详解APM数据采样与端到端
高驰涛 云智慧首席架构师
据云智慧统计,APM从客户端采集的性能数据可能占到业务数据的50%,而企业要做到从Request到Response整个链路中涉及到的所有数据的准确采集,并进行有效串接,进而实现真正的端到端,绝非一件易事。
那么云智慧是如何进行APM数据采样的,又是如何在“端到端”应用性能管理中满足用户对业务数据的高性能分析的呢?在2016年9月全球运维大会的APM专场上,云智慧首席架构师高驰涛先生为你揭晓APM背后的大数据奥秘。
高驰涛(Neeke Gao),云智慧首席架构师,PHP/PECL开发组成员,同时也是PECL/SeasLog,PECL/JsonNet,GoCrab等多项开源软件作者。10年+研发管理经验,早期从事大规模企业信息化架构研发,09年涉足互联网数字营销领域并深入研究架构与性能优化。2014 年加入云智慧,致力于 APM 产品的架构研发,崇尚敏捷,高效,GettingReal。
以下是高驰涛的精彩分享:
今天是APM专场,相信大家对APM都有一定了解,我就从APM的数据采样与端到端的几个层面进行分享,这也是云智慧近几年在服务和解决客户需求过程中的实践结果。
APM和大数据

在APM使用过程中有一个非常明显的特征,就是可采集的数据量非常大,大到不可想象,看看上面这个机房,谁能准确说出里面每天有多少数据流转,而这只是几台简单的机柜。我们对客户的数据做过统计,在互联网上,APM从客户端采集回来的数据能够占到企业业务数据的50%以上,这就意味着如果采集数据非常详细,很可能会比原始业务数据量还要庞大。假设业务数据带宽是2T,为了支撑APM又要上2T的带宽,支撑业务的服务器可能要三百台,现在要最少再额外增加150台支撑APM,这在数据处理方面是个很大的挑战,对于大多数企业来说,APM并不是企业的核心业务,但是用了非常多的计算与存储资源。这是数据未作采样时的现状。
