跟我一起云计算(3)——hbase
hbase
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop 项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
hadoop家族
hadoop家族成员:

Hadoop Common
Hadoop体系最底层的一个模块,为Hadoop各子项目提供各种工具,如:配置文件和日志操作等。
Avro
Avro是doug cutting主持的RPC项目,有点类似Google的protobuf和Facebook的thrift。avro用来做以后hadoop的RPC,使hadoop的RPC模块通信速度更快、数据结构更紧凑。
Chukwa
Chukwa是基于Hadoop的大集群监控系统,由yahoo贡献。
HBase
基于Hadoop Distributed File System,是一个开源的,基于列存储模型的分布式数据库。
HDFS
分布式文件系统
Hive
hive类似CloudBase,也是基于hadoop分布式计算平台上的提供data warehouse的sql功能的一套软件。使得存储在hadoop里面的海量数据的汇总,即席查询简单化。hive提供了一套QL的查询语言,以sql为基础,使用起来很方便。
MapReduce
实现了MapReduce编程框架
Pig
Pig是SQL-like语言,是在MapReduce上构建的一种高级查询语言,把一些运算编译进MapReduce模型的Map和Reduce中,并且用户可以定义自己的功能。Yahoo网格运算部门开发的又一个克隆Google的项目Sawzall。
ZooKeeper
Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
hbase系统架构图
架构如下:

Client
HBase Client使用HBase的RPC机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC
Zookeeper
Zookeeper Quorum中除了存储了-ROOT-表的地址和HMaster的地址,HRegionServer也会把自己以Ephemeral方式注册到 Zookeeper中,使得HMaster可以随时感知到各个HRegionServer的健康状态。此外,Zookeeper也避免了HMaster的单点问题,见下文描述
HMaster
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行,HMaster在功能上主要负责Table和Region的管理工作:
1. 管理用户对Table的增、删、改、查操作
2. 管理HRegionServer的负载均衡,调整Region分布
3. 在Region Split后,负责新Region的分配
4. 在HRegionServer停机后,负责失效HRegionServer 上的Regions迁移
HRegionServer
HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个Region,HRegion中由多个HStore组成。每个HStore对应了Table中的一个Column Family的存储,可以看出每个Column Family其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个Column Family中,这样最高效。
HStore
HStore存储是HBase存储的核心了,其中由两部分组成,一部分是 MemStore,一部分是StoreFiles。MemStore是Sorted Memory Buffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile),当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能。当StoreFiles Compact后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后,会触发Split操作,同时把当前 Region Split成2个Region,父Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer 上,使得原先1个Region的压力得以分流到2个Region上。
HLog
HBase中WAL(Write Ahead Log) 的存储格式,物理上是Hadoop的Sequence File。
在理解了上述 HStore的基本原理后,还必须了解一下HLog的功能,因为上述的HStore在系统正常工作的前提下是没有问题的,但是在分布式系统环境中,无法避免系统出错或者宕机,因此一旦HRegionServer意外退出,MemStore中的内存数据将会丢失,这就需要引入HLog了。每个 HRegionServer中都有一个HLog对象,HLog是一个实现Write Ahead Log的类,在每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中(HLog文件格式见后续),HLog文件定期会滚动出新的,并删除旧的文件(已持久化到StoreFile中的数据)。当HRegionServer意外终止后,HMaster会通过Zookeeper感知到,HMaster首先会处理遗留的 HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应region的目录下,然后再将失效的region重新分配,领取 到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复。
HLog数据存储
HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是“写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。HLog Sequece File的Value是HBase的KeyValue对象,即对应HFile中的KeyValue
HFile数据存储
HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile。
首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。Trailer中有指针指向其他数据块的起始点。
File Info中记录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。
Data Index和Meta Index块记录了每个Data块和Meta块的起始点。
Data Block是HBase I/O的基本单元,为了提高效率,HRegionServer中有基于LRU的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定,大号的Block有利于顺序Scan,小号Block利于随机查询。每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成, Magic内容就是一些随机数字,目的是防止数据损坏。后面会详细介绍每个KeyValue对的内部构造。
HFile里面的每个KeyValue 对就是一个简单的byte数组。但是这个byte数组里面包含了很多项,并且有固定的结构。开始是两个固定长度的数值,分别表示Key的长度和Value 的长度。紧接着是Key,开始是固定长度的数值,表示RowKey的长度,紧接着是RowKey,然后是固定长度的数值,表示Family的长度,然后是 Family,接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete)。Value部分没有这么复杂的结构,就是纯粹的二进制数据了。
hbase的逻辑模型
逻辑模型:

