Apache Flink 1.5.0 Release Announcement
Apache Flink: Apache Flink 1.5.0 Release Announcement https://flink.apache.org/news/2018/05/25/release-1.5.0.html
Apache Flink 1.5.0 Release Announcement
25 May 2018 Fabian Hueske (@fhueske)
The Apache Flink community is thrilled to announce the 1.5.0 release. Over the past 5 months, the Flink community has been working hard to resolve more than 780 issues. Please check the complete changelog for more detail.
Flink 1.5.0 is the sixth major release in the 1.x.y series. As usual, it is API-compatible with previous 1.x.y releases for APIs annotated with the @Public annotation.
We encourage everyone to download the release and check out the documentation. Feedback through the Flink mailing lists or JIRAis, as always, very much appreciated!
You can find the binaries on the updated Downloads page on the Flink project site.
Flink 1.5 - Streaming Evolved
We believe that the field of stream processing, and Apache Flink with it, is taking another major leap at the moment. Stream processing is not just faster analytics and a more principled way of building fast continuous data pipelines. Stream processing is becoming a paradigm to build data-driven and data-intensive applications - it brings together data processing logic and application/business logic.
To help users realize the potential of this change, we spent a lot of effort in this release to rework some fundamental pieces of Flink. We want Flink to feel natural to users who do data engineering / data processing, as well as users who build data/event-driven applications (and of course those who combine both aspects inside their applications). This is an ongoing journey, but here are the first steps on this way:
We have redesigned and reimplemented large parts of Flink’s process model. This effort has been tracked under the name FLIP-6. While not all is completed yet, the changes in Flink 1.5 enable more natural Kubernetes deployments and switch to HTTP/REST for all external communication (to naturally interact with service proxies). Simultaneously, Flink 1.5 simplifies deployments on common cluster managers (YARN, Mesos) and features dynamic resource allocation.
Streaming broadcast state (FLINK-4940) connects a broadcasted stream (e.g., context data, machine learning models, rules/patterns, triggers, …) with other streams that may maintain (large) keyed state, such as feature vectors, state machines, etc. Prior to Flink 1.5, such use cases could not be easily built.
To improve support for real-time applications with tight latency constraints, we made major improvements to Flink’s network stack (FLINK-7315). Flink 1.5 achieves even lower latencies while maintaining a high throughput. In addition, we improved checkpoint stability under backpressure.
Streaming SQL is more and more recognized as a simple and powerful way to perform streaming analytics, build data pipelines, do feature engineering, or incrementally keep applications updated on changing data. We added a SQL CLI for streaming SQL queries (FLIP-24) to make this feature easier to get started with.
New Features and Improvements
Rewrite of Flink’s Deployment and Process Model
The rewrite of Flink’s deployment and process model (internally known as FLIP-6) has been in the works for more than a year and was a substantial effort from the Flink community. Many contributors from several organizations, such as data Artisans, Alibaba, and Dell EMC, collaborated on the design and implementation of this feature, which has been the most significant improvement of a Flink core component since the project’s inception.
In a nutshell, the improvements add support for dynamic resource allocation and dynamic release of resources on YARN and Mesos schedulers for better resource utilization, failure recovery, and also dynamic scaling. Moreover, deployments on container management infrastructures like Kubernetes have been simplified and all requests to the JobManager now happen through REST. This includes job submission, cancellation, requesting job status, taking a savepoint, and so on.
The work also builds the foundation for future improvements of Flink’s integration with Kubernetes. In a later version it will be possible to dockerize jobs and deploy them in a natural way as part of the container deployment, i.e., without starting a Flink cluster first. In addition, the work is a big step towards support for applications that are able to automatically adjust their parallelism.
Note that Flink’s programming APIs are not affected by these improvements.
Broadcast State
Support for broadcast state, i.e., state that is replicated across all parallel instances of a function, has been an frequently requested feature. Typical use cases for broadcast state involve two streams, a control or configuration stream that serves rules, patterns, or other configuration messages and a regular data stream. The processing of the regular stream is configured by the messages of the control stream. By broadcasting rules or patterns to all parallel instances of a function, they can be applied to all events of the regular stream.
