border) &
(all_anchors[:, 1] >= -self._allowed_border) &
(all_anchors[:, 2] < im_info[1] + self._allowed_border) & # width
(all_anchors[:, 3] < im_info[0] + self._allowed_border) # height
)[0] # keep only inside anchors
anchors = all_anchors[inds_inside, :]
这部分代码是把所有anchor中超过了图片边界部分的anchor去掉,即论文中说的cross-boundary anchors
# fg label: for each gt, anchor with highest overlap
labels[gt_argmax_overlaps] = 1 # fg label: above threshold IOU
labels[max_overlaps >= cfg.TRAIN.RPN_POSITIVE_OVERLAP] = 1
这部分代码是把和gt-roi有最大iou的anchor和与任何gt-roi iou大于0.7的anchor的label置为1,即前景。这和论文中所说的是一样的。
if cfg.TRAIN.RPN_CLOBBER_POSITIVES:
# assign bg labels last so that negative labels can clobber positives
labels[max_overlaps < cfg.TRAIN.RPN_NEGATIVE_OVERLAP] = 0
把和所有gt-roi iou都小于0.3的achor的label置为0
# label: 1 is positive, 0 is negative, -1 is dont care
labels = np.empty((len(inds_inside), ), dtype=np.float32)
labels.fill(-1)
这是label的初始化的代码,所有的label都置为-1
所以总的来看,label分为3类,一类是0,即背景label;一类是1,即前景label;另一类既不是前景也不是背景,置为-1。论文中说只有前景和背景对训练目标有用,这种-1的label对训练没用。
# subsample positive labels if we have too many
num_fg = int(cfg.TRAIN.RPN_FG_FRACTION * cfg.TRAIN.RPN_BATCHSIZE)
fg_inds = np.where(labels == 1)[0]
if len(fg_inds) > num_fg: #从所有label为1的anchor中选择128个,剩下的anchor的label全部置为-1
disable_inds = npr.choice(
fg_inds, size=(len(fg_inds) - num_fg), replace=False)
labels[disable_inds] = -1 # subsample negative labels if we have too many
num_bg = cfg.TRAIN.RPN_BATCHSIZE - np.sum(labels == 1)#这里num_bg不是直接设为128,而是256减去label为1的个数,这样如果label为1的不够,就用label为0的填充,这个代码实现很巧
bg_inds = np.where(labels == 0)[0]
if len(bg_inds) > num_bg: #将没被选择作为训练的anchor的label置为-1
disable_inds = npr.choice(
bg_inds, size=(len(bg_inds) - num_bg), replace=False)
labels[disable_inds] = -1
#print "was %s inds, disabling %s, now %s inds" % (
#len(bg_inds), len(disable_inds), np.sum(labels == 0))
论文中说从所有anchor中随机选取256个anchor,前景128个,背景128个。注意:那种label为-1的不会当前景也不会当背景。
这两段代码是前一部分是在所有前景的anchor中选128个,后一部分是在所有的背景achor中选128个。如果前景的个数少于了128个,就把所有的anchor选出来,差的由背景部分补。这和fast rcnn选取roi一样。
这是论文中rpn的loss函数:
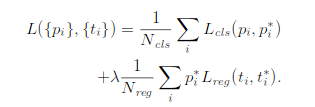
这个loss函数和fast rcnn中的loss函数差不多,所以在计算的时候是每个坐标单独进行smoothL1计算,所以参数Pi*和Nreg必须弄成4维的向量,并不是在论文中的就一个数值
bbox_inside_weights = np.zeros((len(inds_inside), 4), dtype=np.float32)
bbox_inside_weights[labels == 1, :] = np.array(cfg.TRAIN.RPN_BBOX_INSIDE_WEIGHTS) bbox_outside_weights = np.zeros((len(inds_inside), 4), dtype=np.float32)