下面分别说说几个关键概念:
1)行键(RowKey)
-- 行键是字节数组, 任何字符串都可以作为行键;
-- 表中的行根据行键进行排序,数据按照Row key的字节序(byte order)排序存储;
-- 所有对表的访问都要通过行键 (单个RowKey访问,或RowKey范围访问,或全表扫描)
2)列族(ColumnFamily)
-- CF必须在表定义时给出
-- 每个CF可以有一个或多个列成员(ColumnQualifier),列成员不需要在表定义时给出,新的列族成员可以随后按需、动态加入
-- 数据按CF分开存储,HBase所谓的列式存储就是根据CF分开存储(每个CF对应一个Store),这种设计非常适合于数据分析的情形
3)时间戳(TimeStamp)
-- 每个Cell可能又多个版本,它们之间用时间戳区分
4)单元格(Cell)
-- Cell 由行键,列族:限定符,时间戳唯一决定
-- Cell中的数据是没有类型的,全部以字节码形式存贮
5)区域(Region)
-- HBase自动把表水平(按Row)划分成多个区域(region),每个region会保存一个表里面某段连续的数据;
-- 每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region;
-- 当table中的行不断增多,就会有越来越多的region。这样一张完整的表被保存在多个Region 上。
-- HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元表示不同的HRegion可以分布在不同的HRegionServer上。但一个HRegion不会拆分到多个server上。
hbase存储结构
HBase 是基于列的数据库,让我们看一下关系型数据库和hbase数据库存储的对比。
行式存储和列式存储对比:
行式存储

- 数据是按行存储的
- 没有索引的查询使用大量I/O
- 建立索引和物化视图需要花费大量时间和资源
- 面对查询的需求,数据库必须被大量膨胀才能满足性能要求
列式存储

数据按列存储——每一列单独存放
数据即是索引
只访问查涉及的列——大量降低系统IO
每一列由一个线索来处理——查询的并发处理
数据类型一致,数据特征相似——高效压缩
关系型数据库到hbase数据存储的变迁
传统关系型数据库(mysql,oracle)数据存储方式主要如下:
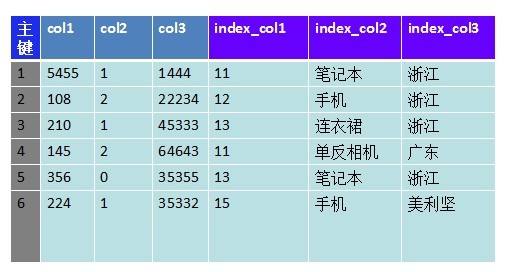
上图是个很典型的数据储存方式,我把每条记录分成3部分:主键、记录属性、索引字段。我们会对索引字段建立索引,达到二级索引的效果。
但是随着业务的发展,查询条件越来越复杂,需要更多的索引字段,且很多值都不存在,如下图:

上图是6个索引字段,实际情况可能是上百个甚至更多,并且还需要根据多个索引字段刷选。查询性能越来越低,甚至无法满足查询要求。关系型数据里的局限也开始显现,于是很多人开始接触NoSQL。
列族数据库很强大,很多人就想把数据从mysql迁到hbase,存储的方式还是跟上图一样,主键为rowkey。其他各个字段的数据,存 储一个列族下的不同列。但是想对索引字段查询就没有办法,目前还没有比较好的基于bigtable的二级索引方案,所以无法对索引字段做查询。
这时候其实可以转换下思维,可以把数据倒过来,如下图:

把各个索引字段的值作为rowkey,然后把记录的主键和属性值按照一定顺序存在对应rowkey的value里。上图只有一个列族,是最简单的方式。 Value里的记录可以设置成定长的byte[],多个记录集合通过移位快速查询到。
但是上面只适合单个索引字段的查询。如果要同时对多个索引字段查询,上图的方式需要求取出所有value值,比如查询“浙江”and“手机”,需要取出两个value,再解析出各自的主键求交。如果每条记录的属性有上百个,对性能影响很大。
接下来的变化是解决多索引字段查询的问题。我们将主键字段和属性字段分开存储,储存在不同的列族下,多索引查询只需要取出列族1下的数据,再去最小集合的列族2里取得想要的值。储存如下图: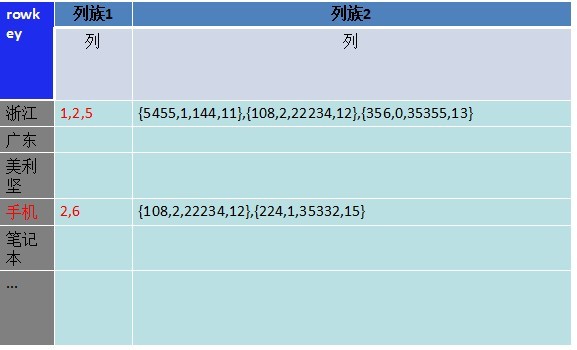
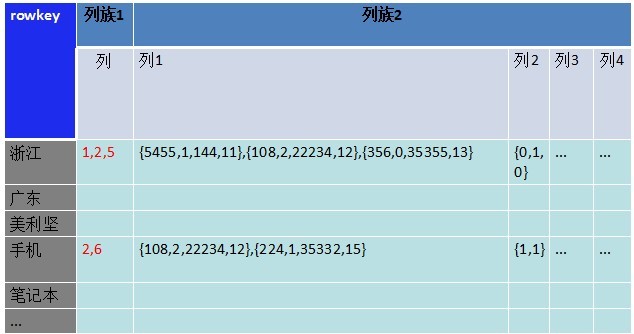
列族数据库数据文件是按照列族分的。在取数据时,都会把一个列族的所有列数据都取出来,事实上我们并不需要把记录明细取出来,所以把这部分数据放到了另一个列族下。
接下来是对列族2扩展,列族2储存更多的列,用来做各种刷选、计算处理。如下图:
hbase的ROOT和META表
相关内容可以参考:
http://greatwqs.iteye.com/blog/1838904
hbase适合
1、高速插入

