word2vec + transE 知识表示模型
本文主要工作是将文本方法 (word2vec) 和知识库方法 (transE) 相融合作知识表示,即将外部知识库信息(三元组)加入word2vec语言模型,作为正则项指导词向量的学习,将得到的词向量用于分类任务,效果有一定提升。
一. word2vec 模型
word2vec 是 Google 在 2013 年开源推出的一款将词表征为实数值向量的高效工具,使用的是 Distributed representation (Hinton, 1986) 的词向量表示方式,基本思想是通过训练将每个词映射成 K 维实数向量后,可通过词之间的距离(比如 cosine 相似度、欧氏距离等)来判断它们之间的语义相似度。word2vec 输出的词向量可以被用来做很多 NLP 相关的工作,比如聚类、找同义词、词性分析等。同时 word2vec 还发现有趣的单词类比推理现象,即 V(king) - V(man) + V(woman) ≈ V(queue) 。
word2vec 本质上是一种神经概率语言模型 (Bengio,2003),通过神经网络来训练语言模型,而词向量只是副产品。其中有两个重要模型 —— CBOW 模型 (Continuous Bag-of-Word Model) 和 Skip-gram 模型 (Continuous Skip-gram Model),同时作者给出了两套框架,分别基于 Hierarchical Softmax(hs) 和 Negative Sampling(NEG),本文使用了基于Negative Sampling 的 CBOW 模型,下面进行简单介绍:
基于 Negative Sampling 的 CBOW 模型
CBOW 模型包含三层:输入层,投影层和输出层,在已知当前词 wt 的上下文 wt-2, wt-1, wt+1, wt+2 的前提下预测当前词 wt(见下图)

模型优化的目标函数是如下的对数似然函数,关键就在于  的构建。
的构建。
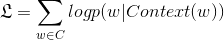
传统神经概率语言模型使用的是 softmax,但 softmax 计算复杂度高,尤其语料词汇量大的时候。
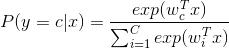
在 word2vec 中,使用 Hierarchical Softmax 和 Negative Sampling 来近似计算,目的是提高训练速度并改善词向量的质量。与 Hierarchical Softmax 相比,NEG不再使用复杂的 Huffman树, 而是采用随机负采样的方法,增大正样本的概率同时降低负样本的概率。
在 CBOW 模型中,已知词 w 的上下文 Context(w),需要预测 w,因此对于给定的 Context(w),词 w 就是一个正样本,其它词就是负样本,对于一个给定的样本(Context(w), w),我们希望最大化

其中,NEG(w) 表示负样本集,正样本标签为 1,负样本标签为0,其概率计算如下
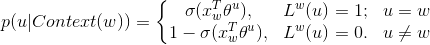
或者写成整体表达式

故优化目标就是最大化 g(w),增大正样本的概率同时降低负样本的概率。对于一个给定的语料库C,函数G就是整体优化的目标,为了计算方便,对G取对数,最终目标函数如下:
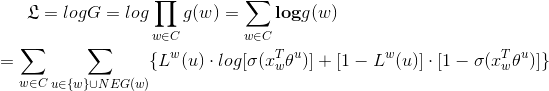
利用随机梯度上升对上式进行求解即可,这里直接给出梯度计算结果,
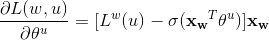 ,
, 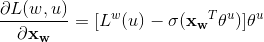
故参数θu更新公式如下:
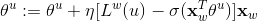
对于 w’ 属于 Context(w) ,即其上下文词向量更新公式如下:
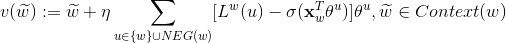
下面以样本 (Context(w), w) 为例,给出基于Negative Sampling 的 CBOW 模型训练过程的伪代码,与 word2vec 源码 相对应关系如下: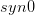 对应
对应 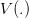 ,
,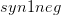 对应
对应 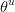 ,
, 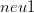 对应
对应  ,
,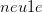 对应
对应  。之后我们结合 transE 模型时,也是根据 word2vec 源码进行改进。
。之后我们结合 transE 模型时,也是根据 word2vec 源码进行改进。

关于word2vec的数学原理以及公式推导过程,强烈推荐@peghoty的博客:word2vec中的数学原理详解
二. transE 模型
TransE 是基于实体和关系的分布式向量表示,由 Bordes 等人于2013年提出,受word2vec启发,利用了词向量的平移不变现象。将每个三元组实例 (head,relation,tail) 中的关系 relation 看做从实体 head 到实体 tail 的翻译,通过不断调整h、r和t (head、relation 和 tail 的向量),使 (h + r) 尽可能与 t 相等,即 h + r ≈ t。该优化目标如下图所示:
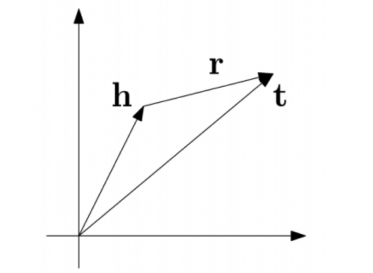
TransE 定义了一个距离函数 d(h + r, t),它用来衡量 h + r 和 t 之间的距离,在实际应用中可以使用 L1 或 L2 范数。在模型的训练过程中,transE采用最大间隔方法,其目标函数如下:

其中,S是知识库中的三元组,S’是负采样的三元组,通过替换 h 或 t 所得。γ 是取值大于0的间隔距离参数,[x]+表示正值函数,即 x > 0时,[x]+ = x;当 x ≤ 0 时,[x]+ = 0 。算法模型比较简单,梯度更新只需计算距离 d(h+r, t) 和 d(h’+r, t’).
模型训练完成后,可得到实体和关系的向量表示,进一步可做关系抽取和知识推理的任务。下面是算法伪代码:

三. word2vec + transE 模型
在我们的模型中,主要利用的是百科词条抽取的 infobox 信息,构成三元组信息 (h, r, t),例如 (百度,董事长,李彦宏),假设信息是事实,一个基本想法就是在训练 word2vec 过程中,加入这些三元组信息,使得关联的 h 和 t 某种程度上更接近,也可以说是一种正则化约束,例如三元组信息是类别信息,即词语属于哪个领域的信息。
为了与 word2vec 模型融合,利用 transE 思想,重新定义 (h+r, t)的目标函数为概率函数(其实就是 softmax):

其中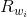 是包含 wi 的所有关系,|V| 是字典的大小。
是包含 wi 的所有关系,|V| 是字典的大小。  是由 wi 和 r 的向量线性相加所得,即
是由 wi 和 r 的向量线性相加所得,即  ,
,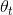 表示词 t 对应的参数。
表示词 t 对应的参数。
这样一来,我们就可以构建基于 word2vec 和 transE 的模型目标函数,如下:
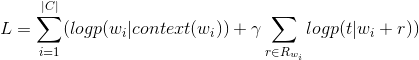
其中,式子左边是基于 CBOW 的 word2vec 模型,右边是关系词向量模型,γ 是平衡两个模型贡献比率的参数,|C|是整个语料库的大小。训练的时候同样采用Negative Sampling 的方法近似计算 softmax。 我们来看下关系词向量模型(右半部分)的求解过程:
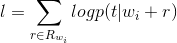 (1)
(1)
在 Negative Sampling 中,三元组同样被分为正样本和负样本,根据Local Closed World假设,不在知识库中的三元组视为负样本,即 (wi, r, t) 成立的时候,对应的 t 为正样本,而其他词语都为负样本,举个例子(百度,董事长,李彦宏)是正样本,(百度,董事长,马云)是负样本。对于给定的一个词 wi 和对应的一个关系 r,训练的目标似然函数如下:
 (2)
(2)
是不是有点眼熟?细心朋友可以发现,这和 word2vec 模型的目标似然函数是相似的,将(2)式代入(1)上述关系词向量模型最终的目标似然函数就是

根据 word2vec 的梯度推导,我们可以得到参数的梯度更新如下:

关系词向量模型的实体 wi 和关系 r 梯度更新如下:
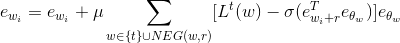 ,
,

模型伪代码如下,与 word2vec_transE 源码(github) 相对应关系如下: 对应 , 对应 , 对应 , 对应 ,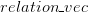 对应
对应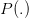 ,
,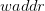 对应
对应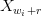

