[内核笔记1]内核文件结构与缓存——inode和对应描述
由来:公司内部外网记录日志的方式现在都是通过Nginx模块收到数据发送到系统消息队列,然后由另外一个进程来从消息队列读取然后写回磁盘这样的操作,尽量的减少Nginx的阻塞。
但是由于System/V消息队列在使用前需要规定消息长度,且结构不一样需要重新定义消息格式等等...所以在增加需求的时候需要修改代码并重新编译,这样带来的坏处可想而知,外网服务器也会因此重启。
所以组内有同事准备在Nginx中加入异步写日志的功能,大致方式就是将数据写入到一块内存然后由另外一个进程读取然后flush到磁盘,或者直接使用同步写的方式。然后测试对比后发现其实同步写和异步写差别很小。
而且最大的疑惑就是,Nginx的多进程写在没有应用层加锁的情况下是写到同一个日志文件的,到底是应该把日志写到同一个文件下还是按照进程PID来分割日志呢。如果应用层不加锁会导致文件写混乱吗?
好了,说了那么多屁话,其实今天讨论的主题和这个功能需求没多大关系。
不过也是因为这个勾起了我研究内核中文件缓存的欲望。
下面通过这几天的资料收集,简单的介绍一下在系统调用read/write调用的时候底层到底发生了什么等等...
由于主题是文件和文件系统,那么首先第一个要了解的是什么是文件。
一 、文件的描述
文件其实是一种对磁盘中存储的一堆零散的数据的一种描述,在Linux上,一个文件由一个inode 表示。inode在系统管理员看来是每一个文件的唯一标识,在系统里面,inode是一个结构,存储了关于这个文件的大部分信息。
命令 stat [file]可以看到某个文件的信息

inode号就是这个文件的唯一标识,可以看做是数据库中的主键。一个inode 一般占了128KB或者是256KB,是的,有可能比文件本身还大。
inode中存储了一个文件的以下信息:
1.文件大小
2.文件的存储位置
3.用户的GID, UID
4.文件的访问权限
5.时间戳
6.硬链接数()
将inode直观的展现出来,然后根据inode来讲解整个文件系统就显得很容易理解了。
不同于数据库的自增主键,inode号在系统中是会用完的,查看系统的inode整体信息可以用命令
df -i
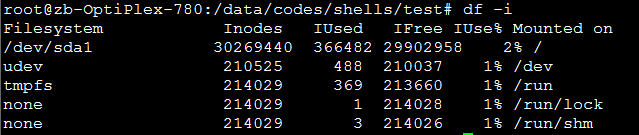
是的,如果你的系统中零散的小文件很多,是会浪费掉很多的inode的,有可能导致的情况就是磁盘任然有空间但是创建文件缺失败了。
如果为一个文件创建了一个硬链接,就是将不同的文件名指向了相同的inode,跟文件路径无关,因为inode没有存储文件路径。
系统在发现一个文件的Links == 0 的时候就会删除对应的文件。
以上是属于系统管理员的,如果你不止想了解这些,请往下看。
inode就是一个文件的一部分描述,不是全部,在内核中,inode对应了这样一个实际存在的结构。
struct inode {
struct hlist_node i_hash; /* 哈希表 */
struct list_head i_list; /* 索引节点链表 */
struct list_head i_dentry; /* 目录项链表 */
unsigned long i_ino; /* 节点号 */
atomic_t i_count; /* 引用记数 */
umode_t i_mode; /* 访问权限控制 */
unsigned int i_nlink; /* 硬链接数 */
uid_t i_uid; /* 使用者id */
gid_t i_gid; /* 使用者id组 */
kdev_t i_rdev; /* 实设备标识符 */
loff_t i_size; /* 以字节为单位的文件大小 */
struct timespec i_atime; /* 最后访问时间 */
struct timespec i_mtime; /* 最后修改(modify)时间 */
struct timespec i_ctime; /* 最后改变(change)时间 */
unsigned int i_blkbits; /* 以位为单位的块大小 */
unsigned long i_blksize; /* 以字节为单位的块大小 */
unsigned long i_version; /* 版本号 */
unsigned long i_blocks; /* 文件的块数 */
unsigned short i_bytes; /* 使用的字节数 */
spinlock_t i_lock; /* 自旋锁 */
struct rw_semaphore i_alloc_sem; /* 索引节点信号量 */
