Python基础篇【第3篇】: Python正则表达式
正则表达式
正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
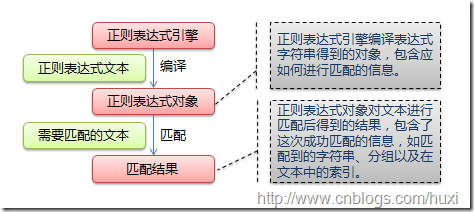
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
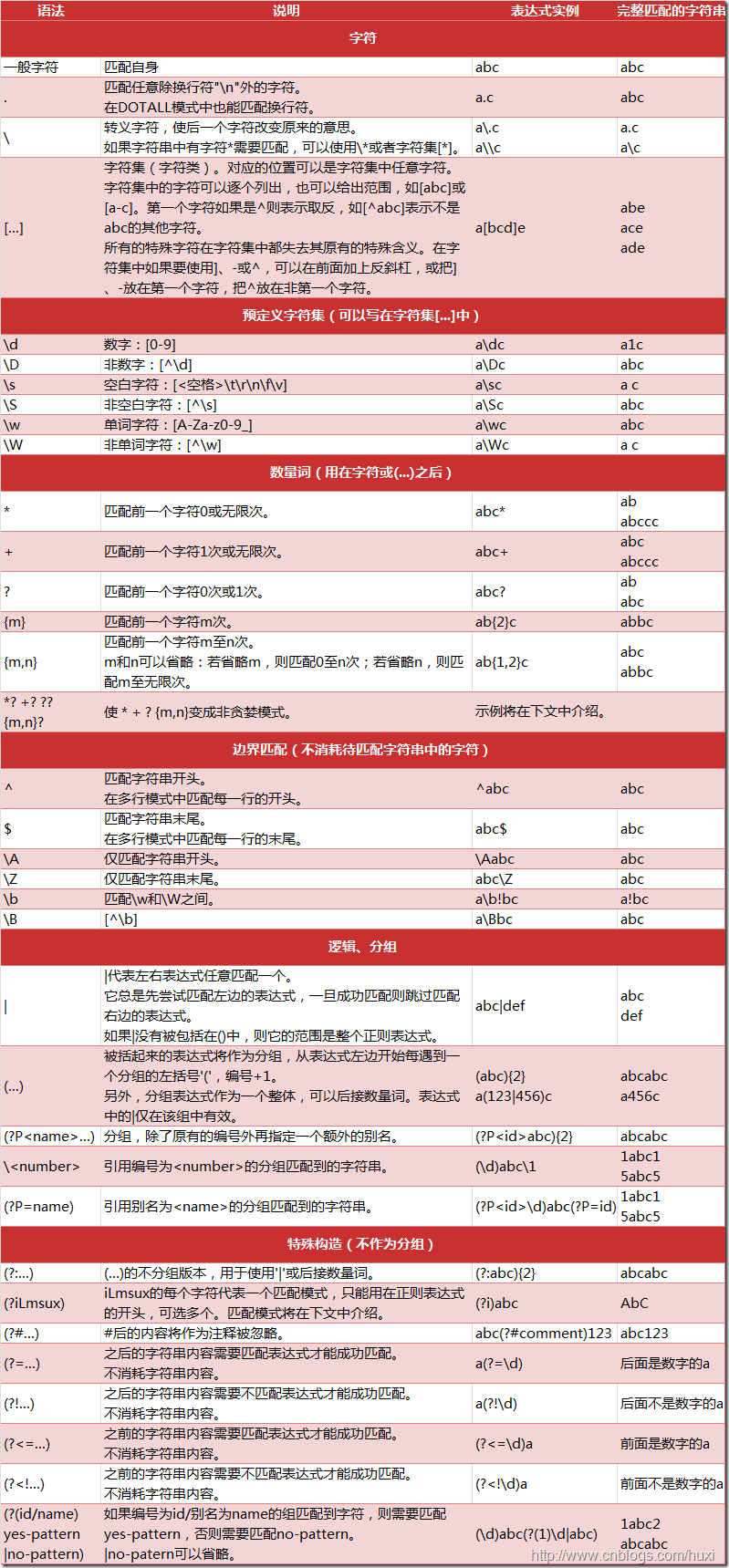
本章节主要介绍Python中常用的正则表达式处理函数。
正则表达式是一种用来匹配字符串的强有力的武器。它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是:
先将正则表达式的字符串形式编译为Pattern实例,
然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),
最后使用Match实例获得信息,进行其他的操作。
# encoding: UTF-8
import re # 将正则表达式编译成Pattern对象
pattern = re.compile(r'hello') # 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
match = pattern.match('hello world!') if match:
# 使用Match获得分组信息
print match.group() ### 输出 ###
# hello
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
- re.I (re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- re.M (MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
- re.S (DOTALL): 点任意匹配模式,改变'.'的行为
- re.L (LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
- re.U (UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
- re.X (VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
re.match(pattern,string,flags=0)
re.match从字符串的起始位置匹配一个模式,如果匹配成功,返回一个Match对象,如果不是起始位置匹配成功的话,match()就返回none。
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
- string: 匹配时使用的文本。
- re: 匹配时使用的Pattern对象。
- pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
- lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
- group([group1, …]): 获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回,(就是正则表达式中如果有(),表示一个匹配模块组,如果有多个(),就可以使用它的序号进行指定输出)。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串,就是没有(),即不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
- groups([default]):以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
- groupdict([default]): 返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
- start([group]):返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
- end([group]): 返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
- span([group]): 返回(start(group), end(group))。