什么是APM(Application Performance Management),从字面上看就是“应用+性能+管理”,前面两位嘉宾聊的都是APM的范畴,他们聊的核心就是应用性能,注意不是业务而是性能。APM后面还有一个词是管理,就是从业务的角度理解这个性能数据,比如说一个崩溃或者说一个卡顿会影响多少用户,影响的用户会给企业造成多少损失,这就是APM对业务价值方面的体现,也是我们正在努力和实践的方向。
我们为什么要用APM,今天有腾讯的嘉宾,举个在手机上玩CF游戏的例子,一个玩家在玩CF,最近常常因为应用运行卡顿被人打死,即便买了好枪、好装备还是打不过别人,用户必然会投诉,投诉之后客服会根据系统的知识库问一大堆有的没的问题,然后承诺玩家马上安排运维检查系统,最后往往不了了之。在企业业务人员在服务用户的过程中往往缺少一个工具,或者说一个平台来及时、准确的发现用户问题,甚至定位到具体用户,具体SQL和具体关键代码。
APM有两大好处,一个是可以提升工作效率,减少和用户无效沟通的时间;另一个就是及时发现和准确定位问题,因为运行在互联网上的业务系统,往往是用户最先感知到系统故障,如果能在接到用户反馈的第一时间及时发现和解决问题,就会大大降低故障带来的业务损失。举个简单的例子,云智慧有个客户的生产系统故障导致停服两个小时,造成了好几千万的损失,后台运维的解决办法非常简单,把服务切了一下,重新启了一套集群,把业务切过去,现场保留下来了,之后用了一个星期的时间发现其实是内存泄露。他们用一个星期的时间找到了问题,后来在云智慧透视宝的帮助下,直接在测试系统上重现了这个问题,并且在10分钟内准确地定位到了内存泄露的位置,使用APM可以有效地缩短问题的发现时间,并有效解决,避免再次发生类似问题。
为什么说APM是大数据呢?我们知道大数据有着非常明确的4V特征:
一个是数据量大(Volume),我们的一个典型用户,每天在APM系统中产生的数据存储量超过了500G;
一个是种类繁多(Variety),例如目前我们已知的移动端APM指标超过三百多个,维度更多;
一个是高速(Velocity),数据产生的速度和消费的速度都是非常恐怖的;
一个是数据价值(Value),单条数据价低,需要综合大量数据进行多纬度综合分析,以得出数据现状和趋势;
这是大数据的典型特征, APM数据恰好符合。
Apdex的得失
面对这么大的数据量应该怎么做,最直接有效的方式就是采样。为什么要做采样,一个是可以有效降低数据量,从数据价值角度来说我们不希望一条数据漏掉,但当大量数据进来以后,为了描述一天的数据量需要花费几天的时间,这就意味着永远无法准确描述。

怎么处理呢?大家看这个Jmeter的请求散点图,在上面标注密密麻麻的点,一个请求一个点位,根据时间维度和响应时间不停地在画布上面点。这时候很难点到每个准确的点,只是比较客观的描述一个事情,就像是一篇流水账,但是不能描述整个应用,也不能描述这个应用是什么样子。

利用这个散点图可以做出这样的一个二维的柱状图,同一个柱状图上又有面积又有高度又有时间,这样好几个维度交叉起来做一个二维图,右侧是从大量不同维度的数据里把几个指标通过APDEX算法融合成一个Apdex指标。
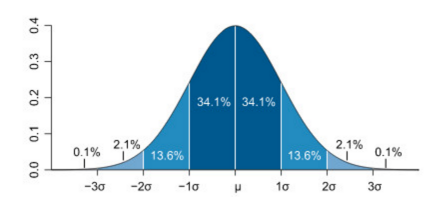
APDEX就是应用性能指标,是APM领域共同遵循的一个规范标准,这个算法不仅限于应用性能领域,在很多我们想要用同一个指标描述大量数据的时候都可以用。我们先看看为什么要用APDEX,左边这张图是高斯分布,也就是正态分布图,可以把一个指标的散点图画到这个地方,形成一张高斯分布图,它的波动曲线上波峰越高说明性能越差,越平缓说明性能越好。但这种描述方式有个明显的缺点,很容易忽略两极,这个图两极是响应速度最快或者最慢的情况,而高斯分布更关注中庸状态,假设非中庸的数据都是异常数据,这就意味着描述的时候其实把看起来非常棒和非常差的状态丢弃了,只留下中庸数据。