struct inode_operations *i_op; /* 索引节点操作表 */
struct file_operations *i_fop; /* 默认的索引节点操作 */
struct super_block *i_sb; /* 相关的超级块 */
struct file_lock *i_flock; /* 文件锁链表 */
struct address_space *i_mapping; /* 相关的地址映射 */
struct address_space i_data; /* 设备地址映射 */
struct dquot *i_dquot[MAXQUOTAS]; /* 节点的磁盘限额 */
struct list_head i_devices; /* 块设备链表 */
struct pipe_inode_info *i_pipe; /* 管道信息 */
struct block_device *i_bdev; /* 块设备驱动 */
unsigned long i_dnotify_mask; /* 目录通知掩码 */
struct dnotify_struct *i_dnotify; /* 目录通知 */
unsigned long i_state; /* 状态标志 */
unsigned long dirtied_when; /* 首次修改时间 */
unsigned int i_flags; /* 文件系统标志 */
unsigned char i_sock; /* 可能是个套接字吧 */
atomic_t i_writecount; /* 写者记数 */
void *i_security; /* 安全模块 */
__u32 i_generation; /* 索引节点版本号 */
union {
void *generic_ip; /* 文件特殊信息 */
} u;
};
纵观整个inode的C语言描述,没有发现关于文件名的东西,也就是说文件名不由inode保存,实际上系统是不关心文件名的,对于系统中任何的操作,大部分情况下你都是通过文件名来做的,但系统最终都要通过找到文件对应的inode来操作文件,由inode结构中 *i_op指向的接口来操作。
系统是怎样通过文件名找到inode的?
要想明白这一点,就需要知道在内核中,目录也是一个文件,也有对应的inode,只不过inode中存储文件实际内容的不是文件内容而是一个 dentry(dir entry)结构。
比如说在目录 /data/shells/text.txt中,test/既是一个文件也是一个目录
找到根目录/data/的'data' dentry,根据'data' dentry中的inode找到'shells' dentry和inode,然后递归的查找下去,最终找到test.txt的inode.
文件名就存在于dentry中,路径中的每一级的路径名也算做是其文件名。
在dentry结构中有一个指向父节点的指针,也就是 '../',值得一提的是 '..'是指向上层目录的一个硬链接
inode的基本介绍就算完了,下面会介绍一下每个进程是怎样关联到每个文件的,也就是文件描述符那一块。然后介绍一下多个进程对同一个文件操作的时候并发问题以及写操作过程中缓存结构的管理。

[内核笔记1]内核文件结构与缓存——inode和对应描述的更多相关文章
- Linux内核笔记--网络子系统初探
内核版本:linux-2.6.11 本文对Linux网络子系统的收发包的流程进行一个大致梳理,以流水账的形式记录从应用层write一个socket开始到这些数据被应用层read出来的这个过程中linu ...
- Linux内核笔记--内存管理之用户态进程内存分配
内核版本:linux-2.6.11 Linux在加载一个可执行程序的时候做了种种复杂的工作,内存分配是其中非常重要的一环,作为一个linux程序员必然会想要知道这个过程到底是怎么样的,内核源码会告诉你 ...
- 【转载】linux内核笔记之进程地址空间
原文:linux内核笔记之进程地址空间 进程的地址空间由允许进程使用的全部线性地址组成,在32位系统中为0~3GB,每个进程看到的线性地址集合是不同的. 内核通过线性区的资源(数据结构)来表示线性地址 ...
- 【转载】linux内核笔记之高端内存映射
原文:linux内核笔记之高端内存映射 在32位的系统上,内核使用第3GB~第4GB的线性地址空间,共1GB大小.内核将其中的前896MB与物理内存的0~896MB进行直接映射,即线性映射,将剩余的1 ...