跟我一起云计算(3)——hbase的更多相关文章
- [转]云计算之hadoop、hive、hue、oozie、sqoop、hbase、zookeeper环境搭建及配置文件
云计算之hadoop.hive.hue.oozie.sqoop.hbase.zookeeper环境搭建及配置文件已经托管到githubhttps://github.com/sxyx2008/clou ...
- 云计算--hbase shell
具体的 HBase Shell 命令如下表 1.1-1 所示: 下面我们将以“一个学生成绩表”的例子来详细介绍常用的 HBase 命令及其使用方法. 这里 grad 对于表来说是一个列,course ...
- 云计算与大数据实验:Hbase shell终端操作之数据操作一
[实验目的] 1)学会向表中添加记录 2)学会添加记录时动态添加列 3)学会查看一条记录 4)学会查看表中的记录总数 5)学会删除记录 [实验原理] Hbase shell作为Hbase数据的客户端, ...
- 云计算与大数据实验:Hbase shell基本命令操作
[实验目的] 1)了解hbase服务 2)学会启动和停止服务 3)学会进入hbase shell环境 [实验原理] HBase是一个分布式的.面向列的开源数据库,它利用Hadoop HDFS作为其文件 ...
- 云计算与大数据实验:Hbase shell操作用户表
[实验目的] 1)了解hbase服务 2)学会hbase shell命令操作用户表 [实验原理] HBase是一个分布式的.面向列的开源数据库,它利用Hadoop HDFS作为其文件存储系统,利用Ha ...
- 云计算与大数据实验:Hbase shell操作成绩表
[实验目的] 1)了解hbase服务 2)学会hbase shell命令操作成绩表 [实验原理] HBase是一个分布式的.面向列的开源数据库,它利用Hadoop HDFS作为其文件存储系统,利用Ha ...
- Hadoop学习笔记—15.HBase框架学习(基础知识篇)
HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列的存储模型,它存储的是 ...
- Hbase集群master.HMasterCommandLine: Master exiting
2016-12-15 17:01:57,473 INFO [main] impl.MetricsSystemImpl: HBase metrics system started 2016-12-15 ...
- 【转】OpenStack和Docker、ServerLess能不能决定云计算胜负吗?
还记得在十多年前,SaaS鼻祖SalesForce喊出的口号『No Software』吗?SalesForce在这个口号声中开创了SaaS行业,并成为当今市值460亿美元的SaaS之王.今天谈谈『No ...
随机推荐
- js跳转到新页面传参以及接收参数的方法
1.传递参数: window.location.href = "./list.html?id="+id; 1.接收参数: (1)接收参数函数封装 function GetReque ...
- Linux cp一个文件夹时提示cp: omitting directory `test/'
将一个文件夹test 复制到地址/opt/tmp下,提示出错: cp: omitting directory `test/' 原因: test 目录下还有目录,不能直接进行拷贝. 我们先找下cp 的命 ...
- myeclipse2014激活
MyEclipse2014破解教程 一. 在破解myeclipse2014之前,要先把环境变量配置好: 1)打开我的电脑--属性--高级--环境变量 2)新建系统变量JAVA_HOME 和CLASSP ...
- 利用FPGA加速实现高性能计算
原文链接 原因:处理器本身无法满足高性能计算(HPC)应用软件的性能需求,导致需求和性能 之间出现了缺口. 最初解决办法:使用协处理器来提升处理器的性能. 协处理器(基于硬件的设计)具有三种能力: 1 ...
- bash: warning: setlocale: LC_ALL: cannot change locale (en_US.UTF-8)
bash: warning: setlocale: LC_ALL: cannot change locale (en_US.UTF-8) Q: hubery@roaster:~$ locale loc ...
- Maven使用第三方jar文件的两种方法
转于http://blog.csdn.net/youhaodeyi/article/details/1729116 主要用于回查与标记 在Maven中,使用第三方库一般是通过pom.xml文件中定义的 ...
- spring事物传播机制与隔离级别
转载自:http://www.blogjava.net/freeman1984/archive/2010/04/28/319595.html7个传播行为,4个隔离级别, Spring事务的传播行为和隔 ...
- 可以编辑R代码的eclipse插件
说到强大的IDE,eclipse肯定是首先会被想到的几个之一,幸运地是,R也能使用它.在http://www.walware.de/goto/statet上有个StatET的插件,专门为R而做,从此R ...
- datax+hadoop2.X兼容性调试
以hdfsreader到hdfswriter为例进行说明: 1.datax的任务配置文件里需要指明使用的hadoop的配置文件,在datax+hadoop1.X的时候,可以直接使用hadoop1.X/ ...
- vb小菜一枚-----了解“类型推理”
局部类型推理 (Visual Basic) Visual Studio 2013 其他版本 Visual Basic 编译器使用类型推理来确定未使用 As 子句声明的局部变量的数据类型. 编译 ...