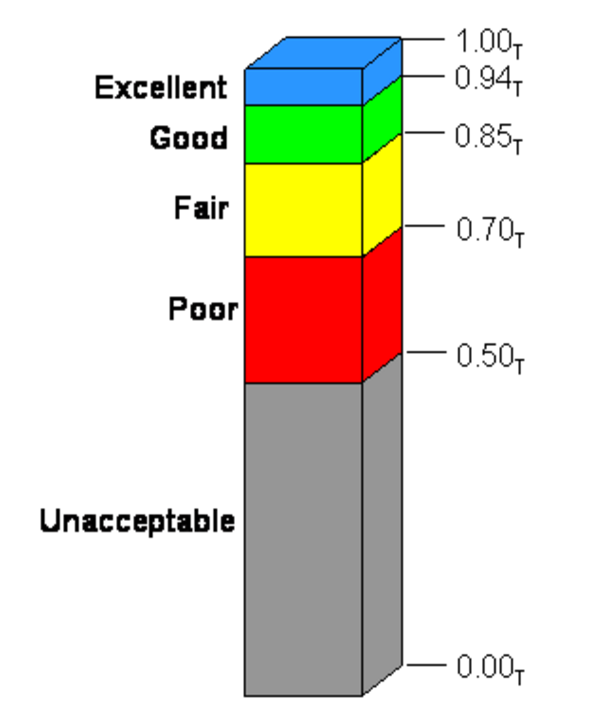
APDEX是对高斯分布的一个改良,这个柱是一个标尺,这个标尺最上面1.00T,T是APDEX的一个单位,APDEX是从0到1描述一项指标,比如计算应用在某一天的平均响应时间,假设一共有四十个请求,平均响应时间是两秒,低于两秒的时候设为一,从零到两秒是十个请求计成一,从两秒到八秒有二十个计成0.5,另外十个大于八秒的计成零,得到APDEX的计算结果是(1×10+0.5×20+0×10)÷40=0.75。用这个方法可以描述应用在一天内的响应时间指标是0.75,把0.75放在这个柱子上看还可接受,如果低于0.5是完全不可接受,可能是有故障。这就是APDEX算法,可以用一个值去描述应用在一段时间内大量采样数据的整体状况。
APDEX有什么问题呢?以血压为例子,比如说高压120是标杆,有40个人进行测量,这40个人像刚才说的,优秀的10个,中庸的20个,血压偏高已经不行的人占了10个,描述40个人的健康状况得出一个还不错的数据0.75。这个时候就有一个非常可怕的问题,用0.75去描述这个人群是没问题的,但是忽略了最后大于四倍标量时候的那部分数据,也就是说那10个快要死的人根本没管他,这是APDEX最大的问题。APDEX的另一个问题是原始数据和端到端的缺失,因为APDEX是通过数据流动过程中直接计算出指标来节省大量存储的,不但原始数据没了,端到端数据也被抛弃了。
再举一个更直接的例子,如果应用系统的数据库连接池出现了问题,此时整个应用接受到的请求在判断连接池出现问题后,可能会快速地抛出一个异常并响应前端一个静态页,此时整个应用响应非常快速,APDEX值也会非常的理想,而整个应用的性能其实是非常非常差的,因为正常的业务全部被中断了。