Of course, broadcasted state can checkpointed and restored just like any other state in Flink with exactly-once state consistency guarantees. Moreover, broadcast state unblocks the implementation of the “dynamic patterns” feature for Flink’s CEP library.
Improvements to Flink’s Network Stack
The performance of a distributed streaming application heavily depends on the component that transfers events from one operator to another via a network connection. In the context of stream processing, two performance metrics, latency and throughput, are important.
For Flink 1.5, the community worked on two efforts to improve Flink’s network stack, credit-based flow control and improving the transfer latency. Credit-based flow control reduces the amount of data “on the wire” to a minimum while preserving high throughput. This significantly reduces the time to complete a checkpoint in back pressure situations. Moreover, Flink is now able to achieve much lower latencies without a reduction in throughput.
Task-Local State Recovery
Flink’s checkpointing mechanism writes copies of an application’s state to a remote, persistent storage and loads it back in case of a failure. This mechanism ensures that state is not lost when an application fails. However, in case of a failure, it might take a while to load the state from the remote storage to recover the application.
Improving the checkpointing and recovery efficiency is an ongoing effort in the Flink community. Prominent features of previous releases were asynchronous and incremental checkpointing. In this release, we improved the efficiency of failure recovery.
Task-local state recovery leverages the fact that a job typically fails due to a single crashed operator, TaskManager, or machine. When writing the state of operators to the remote storage, Flink can now also keep a copy on the local disk of each machine. In case of failover, the scheduler tries to reschedule tasks to their previous machine and load the state from the local disk instead of the remote storage, resulting in faster recovery.
Extending Join Support for SQL and Table API
With the 1.5.0 release, Flink adds support for windowed outer equi-joins. Queries like the one shown below allow for joining of tables on bounded time ranges in both event-time and processing-time.
SELECT d.rideId, d.departureTime, a.arrivalTime
FROM Departures d LEFT OUTER JOIN Arrivals a
ON d.rideId = a.rideId
AND a.arrivalTime BETWEEN
d.deptureTime AND d.departureTime + '2' HOURSFor cases where two streaming tables should not be joined within a bounded time interval, Flink SQL also now supports non-windowed inner joins. This enables full-history matching, which is common in many standard SQL statements.
SELECT u.name, u.address, o.productId, o.amount
FROM Users u JOIN Orders o
ON u.userId = o.userIdSQL CLI Client
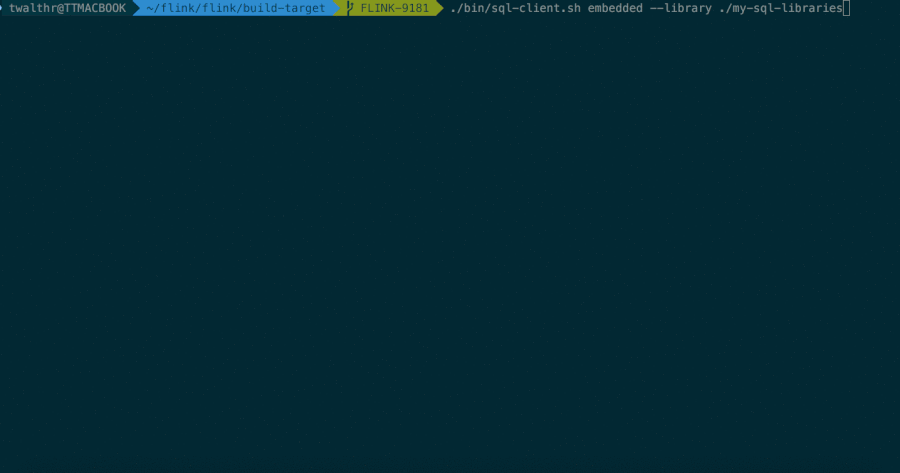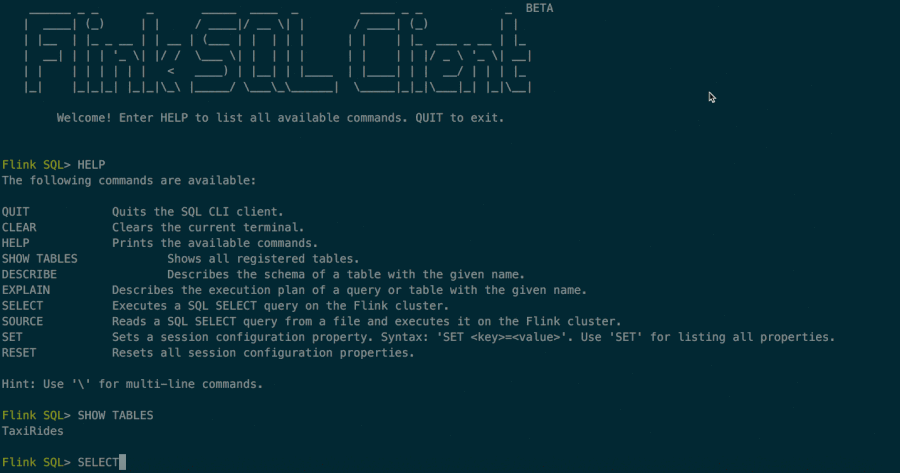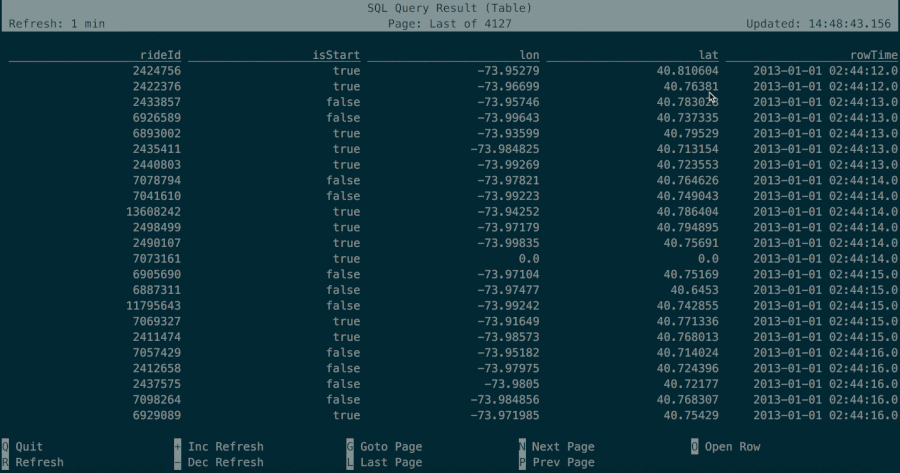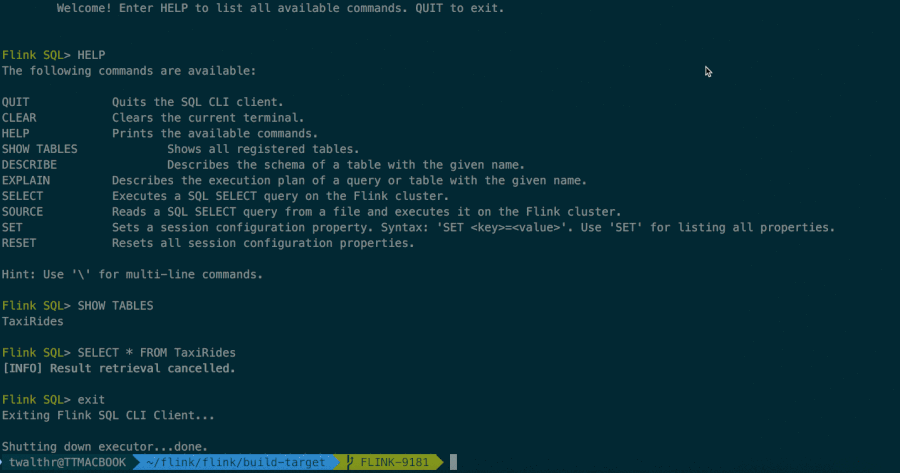
A few months ago, the community started an effort to add a service to execute streaming and batch SQL queries (FLIP-24). The new SQL CLI client is the first step of this effort and provides a SQL shell to run exploratory queries on data streams. The animation below shows a preview of this features.