实验过程及结果
实验过程,训练语料源于百度百科摘要数据,高频关系三元组 (h, r, t) 168403条,关系 r 有 1650 种,训练时间 2h (比 word2vec 原始代码训练要耗时是正常的),利用训练后的词向量做分类任务,效果比原始 word2vec 训练词向量高 2%,可见加入外部数据库信息一定程度上能提升词向量的表达能力。
一些问题
(1)语料脏!百度百科数据太脏了,词条排版属性格式不一,信息前期预处理麻烦。
(2)模型实际上是增加约束,依然没法解决一词多义问题
(3)这里加入的信息只是 infobox 抽取的三元组,信息利用率不高,可进一步利用百科链接,分类等信息。
项目地址:github
参考
[1]. Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. (2013). Efficient Estimation of Word Representations in Vector Space. In Proceedings of Workshop at ICLR.
[2]. Bordes, A., Usunier, N., Garcia-Duran, A., Weston, J., & Yakhnenko, O. (2013). Translating embeddings for modeling multi-relational data. In Proceedings of NIPS.
[3]. peghoty的博客:word2vec中的数学原理详解
[4]. 张柏韩:基于知识库的词向量研究与应用
word2vec + transE 知识表示模型的更多相关文章
- 4 关于word2vec的skip-gram模型使用负例采样nce_loss损失函数的源码剖析
tf.nn.nce_loss是word2vec的skip-gram模型的负例采样方式的函数,下面分析其源代码. 1 上下文代码 loss = tf.reduce_mean( tf.nn.nce_los ...
- Word2Vec之Skip-Gram模型
理解 Word2Vec 之 Skip-Gram 模型 模型 Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,从直观上理解,Skip-Gram是给定input word来预测上下文. ...
- 理解 Word2Vec 之 Skip-Gram 模型
理解 Word2Vec 之 Skip-Gram 模型 天雨粟 模型师傅 / 果粉 https://zhuanlan.zhihu.com/p/27234078 508 人赞同了该文章 注明:我发现知乎有 ...
- 漫谈Word2vec之skip-gram模型
https://zhuanlan.zhihu.com/p/30302498 陈运文 复旦大学 计算机应用技术博士 40 人赞同了该文章 [作者] 刘书龙,现任达观数据技术部工程师,兴趣方向主要为自 ...
- Gensim进阶教程:训练word2vec与doc2vec模型
本篇博客是Gensim的进阶教程,主要介绍用于词向量建模的word2vec模型和用于长文本向量建模的doc2vec模型在Gensim中的实现. Word2vec Word2vec并不是一个模型--它其 ...
- 机器学习入门-文本特征-word2vec词向量模型 1.word2vec(进行word2vec映射编码)2.model.wv['sky']输出这个词的向量映射 3.model.wv.index2vec(输出经过映射的词名称)
函数说明: 1. from gensim.model import word2vec 构建模型 word2vec(corpus_token, size=feature_size, min_count ...
- word2vec训练中文模型
-- 这篇文章是一个学习.分析的博客 --- 1.准备数据与预处理 首先需要一份比较大的中文语料数据,可以考虑中文的维基百科(也可以试试搜狗的新闻语料库).中文维基百科的打包文件地址为 https: ...
- word2vec 和 glove 模型的区别
2019-09-09 15:36:13 问题描述:word2vec 和 glove 这两个生成 word embedding 的算法有什么区别. 问题求解: GloVe (global vectors ...
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
随机推荐
- JSON简介
JSON的全称是JavaScript Object Notion,即JavaScript对象符号,它是一种轻量级的数据交换格式,JSON的数据格式既适合人来读/写,也适合计算机本身解析和生成.最早 ...
- iOS_线程和进程的区别与联系
首先是线程和进程的联系: 线程和进程都是由操作系统所负责的程序运行的基本单元,系统利用该基本单元实现对应用的并发性. 接下来就是线程和进程的区别: 线程和进程最大的区别就是它们是操作系统的两种资源管理 ...
- solution to E: failed to fetch .......
There are some issues today for me that my desktop can't boot as I expected, I installed windows 8.1 ...
- C#枚举中的位运算权限分配浅谈
常用的位运算主要有与(&), 或(|)和非(~), 比如: 1 & 0 = 0, 1 | 0 = 1, ~1 = 0 在设计权限时, 我们可以把权限管理操作转换为C#位运算来处理. 第 ...
- SQL Server数据库性能优化之索引篇【转】
http://www.blogjava.net/allen-zhe/archive/2010/07/23/326966.html 性能优化之索引篇 近期项目需要, 做了一段时间的SQL Server性 ...
- MicroERP软件更新记录2.1
最新版本:2.1 更新内容:新增客户关系管理(CRM) 下载地址:http://60.2.39.130/microerp 因部分企业用户或个人(开发者)的实际应用水平或技术开发能力参差不齐,且软件开发 ...
- MSChart绘图控件中折线图和柱形图画法
首先在前台拖入一个名为chart1的MSChart控件 //折线图 string strLegend = "Legend1"; Legend lg = new Legend(str ...
- 2、Runtime Area Data
这个也分为两大部分 1.是线程共享区域 ·线程共享区域又包括两部分Heap(堆)和方法区(Perm) 2.是线程独享区域 这个也包括两大部分程序计数器和栈 栈(又包括两部分:VM 栈和本地方法栈)
- android studio 中依赖库compile 的一些库的地址
1.添加Gson的依赖库 compile 'com.google.code.gson:gson:2.2.4' 2.使用Volley执行网络数据传输的依赖库 compile 'com.mcxiaoke. ...
- java基础之 工具类
一.StringUtils StringUtils.isEmpty(null) && StringUtils.isEmpty(""); // true String ...