真正的端到端和APM的采样
真正的端到端是能够串联各个请求从客户端到后面的网络、DB、物理层、外部服务、文件操作的整个链路的数据,数据是不能存在数据孤岛的,如果可以通过一个ID号或者是时间维度把数据进行串接,这才是真正的端到端。
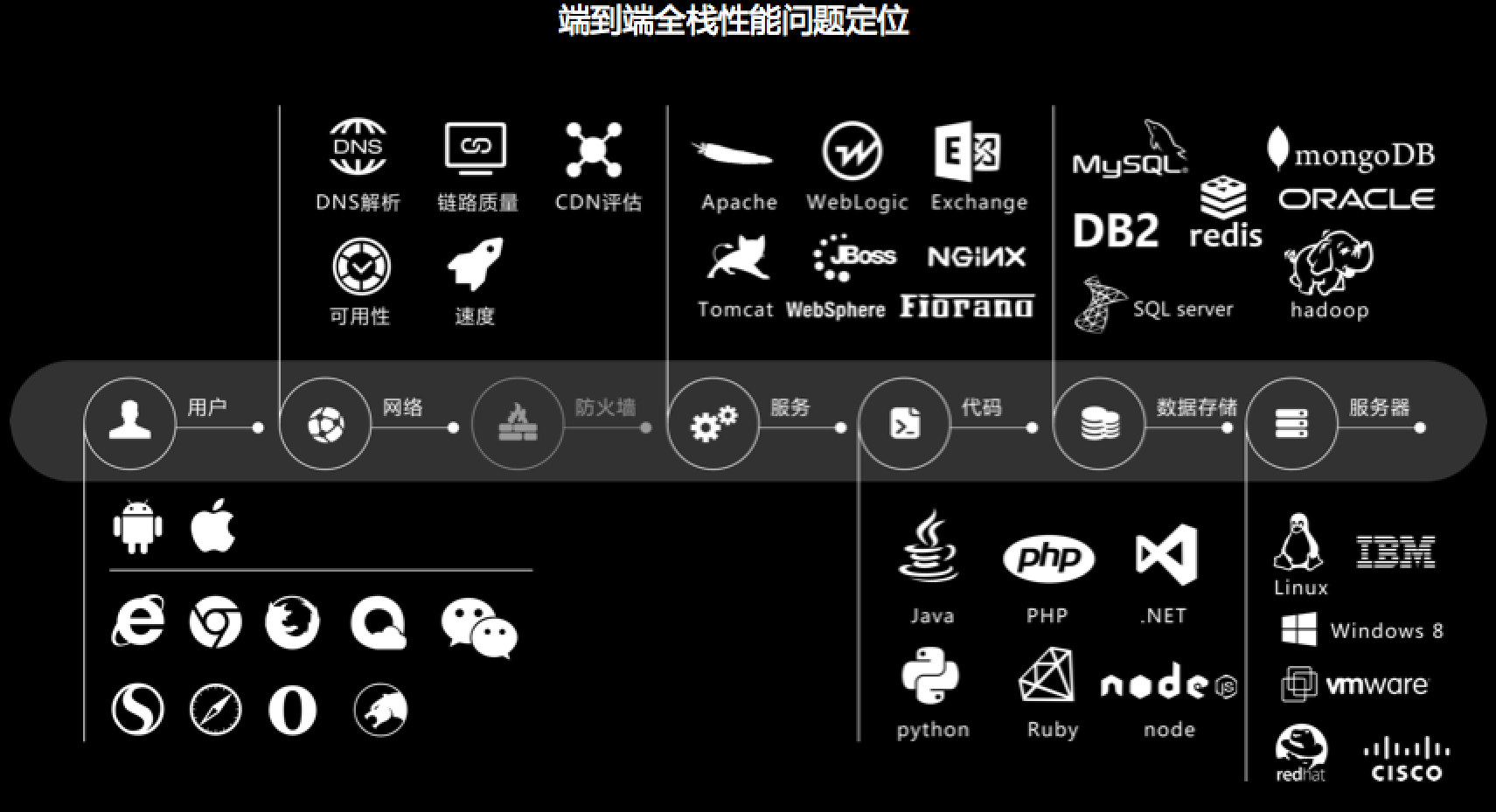
这张图的中间一层就是端到端链路,端到端的实现就是在每个点上的这么多服务、组件上采集数据,,同时由一个惟一标识在各个服务组件上采集的数据中作出传递; 在分析客户端用户行为的同时,还可以通过一个客户端的API调用,直接追踪到API对应后端执行的SQL和执行的代码栈,以及同时刻服务器的CPU/内存/网络/IO等系统状态。其中最大的难题是采样,在使用了APDEX的同时还要实现端到端,这其实就是一个矛盾,既要准确地描述应用的情况,又想降低描述的难度,而且一条数据都不丢,这是一个非常大的挑战。

这个时候有很多做法,这张图是为客户测试解决方案时的一个真实机器负载数据图,TPS降低4%,CPU资源使用率在5%以下。这是怎么做到的呢?我们在数据传输以及数据采集的地方做了大量的工作。比如说系统或接口有问题,问题可能在哪里?根据研发和运维经验很有可能是在进行操作或者有了网络请求,还有一种可能情况是内存和CPU的资源情况,知道这些条件之后,就可以有针对的采集数据,而不是一股脑全部采集。还有就是在不丢数据的前提下,要把一款日PV达到百万级的应用覆盖全,也是一个很大的挑战。
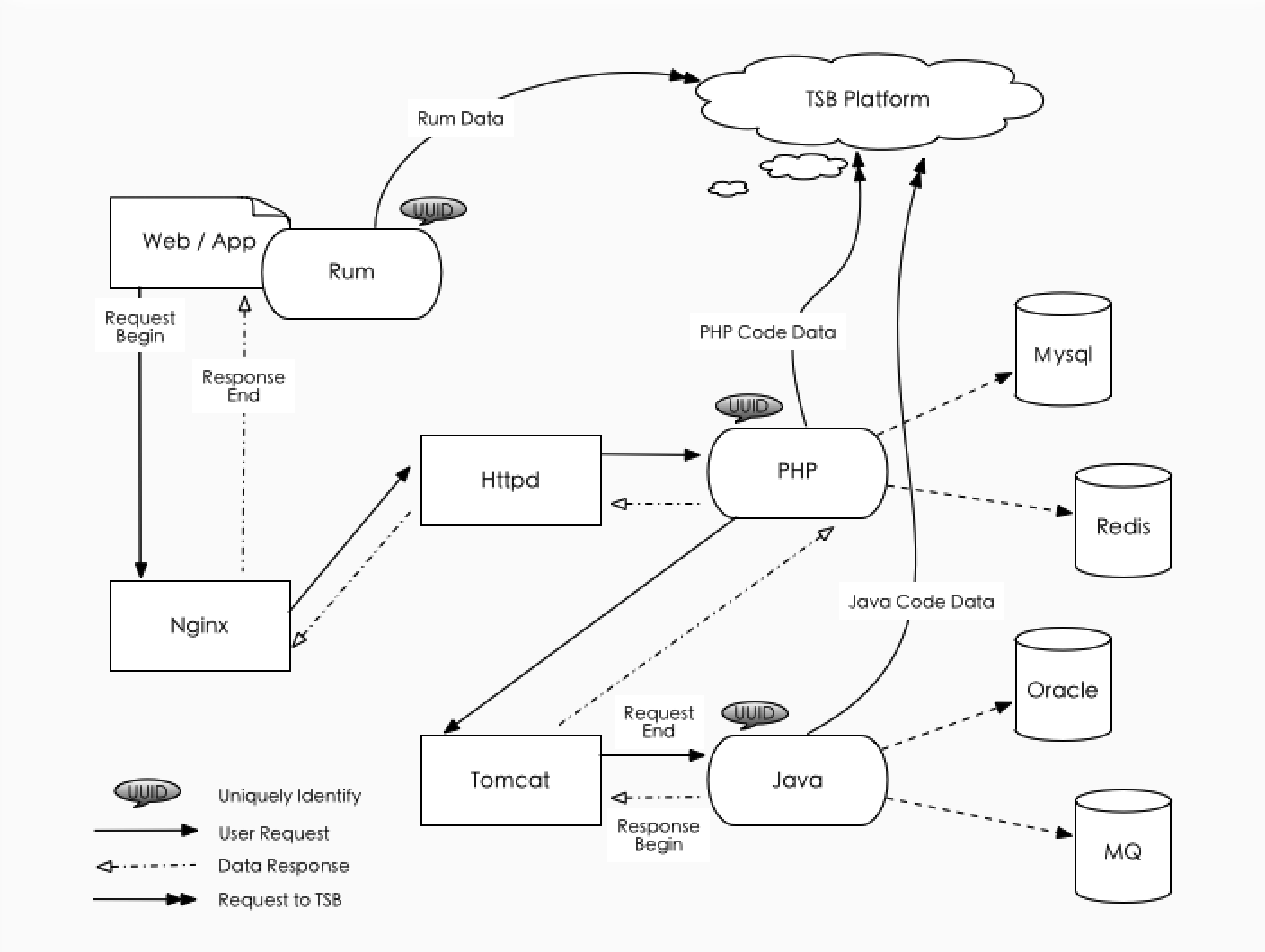
这是云智慧的端到端数据采集原理图,我们的目标是全量采集,同时要关注各个响应阈值,时间的响应阈值、CPU和内存响应阈值,还有错误和异常。为什么说是错误和异常?因为通常意义上的APDEX是对响应时间这个指标进行计算,做规定的描述。