Various Other Features and Improvements
- OpenStack provides software for creating public and private clouds on pools of resources. Flink now supports OpenStack’s S3-like file system, Swift, for checkpoint and savepoint storage. Swift can be used without Hadoop dependencies.
- Reading and writing JSON messages from and to connectors has been improved. It’s now possible to parse a standard JSON schema in order to configure serializers and deserializers. The SQL CLI Client is able to read JSON records from Kafka.
- Applications can be rescaled without manually triggering a savepoint. Under the hood, Flink will still take a savepoint, stop the application, and rescale it to the new parallelism.
- Improved metrics for watermarks and latency. Flink now reports the minimum watermark in all operators, including sources. Moreover, the latency metrics were reworked for better integration with common metrics systems.
- The
FileInputFormat(and many derived input formats) now supports reading files from multiple paths. - The
BucketingSinksupports the specification of custom extensions for multiple parts. - The
CassandraOutputFormatcan be used to emitRowobjects. - The Kinesis consumer allows for more customization.
Release Notes
Please review the release notes if you plan to upgrade your Flink setup to Flink 1.5.
List of Contributors
According to git shortlog, the following 106 people contributed to the 1.5.0 release. Thanks to all contributors!
Aegeaner, Alejandro Alcalde, Aljoscha Krettek, Andreas Fink, Andrey Zagrebin, Ankit Parashar, Arunan Sugunakumar, Bartłomiej Tartanus, Bowen Li, Cristian, Dan Kelley, David Anderson, Dawid Wysakowicz, Dian Fu, Dmitrii_Kniazev, Dyana Rose, EAlexRojas, Eron Wright, Fabian Hueske, Florian Schmidt, Gabor Gevay, Greg Hogan, Gyula Fora, Jark Wu, Jelmer Kuperus, Joerg Schad, John Eismeier, Kailash HD, Ken Geis, Ken Krugler, Kent Murra, Leonid Ishimnikov, Malcolm Taylor, Matrix42, Michael Fong, Michael Gendelman, Moser Thomas W, Nico Kruber, PJ Fanning, Patrick Lucas, Pavel Shvetsov, Phetsarath, Sourigna, Philip Luppens, Piotr Nowojski, Qiu Congxian/klion26, Razvan, Robert Metzger, Rong Rong, Shuyi Chen, Stefan Richter, Stephan Ewen, Stephen Parente, Steven Langbroek, Thomas Weise, Till Rohrmann, Timo Walther, Tony Wei, Tzu-Li (Gordon) Tai, Ufuk Celebi, Vetriselvan1187, Xingcan Cui, Xpray, Yazdan.JS, Zhijiang, Zohar Mizrahi, aria, biao.liub, binlijin, davidxdh, eastcirclek, eskabetxe, gyao, hequn8128, hzyuqi1, ifndef-SleePy, jparkie, juhoautio, kkloudas, maqingxiang-it, maxbelov, mayyamus, mingleiZhang, neoremind, nichuanlei, okumin, shankarganesh1234, shuai.xus, sihuazhou, summerleafs, sunjincheng121, triones.deng, twalthr, uybhatti, vinoyang, wenlong.lwl, yanghua, yew1eb, yuemeng, zentol, zhangminglei, zhouhai02, zjureel, 军长, 金竹, 王振涛, 陈梓立
Apache Flink 1.5.0 Release Announcement的更多相关文章
- 官宣 | Apache Flink 1.12.0 正式发布,流批一体真正统一运行!