if cfg.TRAIN.RPN_POSITIVE_WEIGHT < 0:
# uniform weighting of examples (given non-uniform sampling)
num_examples = np.sum(labels >= 0)
positive_weights = np.ones((1, 4)) * 1.0 / num_examples
negative_weights = np.ones((1, 4)) * 1.0 / num_examples
else:
assert ((cfg.TRAIN.RPN_POSITIVE_WEIGHT > 0) &
(cfg.TRAIN.RPN_POSITIVE_WEIGHT < 1))
positive_weights = (cfg.TRAIN.RPN_POSITIVE_WEIGHT /
np.sum(labels == 1))
negative_weights = ((1.0 - cfg.TRAIN.RPN_POSITIVE_WEIGHT) /
np.sum(labels == 0))
bbox_outside_weights[labels == 1, :] = positive_weights
bbox_outside_weights[labels == 0, :] = negative_weights
bbox_inside_weights实际上指的就是Pi*,bbox_outside_weights指的是Nreg。
论文中说如果anchor是前景,Pi*就是1,为背景,Pi*就是0。label为-1的,在这个代码来看也是设置为0,应该是在后面不会参与计算,这个设置为多少都无所谓。
Nreg是进行标准化操作,就是取平均。这个平均是把所有的label 0和label 1加起来。因为选的是256个anchor做训练,所以实际上这个值是1/256。
值得注意的是,rpn网络的训练是256个anchor,128个positive,128个negative。但anchor_target_layer层的输出并不是只有256个anchor的label和坐标变换,而是所有的anchor。其中_unmap函数就很好体现了这一点。那训练的时候怎么实现训练这256个呢?实际上,这一层的4个输出,rpn_labels是需要输出到rpn_loss_cls层,其他的3个输出到rpn_loss_bbox,label实际上就是loss function前半部分中的Pi*(即计算分类的loss),这是一个log loss,为-1的label是无法进行log计算的,剩下的0、1就直接计算,这一部分实现了256。loss function后半部分是计算bbox坐标的loss,Pi*,也就是bbox_inside_weights,论文中说了activated only for positive anchors,只有为正例的anchor才去计算坐标的损失,这是Pi*是1,其他情况都是0
bbox_inside_weights = np.zeros((len(inds_inside), 4), dtype=np.float32)
bbox_inside_weights[labels == 1, :] = np.array(cfg.TRAIN.RPN_BBOX_INSIDE_WEIGHTS)
这段代码也体现了这个思想,所以这也实现了256。
可以这样去理解:anchor_target_layer输出的是所有anchor的label,bbox_targets。但真正进行了loss计算的只有那256个anchor。可以看下面这个loss函数,i是anchor的下标,这个i计算是计算了所有的anchor的,但只有那256个才真正改变了loss值,其他的都是0。
_unmap函数:因为all_anchors裁减掉了2/3左右,仅仅保留在图像内的anchor。这里就是将其复原作为下一层的输入了,并reshape成相应的格式。
anchor_target_layer层其他部分解读的更多相关文章
- anchor_target_layer层解读
总结下来,用generate_anchors产生多种坐标变换,这种坐标变换由scale和ratio来,相当于提前计算好.anchor_target_layer先计算的是从feature map映射到原 ...
- Tensorflow-slim 学习笔记(二)第一层目录代码解读
通过阅读代码来学习,一向时最直接快速的.本章将讲解slim的第一层目录tensorflow/tensorflow/contrib/slim/python/slim的代码. 本层代码主要包括learni ...
- OSI七层协议大白话解读
参考链接:https://www.cnblogs.com/zx125/p/11295985.html 国际标准化组织(ISO)制定了osi七层模型,iso规定了各种各样的协议,并且分了7层 应用层 应 ...
- proposal_layer.py层解读
proposal_layer层是利用训练好的rpn网络来生成region proposal供fast rcnn使用. proposal_layer整个处理过程:1.生成所有的anchor,对ancho ...
- caffe︱ImageData层、DummyData层作为原始数据导入的应用
Part1:caffe的ImageData层 ImageData是一个图像输入层,该层的好处是,直接输入原始图像信息就可以导入分析. 在案例中利用ImageData层进行数据转化,得到了一批数据. 但 ...