比如说通过一个接口或者通过一个页面访问一条新闻,发一个请求,获取一篇文章,如果响应时间一百毫秒之内非常棒,但很有可能响应时间一百毫秒的时候要连接一次,连接一次之后要再写一次缓存或者写一个点击量什么的操作,这个时候返回这是一个正常的业务,但是很有可能没有连上,产生了错误或者异常,而响应时间是90毫秒,我们能说这个90毫秒的响应请求比一百毫秒更好吗?所以单纯用响应时间这个指标去衡量性能是有问题的,我们应该在关注响应时间指标的同时关注异常指标,而异常指标比正常指标更重要,在进行APDEX衡量的时候一定要进行异常指标的关注。


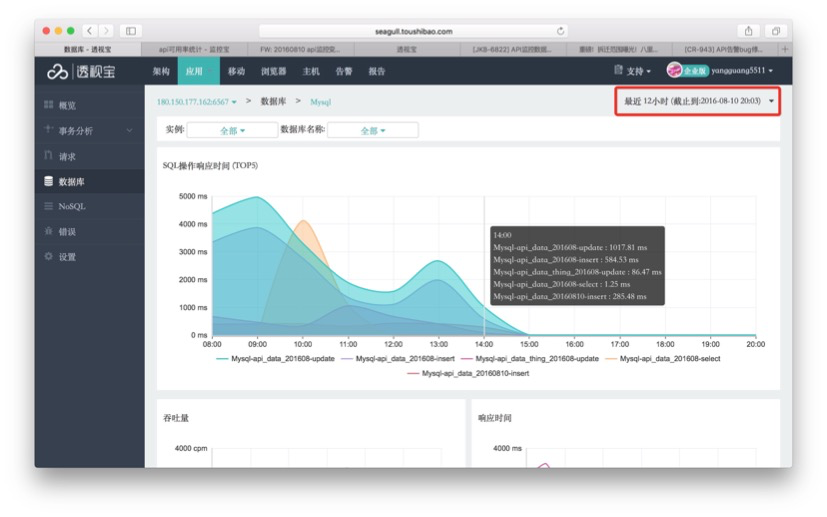
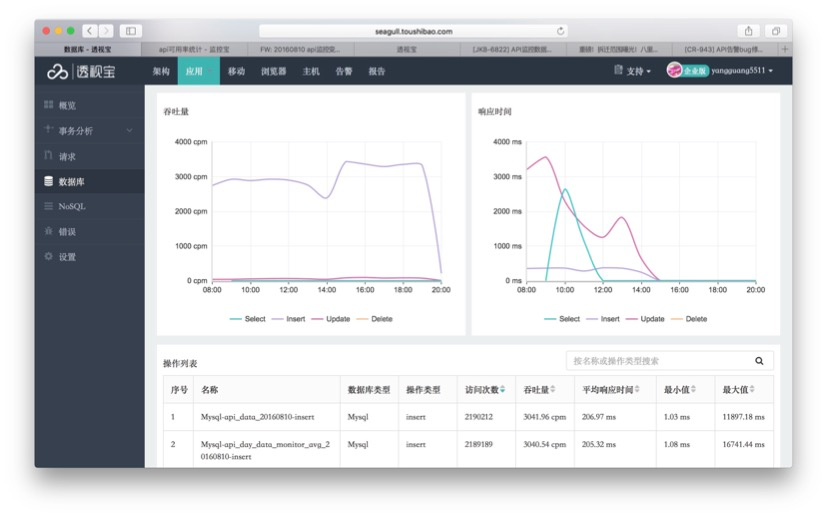
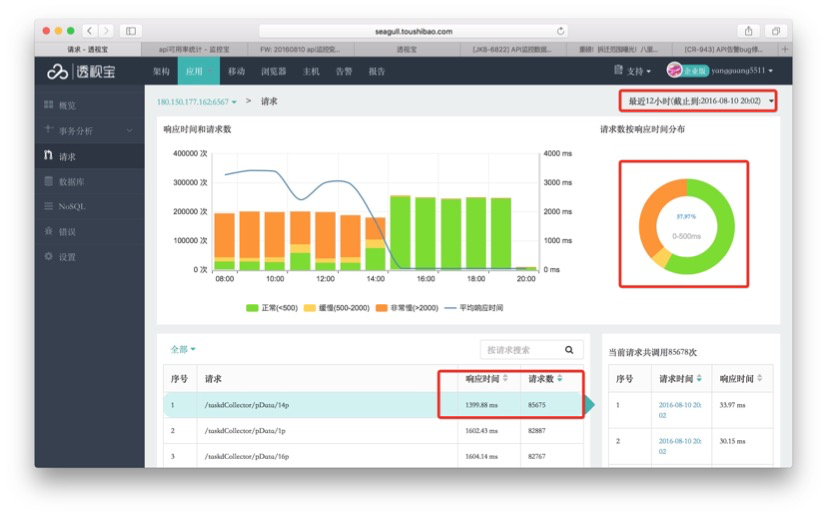
最后举个APM应用实例,这是监控宝在使用前和使用后的对比,右上角是响应时间占比,下面有访问时间等等,大家可以看到右上角黄色部分就是缓慢响应,其实会发现应用有很多问题,缓慢数量大于了90%左右,这是错误和异常的指标,优化数据满眼都是绿色,查询的响应时间明显降下来了,这就是响应时间和错误相交叉的一个指标表现。通过事务快照还可以查看每个具体请求的代码运行栈/SQL/API请求/请求参数等指标,如果有错误或异常还可以快速地查看错误或异常的详情。
谢谢大家!
Q:我想问一下APDEX是APM行业内的标准,还是云智慧多年来的经验总结?
高驰涛:APDEX定义是来自于APM这个词,这个词是从APM出现以后才有的,而APDEX也是许多专业分析师提出来的标准。刚才说的四倍标量给定义0.5,大于四倍给零,这个其实没有约定,但是大家一直是这么做的,算一个未成文的约定。