官宣 | Apache Flink 1.12.0 正式发布,流批一体真正统一运行! 原创 Apache 博客 [Flink 中文社区](javascript:void(0) 翻译 | 付典 Revie ...
- Apache Flink 1.12.0 正式发布,DataSet API 将被弃用,真正的流批一体
Apache Flink 1.12.0 正式发布 Apache Flink 社区很荣幸地宣布 Flink 1.12.0 版本正式发布!近 300 位贡献者参与了 Flink 1.12.0 的开发,提交 ...
- Apache Flink 1.9.0版本新功能介绍
摘要:Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能.目前,Apache Flink 1.9 ...
- 修改代码150万行!与 Blink 合并后的 Apache Flink 1.9.0 究竟有哪些重大变更?
8月22日,Apache Flink 1.9.0 正式发布,早在今年1月,阿里便宣布将内部过去几年打磨的大数据处理引擎Blink进行开源并向 Apache Flink 贡献代码.当前 Flink 1. ...
- An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)
01 Mar 2018 Piotr Nowojski (@PiotrNowojski) & Mike Winters (@wints) This post is an adaptation o ...
- Apache Flink 1.9重磅发布!首次合并阿里内部版本Blink重要功能
8月22日,Apache Flink 1.9.0 版本正式发布,这也是阿里内部版本 Blink 合并入 Flink 后的首次版本发布.此次版本更新带来的重大功能包括批处理作业的批式恢复,以及 Tabl ...
- Apache Spark 2.3.0 重要特性介绍
文章标题 Introducing Apache Spark 2.3 Apache Spark 2.3 介绍 Now Available on Databricks Runtime 4.0 现在可以在D ...
- 《从0到1学习Flink》—— Apache Flink 介绍
前言 Flink 是一种流式计算框架,为什么我会接触到 Flink 呢?因为我目前在负责的是监控平台的告警部分,负责采集到的监控数据会直接往 kafka 里塞,然后告警这边需要从 kafka topi ...
- Apache Hadoop 3.0.0 Release Notes
http://hadoop.apache.org/docs/r3.0.0/hadoop-project-dist/hadoop-common/release/3.0.0/RELEASENOTES.3. ...
随机推荐
- pwnable.kr 之 passcode write up
先看源码: #include <stdio.h> #include <stdlib.h> void login(){ int passcode1; int passcode2; ...
- 小白菜OJ 1122 公牛母牛配(最大二分图匹配模板)
题意: n只公牛和m只母牛,某些公牛和某些母牛互相喜欢.但最后一只公牛只能和一只母牛建立一对一匹配.要使得最后牛群匹配对数最大. 链接: http://caioj.cn/problem.php?id= ...
- POJ 1236 Network of Schools (强连通分量缩点求度数)
题意: 求一个有向图中: (1)要选几个点才能把的点走遍 (2)要添加多少条边使得整个图强联通 分析: 对于问题1, 我们只要求出缩点后的图有多少个入度为0的scc就好, 因为有入度的scc可以从其他 ...
- UI进阶 XML解析适配 'libxml/tree.h'file not found 错误解决办法
Xcode 'libxml/tree.h'file not found 错误解决办法
- luogu3302 [SDOI2013]森林
前置技能:Count on a tree 然后带上一个启发式合并 #include <algorithm> #include <iostream> #include <c ...
- linux 在当前目录下查找一个,或者多个文件
1.find ./ -name "y*" 查找以y开头的文件. find ./ -name "*sql*" 查找包含 sql 的文件名 2.查找redis su ...
- 大数据学习——Linux-SSH报错:Could not resolve hostname centos02: Temporary failure in name resolution
https://blog.csdn.net/mcb520wf/article/details/83303792 随笔异常 ssh: Could not resolve hostname centos0 ...
- ssm依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/20 ...
- Light OJ-1082 - Array Queries,线段树区间查询最大值,哈哈,水过~~
...
- C# easyui json类
using System; using System.Data; using System.Text; namespace Common { public class JsonHelp { priva ...