- 数据通讯与网络 第五版第24章 传输层协议-UDP协议部分要点
24.1 介绍 本章节主要集中于传输层协议的解读,图24.1展示TCP.UDP.SCTP在TCP\IP协议栈的位置 24.1.1 服务(Service) 每个协议都提供不同的服务,所以应该合理正确的使 ...
- ERNIE代码解析
原创作者 |疯狂的Max ERNIE代码解读 考虑到ERNIE使用BRET作为基础模型,为了让没有基础的NLPer也能够理解代码,笔者将先为大家简略的解读BERT模型的结构,完整代码可以参见[1]. ...
- v87.01 鸿蒙内核源码分析 (内核启动篇) | 从汇编到 main () | 百篇博客分析 OpenHarmony 源码
本篇关键词:内核重定位.MMU.SVC栈.热启动.内核映射表 内核汇编相关篇为: v74.01 鸿蒙内核源码分析(编码方式) | 机器指令是如何编码的 v75.03 鸿蒙内核源码分析(汇编基础) | ...
- BiLSTM-CRF模型中CRF层的解读
转自: https://createmomo.github.io/ BiLSTM-CRF模型中CRF层的解读: 文章链接: 标题:CRF Layer on the Top of BiLSTM - 1 ...
随机推荐
- sphinx是支持结果聚类的
Coreseek 4.1 参考手册 / Sphinx 2.0.1-beta Sphinx--强大的开源全文检索引擎,Coreseek--免费开源的中文全文检索引擎 版权 © 2001-2011 And ...
- python 面向对象六 动态添加方法 __slots__限制动态添加方法
一.动态添加属性 >>> class Student(object): pass >>> st = Student() >>> st.name = ...
- bzoj 2208: [Jsoi2010]连通数【tarjan+拓扑+dp】
我总觉得枚举点bfs也行-- tarjan缩点,记一下每个scc的size,bitset压一下scc里的点,然后按拓扑倒序向上合并到达状态,然后加ans的时候记得乘size #include<i ...
- bzoj 1079: [SCOI2008]着色方案【记忆化搜索】
本来打算把每个颜色剩下的压起来存map来记忆化,写一半发现自己zz了 考虑当前都能涂x次的油漆本质是一样的. 直接存五个变量分别是剩下12345个格子的油漆数,然后直接开数组把这个和步数存起来,记忆化 ...
- XML(php中获取xml文件的方式/ajax获取xml格式的响应数据的方式)
1.XML 格式规范: ① 必须有一个根元素 ② 不可有空格.不可以数字或.开头.大小写敏感 ③ 不可交叉嵌套 ④ 属性双引号(浏览器自动修正成双引号了) ⑤ 特殊符号要使用实体 ⑥ 注释和HTML一 ...
- 关于自增id 你可能还不知道
导读:在使用MySQL建表时,我们通常会创建一个自增字段(AUTO_INCREMENT),并以此字段作为主键.本篇文章将以问答的形式讲述关于自增id的一切. 注: 本文所讲的都是基于Innodb存储引 ...
- centos 7 添加普通用户
adduser username username 是你要创建的用户名 passwd username 创建密码,输入个稍微复杂的 usermod -a -G wheel username 将用户加入 ...
- _bzoj1070 [SCOI2007]修车【最小费用最大流】
传送门:http://www.lydsy.com/JudgeOnline/problem.php?id=1070 以后做网络流题目就是不能省内存... #include <cstdio> ...
- [hdu4089] Activation【概率dp 数学期望】
传送门:http://acm.hdu.edu.cn/showproblem.php?pid=4089 本来可以一遍过的,结果mle了一发...注意要用滚动数组. 令f(i, j)表示队列剩余i个人,这 ...
- ACM牛人博客
ACM牛人博客 kuangbin kuangbin(新) wuyiqi wuyiqi(新) ACM!荣耀之路! 九野的博客 传说中的ACM大牛!!! read more