- expand(template):将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
举例1
import re
m = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!') print "m.string:", m.string
print "m.re:", m.re
print "m.pos:", m.pos
print "m.endpos:", m.endpos
print "m.lastindex:", m.lastindex
print "m.lastgroup:", m.lastgroup print "m.group(1,2):", m.group(1, 2)
print "m.groups():", m.groups()
print "m.groupdict():", m.groupdict()
print "m.start(2):", m.start(2)
print "m.end(2):", m.end(2)
print "m.span(2):", m.span(2)
print r"m.expand(r'\2 \1\3'):", m.expand(r'\2 \1\3') ### output ###
# m.string: hello world!
# m.re: <_sre.SRE_Pattern object at 0x016E1A38>
# m.pos: 0
# m.endpos: 12
# m.lastindex: 3
# m.lastgroup: sign
# m.group(1,2): ('hello', 'world')
# m.groups(): ('hello', 'world', '!')
# m.groupdict(): {'sign': '!'}
# m.start(2): 6
# m.end(2): 11
# m.span(2): (6, 11)
# m.expand(r'\2 \1\3'): world hello!
re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。匹配成功re.search方法返回一个匹配的对象,否则返回None。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
举例:
#!/usr/bin/python
# -*- coding: UTF-8 -*- import re
print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配
结果:
(0, 3)
(11, 14)
举例2
#!/usr/bin/python
import re line = "Cats are smarter than dogs"; searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I) if searchObj:
print "searchObj.group() : ", searchObj.group()
print "searchObj.group(1) : ", searchObj.group(1)
print "searchObj.group(2) : ", searchObj.group(2)
else:
print "Nothing found!!"
结果:
searchObj.group() : Cats are smarter than dogs
searchObj.group(1) : Cats
searchObj.group(2) : smarter
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
实例:
#!/usr/bin/python
import re line = "Cats are smarter than dogs"; matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print "match --> matchObj.group() : ", matchObj.group()
else:
print "No match!!" matchObj = re.search( r'dogs', line, re.M|re.I)
if matchObj:
print "search --> matchObj.group() : ", matchObj.group()
else:
print "No match!!"
结果:
No match!!