刚才说了关注几个采样,关注响应时间、响应阈值,响应阈值包括访问时间,这是一个关注指标,在采集的时候首先可以确定连接,不管连接有多快、多慢、有没有出错,都必须要采集,因为这是未知的非常关键的操作,关键操作一定要采集。还有对于正常操作,比如说没有发生错误也没有发生异常,CPU和内存正常,这个时候如果响应时间的阈值低于一毫秒的方法我们会抛弃掉。
云智慧所有的设计都要求不让用户改一行代码,无工程侵入;如果要进行编码才能获取数据的话,是完全没有必要使用第三方平台的,开发者自己就可以轻松地实现。云智慧从无到有是必须要冷部署的,从有到暂停或者说从有到卸载是可以热部署的。

云智慧是业务运维解决方案服务商,旗下产品监控宝(www.jiankongbao.com )、透视宝(www.toushibao.com)、压测宝(www.yacebao.com),已累计为电商、移动互联网、广告传媒、在线游戏、教育医疗、金融证券、政企等行业的几十万用户提供了一站式的应用性能监控、管理及测试服务。
详解APM数据采样与端到端的更多相关文章
- 十图详解tensorflow数据读取机制(附代码)转知乎
十图详解tensorflow数据读取机制(附代码) - 何之源的文章 - 知乎 https://zhuanlan.zhihu.com/p/27238630
- 百度大脑UNIT3.0详解之数据生产工具DataKit
在智能对话项目搭建的过程中,高效筛选.处理对话日志并将其转化为新的训练数据,是对话系统效果持续提升的重要环节,也是当前开发者面临的难题之一.为此百度大脑UNIT推出学习反馈闭环机制,提供数据获取.辅助 ...
- 不看就亏了:DELL EqualLogic PS6100详解及数据恢办法
DELL EqualLogic PS6100采用虚拟ISCSI SAN阵列,为远程或分支办公室.部门和中小企业存储部署带来企业级功能.智能化.自动化和可靠性,支持VMware.Solaris.Linu ...