- 对<< ubuntu 12.04编译安装linux-3.6.10内核笔记>>的修正
前题: 在前几个月的时候,写了一篇笔记,说的是kernel compile的事情,当时经验不足,虽说编译过了,但有些地方写的有错误--因为当时的理解是有错误的.今天一一更正,记录如下: 前文笔记链接: ...
- Linux内核笔记:epoll实现原理(一)
一.说明 针对的内核版本为4.4.10. 本文只是我自己看源码的简单笔记,如果想了解epoll的实现,强烈推荐下面的文章: The Implementation of epoll(1) The Imp ...
- Linux内核分析第七周学习笔记——Linux内核如何装载和启动一个可执行程序
Linux内核分析第七周学习笔记--Linux内核如何装载和启动一个可执行程序 zl + 原创作品转载请注明出处 + <Linux内核分析>MOOC课程http://mooc.study. ...
- 巨杉内核笔记 | 会话(Session)
SequoiaDB 巨杉数据库是一款金融级分布式关系型数据库,坚持从零开始打造分布式开源数据库引擎.“内核笔记系列”旨在分享交流 SequoiaDB 巨杉数据库引擎的设计思路和代码解析,帮助社区用户深 ...
- LINUX内核笔记:自旋锁
目录 自旋锁作用与基本使用方法? 在SMP和UP上的不同表现? 自旋锁与上下文 使用spin_lock()后为什么不能睡眠? 强调:锁什么? 参考 1.自旋锁作用与基本使用方法? 与其他锁一样,自 ...
随机推荐
- 移动先行之谁主沉浮? 带着你的Net飞奔吧!
移动系源码:https://github.com/dunitian/Windows10 移动系文档:https://github.com/dunitian/LoTDotNet/tree/master/ ...
- Centos 下 mysql root 密码重置
重置mysql密码的方法有很多,官网也提供了很方便的快捷操作办法,可参考资料 resetting permissions .本文重置密码的具体步骤如下: 一.停止MySQL(如果处于运行状态) #se ...
- [转载]Cookie/Session的机制与安全
Cookie和Session是为了在无状态的HTTP协议之上维护会话状态,使得服务器可以知道当前是和哪个客户在打交道.本文来详细讨论Cookie和Session的实现机制,以及其中涉及的安全问题. 因 ...
- 微软发布VSBT,无需安装Visual Studio即可实现项目编译
安装了Visual Studio的那些使用微软平台的开发者通常能够非常容易地操作自己的项目:打开解决方案,修改内容,设置好所有必须的文件以及配置后编译项目.但是在构建服务器或者持续交付系统等没有安装V ...
- 分布式学习系列【dubbo入门实践】
分布式学习系列[dubbo入门实践] dubbo架构 组成部分:provider,consumer,registry,monitor: provider,consumer注册,订阅类似于消息队列的注册 ...
- Android Studio:Failed to resolve ***
更换电脑后,也更新了所有的SDK的tool,仍然报错:Failed to resolve 各种jar包,出现这种问题主要是因为在Android studio中默认不允许在线更新,修改方法如下:
- Atitit.软件开发的三层结构isv金字塔模型
Atitit.软件开发的三层结构isv金字塔模型 第一层,Implements 层,着重与功能的实现.. 第二次,spec层,理论层,设计规范,接口,等.流程.方法论 顶层,val层,价值观层,原则, ...
- Windows下MySQL无法启动
问题描述: 从网上下了5.7 的MySQL,在bin目录下执行 start mysqld ,弹出个cmd窗口一闪就没了,也看不清是什么报错.mysqld --install安装了服务,也启动不了. ...
- 在树莓派Raspbian下安装支持Hard Float的.NET环境
[题外话] 最近入了个树莓派玩,系统装的官方推荐的Hard Float的Raspbian,由于衍生自Debian,所以Mono什么的非常好装.但是官方源中的Mono在Hard Float的Raspbi ...
- Raspkate - 基于.NET的可运行于树莓派的轻量型Web服务器
最近在业余时间玩玩树莓派,刚开始的时候在树莓派里写一些基于wiringPi库的C语言程序来控制树莓派的GPIO引脚,从而控制LED发光二极管的闪烁,后来觉得,是不是可以使用HTML5+jQuery等流 ...