search --> matchObj.group() : dogs
findall(pattern, string, flags=0)
上述两中方式均用于匹配单值,即:只能匹配字符串中的一个,如果想要匹配到字符串中所有符合条件的元素,则需要使用 findall。
import re
obj = re.findall('\d+', 'fa123uu888asf')
print obj
finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
import re p = re.compile(r'\d+')
for m in p.finditer('one1two2three3four4'):
print m.group(), ### output ###
# 1 2 3 4
转义字符(r)
由于Python的字符串本身也用\转义,所以要特别注意:
s = 'ABC\\-001' # Python的字符串
# 对应的正则表达式字符串变成:
# 'ABC\-001'
因此我们强烈建议使用Python的r前缀,就不用考虑转义的问题了:
s = r'ABC\-001' # Python的字符串
# 对应的正则表达式字符串不变:
# 'ABC\-001'
先看看如何判断正则表达式是否匹配:
>>> import re
>>> re.match(r'^\d{3}\-\d{3,8}$', '010-12345')
<_sre.SRE_Match object; span=(0, 9), match='010-12345'> #证明了前边写的匹配成功返回对象。
>>> re.match(r'^\d{3}\-\d{3,8}$', '010 12345')
group分组
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组(Group)。比如:
^(\d{3})-(\d{3,8})$分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码:
>>> m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345')
>>> m
<_sre.SRE_Match object; span=(0, 9), match='010-12345'>
>>> m.group(0)
'010-12345'
>>> m.group(1)
''
>>> m.group(2)
''
如果正则表达式中定义了组,就可以在Match对象上用group()方法提取出子串来。
注意到group(0)永远是原始字符串,group(1)、group(2)……表示第1、2、……个子串。提取子串非常有用。
来看一个更凶残的例子:
>>> t = '19:05:30'
>>> m = re.match(r'^(0[0-9]|1[0-9]|2[0-3]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])$', t)
>>> m.groups()
('', '', '')
这个正则表达式可以直接识别合法的时间。但是有些时候,用正则表达式也无法做到完全验证,比如识别日期:
'^(0[1-9]|1[0-2]|[0-9])-(0[1-9]|1[0-9]|2[0-9]|3[0-1]|[0-9])$'
对于'2-30','4-31'这样的非法日期,用正则还是识别不了,或者说写出来非常困难,这时就需要程序配合识别了。
sub替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。相比于str.replace功能更加强大
语法:
re.sub(pattern, repl, string, count=0, flags=0)
pattern匹配模式,repl匹配成,string被匹配的字符串,count匹配次数
>>> re.sub('[abc]', 'o', 'Mark')
>>> 'Mork'
返回的字符串是在字符串中用 RE 最左边不重复的匹配来替换。如果模式没有发现,字符将被没有改变地返回。
可选参数 count 是模式匹配后替换的最大次数;count 必须是非负整数。缺省值是 0 表示替换所有的匹配。
实例:
#!/usr/bin/python
import re phone = "2004-959-559 # This is Phone Number" # Delete Python-style comments
num = re.sub(r'#.*$', "", phone)
print "Phone Num : ", num # Remove anything other than digits
num = re.sub(r'\D', "", phone)
print "Phone Num : ", num
结果
Phone Num : 2004-959-559
Phone Num : 2004959559
正则表达式修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
编译
当我们在Python中使用正则表达式时,re模块内部会干两件事情:
编译正则表达式,如果正则表达式的字符串本身不合法,会报错;
用编译后的正则表达式去匹配字符串。
如果一个正则表达式要重复使用几千次,出于效率的考虑,我们可以预编译该正则表达式,接下来重复使用时就不需要编译这个步骤了,直接匹配:
>>> import re
# 编译:
>>> re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$')
# 使用:
>>> re_telephone.match('010-12345').groups()
('', '')
>>> re_telephone.match('010-8086').groups()
('', '')
编译后生成Regular Expression对象,由于该对象自己包含了正则表达式,所以调用对应的方法时不用给出正则字符串。
split(pattern, string, maxsplit=0, flags=0)
根据指定匹配进行分组,通过正则表达式将字符串分离。如果用括号将正则表达式括起来,那么匹配的字符串也会被列入到list中返回。maxsplit是分离的次数,maxsplit=1分离一次,默认为0,不限制次数。
import re p = re.compile(r'\d+')
print p.split('one1two2three3four4') ### output ###
# ['one', 'two', 'three', 'four', '']
相比于str.split更加强大
一些例子:
IP:
^(25[0-5]|2[0-4]\d|[0-1]?\d?\d)(\.(25[0-5]|2[0-4]\d|[0-1]?\d?\d)){3}$
手机号:
^1[3|4|5|8][0-9]\d{8}$
部分内容参考:http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
Python基础篇【第3篇】: Python正则表达式的更多相关文章
- Python基础之【第一篇】
Python简介: python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语 ...
- Python 基础【第八篇】变量
1.变量定义: 给数据进行命名,数据的名字就叫做变量 2.变量格式: [变量名] = [值] 注:变量名命名需要满足下面两条准则 准则一:标示符开头不能为数字.不能包含空格.特殊字符准则二:标示符不能 ...