- 详解Tensorflow数据读取有三种方式(next_batch)
转自:https://blog.csdn.net/lujiandong1/article/details/53376802 Tensorflow数据读取有三种方式: Preloaded data: 预 ...
- 详解 ZooKeeper 数据持久化
本文作者:HelloGitHub-老荀 Hi,这里是 HelloGitHub 推出的 HelloZooKeeper 系列,免费开源.有趣.入门级的 ZooKeeper 教程,面向有编程基础的新手. 项 ...
- MongoDB副本集配置系列十:MongoDB local库详解和数据同步原理
1:local库是MongoDB的系统库,记录着时间戳和索引和复制集等信息 gechongrepl:PRIMARY> use local switched to db local gechong ...
- tensorflow 1.0 学习:十图详解tensorflow数据读取机制
本文转自:https://zhuanlan.zhihu.com/p/27238630 在学习tensorflow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找 ...
- 详解Android数据存储技术
前言 学习Android相关知识,数据存储是其中的重点之一,如果不了解数据,那么让你跟一款没有数据的应用玩,你能玩多久呢?答案是这和没有手机几乎是差不多的.我们聊QQ,聊微信,看新闻,刷朋友圈等都是看 ...
- 详解MySQL数据表类型
学习Mysql数据库,Mysql表类型都有哪些是一定需要知道的,下面就为您介绍七种Mysql表类型,希望能对您学习Mysql表类型有所帮助. MySQL作为当前最为流行的免费数据库服务引擎,已经风靡了 ...
随机推荐
- Centos 6.5 SNMP客户端安装及配置版本net-snmp-5.7.3
Centos 6.5 SNMP客户端安装及配置SNMP版本:net-snmp-5.7.3.tar.gz1.下载软件cd /usr/local/srcyum -y install gccwget htt ...
- javascript_this的用法
javascript : this的用法 1.this代表全局对象 2.作为函数对象的公共方法(new对象后,可以调用带this关键字的属性) 总结:如果在javascript语言里没有通过new(包 ...
- ionic 里使用 iframe 可能遇到的问题
无法访问外部url的问题--两个步骤解决: iframe的src属性用ng-src属性替代,并指明绑定对象: ng-src="{{targetUrl}}" 在controller里 ...
- 关于计算机的ID和用户ID之间的关系
关于计算机的ID和用户ID之间的关系 计算机安装完系统后就会生成计算机ID,然后系统会以计算机ID为前缀附加数字创建Administrator(500)和Guest(501)用户ID,其他用户的ID将 ...
- C# 打开指定目录并定位到文件
private void OpenFolderAndSelectFile(String fileFullName) { System.Diagnostics.ProcessStartInfo psi ...
- CSS + DIV 让页脚始终底部
一 前言 经常设计页面时用到三层DIV,头DIV与脚DIV一般固定高度,而中间层DIV根据内容的多少,高度不定,我们经常希望但内容很少时,脚DIV保持在底部,当内容很多时,脚DIV被中间内容挤到下面, ...
- 大冰--寻人启事--one
看得懂的,都不是命运,说得清的,都不叫爱情. 忘得了的,都不是遗憾,听得见的,都不是伤心. 躲的开的,都不是缘分,猜得透的,都不叫人生.
- mysql 连接空闲超8小时自动断开连接问题(linux)
在mysql配置文件里添加wait_timeout和interactive_timeout两个值 [mysqld] wait_timeout= interactive_timeout= 超时时间,10 ...
- HTML5 File详解
input file控件限制上传文件类型 Html5 FileReader 对文件进行Base64编码 FileReader.readAsDataURL
- Samba日志分析
Samba日志分析 随着我们文件共享安全级别的提高,越来越多的情况下需要对日志进行记录并审计.Linux平台下的Samba服务的配置文件是smb.conf,有不少图形化配置工具例如Webmin.smb ...