- python基础【第四篇】
python第二节 1.while循环 Python 编程中 while 语句用于循环执行程序,即在某条件下,循环执行某段程序,以处理需要重复处理的相同任务.基本形式为: while 条件: 循环体 ...
- (Python基础教程之十三)Python中使用httplib2 – HTTP GET和POST示例
Python基础教程 在SublimeEditor中配置Python环境 Python代码中添加注释 Python中的变量的使用 Python中的数据类型 Python中的关键字 Python字符串操 ...
- Python基础【day01】:python介绍发展史(一)
本节内容 Python介绍 发展史 Python 2 or 3? 一. Python介绍 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏 ...
- 『Python基础』第2节: Python简介及入门
一. Python介绍 Python是一门高级计算机程序设计语言,1989年,荷兰的Guido von Rossum创造了它.Guido是是一个牛人,1982年,他从阿姆斯特丹大学获得了数学和计算机硕 ...
- python基础(2):python的变量和常量
今天看看python的变量和常量:python3 C:\test.py 首先先说一下解释器执行Python的过程: 1. 启动python解释器(内存中) 2. 将C:\test.py内容从硬盘读入内 ...
- Python 基础系列一:初识python
为什么是Python而不是其他语言? C 和 Python.Java.C#等 C语言: 代码编译得到 机器码 ,机器码在处理器上直接执行,每一条指令控制CPU工作. 其他语言: 代码编译得到 字节码 ...
- Python基础【day01】:python 2和3区别(四)
许多Python初学者都会问:我应该学习哪个版本的Python.对于这个问题,我的回答通常是“先选择一个最适合你的Python教程,教程中使用哪个版本的Python,你就用那个版本.等学得差不多了,再 ...
- Python基础入门(9)- Python文件操作
1.文件的读写 1.1.文件的创建与写入 利用内置函数open获取文件对象 文件操作的模式之写入 文件对象的操作方法之写入保存 1 # coding:utf-8 2 3 import os 4 5 c ...
随机推荐
- 从一个数组中提取出第start位到第end位
假设通过数组in来表示一个很大的数(in[0]表示最低bit),提取该数的第start位到第end位(计数起始位为0): #define MAX_BYTE_LEN ( 48 ) int getData ...
- 使用syncthing进行双机文件同步
使用syncthing进行双机文件同步 syncthing是一款开源的文件同步软件,可以 syncthing安装 tar -zxvf syncthing-linux-amd64-v0.12.15.ta ...
- mysqlbinlog 参数及用法说明
mysqlbinlog用法说明 服务器生成的二进制日志文件写成二进制格式.要想检查这些文本格式的文件,应使用mysqlbinlog实用工具.应这样调用mysqlbinlog:shell> mys ...
- 手把手原生js简单轮播图
在团队带人,突然被人问到轮播图如何实现,进入前端领域有一年多了,但很久没自己写过,一直是用大牛写的插件,今天就写个简单的适合入门者学习的小教程.当然,轮播图的实现原理与设计模式有很多种,我这里讲的是用 ...
- JSP代码加固
String id = request.getParameter("id"); String id = id.replace("'","") ...
- python2 与 python3 urllib的互相对应关系
urllib Python2 name Python3 nameurllib.urlopen() Deprecated. See urllib.request.urlopen() which mirr ...
- 启用Servlet 3.0新特性——注解支持
Servlet 3.0版本新增注解支持,可是在实际使用中,添加的注解总是不起作用.经过检查,原来是“web.xml”文件的顶级标签“<web-app/>”中的一个叫做“metadata-c ...
- 原生js发送ajax请求
堕落了一阵子了,今天打开博客,发现连登录的用户名和密码都不记得了.2016年已过半,不能再这么晃荡下去了. 参加了网易微专业-前端攻城狮 培训,目前进行到大作业开发阶段,感觉举步维艰.但是无论如何,不 ...
- 1月11日,HTML学习笔记
<ul> <li>coffee</li> <li>tea</li> <li>mile</li> </ul> ...
- window.onload与$(document).ready()区别
2013-12-08 17:11:34 window.onload一次只能执行一个程序,而$(document).ready()可以按照先后顺序执行多个程序. eg: function one(){ ...